Clear Sky Science · pl
scDecorr: uczenie reprezentacji oparte na dekorrelacji cech umożliwia samonadzorowane wyrównywanie wielu eksperymentów pojedynczych komórek
Dlaczego ważne jest łączenie danych pojedynczych komórek
Współczesna biologia potrafi odczytywać aktywność tysięcy genów w pojedynczych komórkach, co ujawnia rzadkie typy komórek i subtelne stany chorobowe. Jednak te eksperymenty często przeprowadza się w różnych laboratoriach, używając różnych maszyn i protokołów, co utrudnia ich łączenie. Artykuł przedstawia scDecorr — nową metodę obliczeniową, która automatycznie dopasowuje takie różnorodne zbiory danych, tak by podobne komórki znalazły się razem, nawet jeśli mierzono je bardzo odmiennymi sposobami. Ułatwia to badaczom budowanie bogatych atlasów komórkowych i ponowne wykorzystanie danych z różnych badań.
Wiele zestawów danych, jeden wspólny język
Sequencjonowanie RNA pojedynczych komórek mierzy, które geny są aktywne w każdej komórce. W teorii pozwala to porównywać komórki między organami, pacjentami czy chorobami. W praktyce jednak techniczne zawiłości — zwane efektami partii — mogą przytłumić prawdziwe różnice biologiczne. Komórki tego samego typu mogą wyglądać inaczej tylko dlatego, że zostały przetworzone innego dnia lub inną technologią. scDecorr radzi sobie z tym, ucząc zwartego numerycznego „profilu” dla każdej komórki, w którym podobnie działające komórki są blisko siebie, a różne pozostają od siebie oddzielone. Co istotne, robi to bez potrzeby korzystania z ręcznie przypisanych etykiet typów komórek, dzięki czemu nadaje się do dużych, zróżnicowanych zbiorów danych.
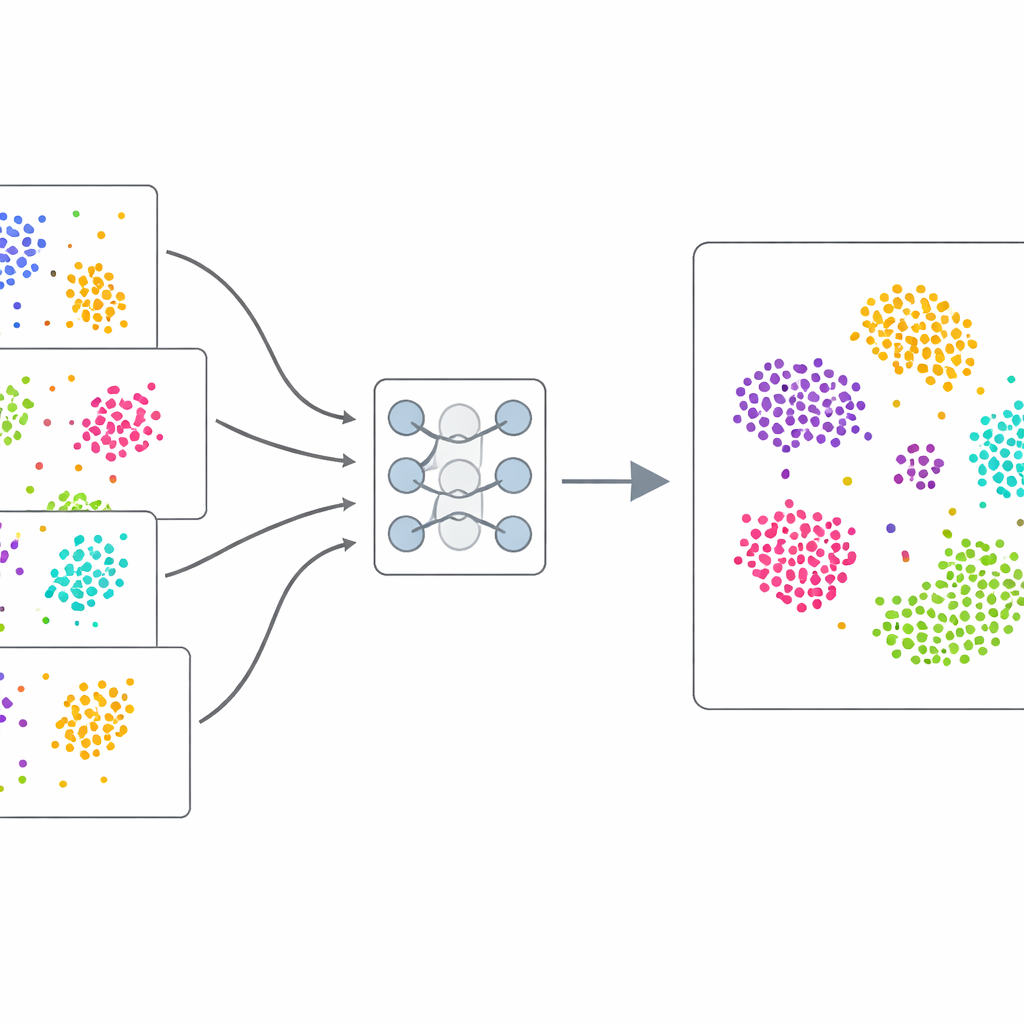
Uczenie się z samych danych
Zamiast polegać na ręcznie oznakowanych przykładach, scDecorr wykorzystuje uczenie samonadzorowane: dane dostarczają własny sygnał treningowy. Dla każdej komórki metoda tworzy dwie nieco zniekształcone kopie jej profilu ekspresji genów, na przykład przez losowe usunięcie lub przetasowanie niektórych wartości. Bliźniacza sieć neuronowa przetwarza obie wersje i jest trenowana tak, by generować bardzo podobne wewnętrzne podsumowania dla dwóch widoków tej samej komórki, a jednocześnie różne podsumowania dla różnych komórek. Równocześnie scDecorr zachęca, by każdy składnik tych podsumowań niósł unikalną informację, tak aby żadne pojedyncze cechy nie dublowały się nawzajem. Ten krok „dekorrelacji” pomaga zapobiec zapaści modelu na kilka dominujących wzorców i zamiast tego uchwycić szeroki wachlarz sygnałów biologicznych.
Ciche korygowanie różnic technicznych
Kluczowym wyzwaniem jest to, że komórki z różnych badań podlegają nieco innym regułom statystycznym. Jeśli połączy się je naiwnie, model może błędnie zinterpretować różnice techniczne jako biologiczne. scDecorr rozwiązuje to przy użyciu pomysłu zapożyczonego z adaptacji domeny. Wszystkie partie (batch'e) współdzielą tę samą sieć enkodera, ale każda partia ma własne warstwy normalizujące, które przeskalowują cechy tak, by w obrębie tej partii każdemu wymiarowi nadano standardowy kształt. Cel dekorrelacji stosowany jest następnie oddzielnie w każdej partii, przy czym wszystkie partie przechodzą przez ten sam enkoder. To delikatnie nakłania enkoder do generowania reprezentacji o wspólnej strukturze między eksperymentami, dzięki czemu podobne typy komórek z różnych źródeł naturalnie wyrównują się w nauczonej przestrzeni bez potrzeby jawnego dopasowywania.
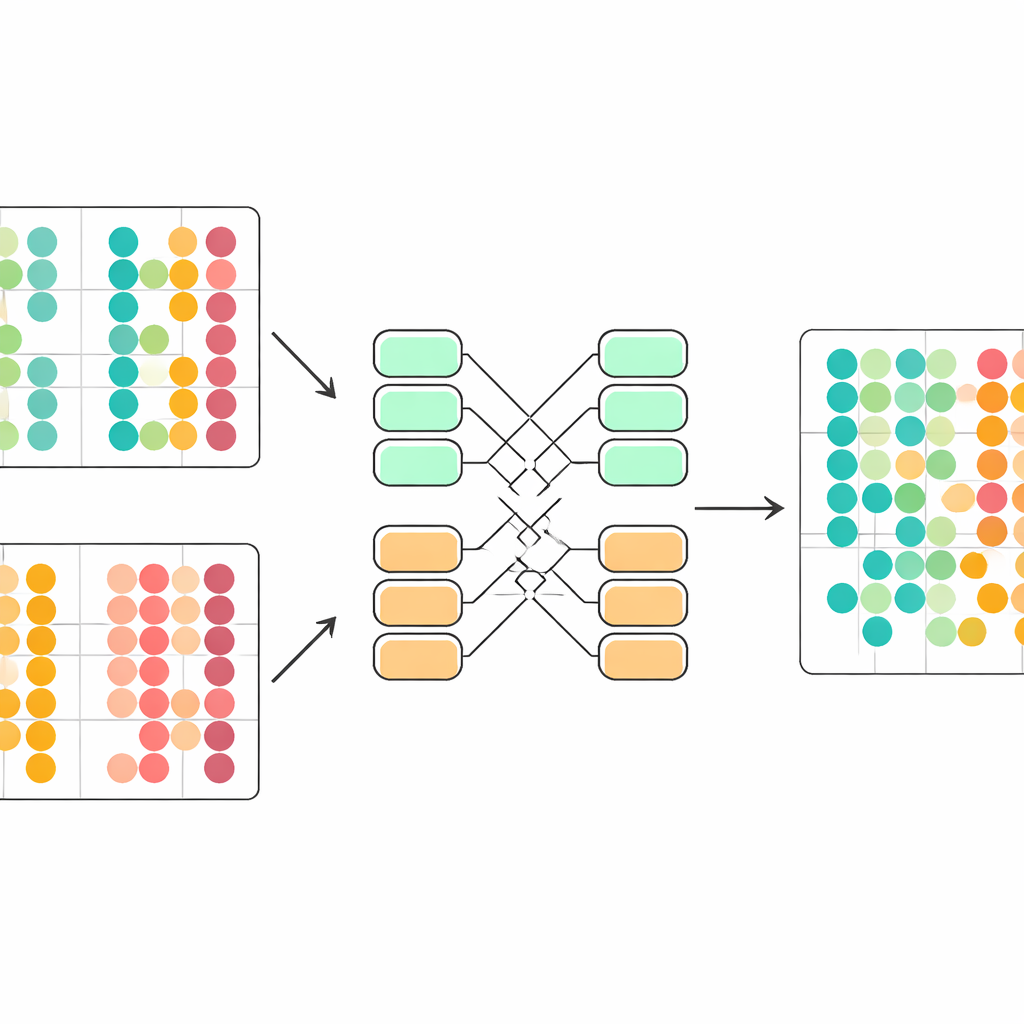
Pokonując ustalone narzędzia na rzeczywistych zbiorach danych
Autorzy rygorystycznie testują scDecorr na pięciu wymagających zbiorach danych pojedynczych komórek, obejmujących tkanki ludzkie i mysie, komórki układu odpornościowego między organami oraz wiele technologii sekwencjonowania. Porównują go z kilkoma powszechnie używanymi narzędziami do integracji oraz prostymi podejściami, takimi jak analiza składowych głównych. Zadanie po zadaniu scDecorr lepiej zachowuje prawdziwe biologiczne grupowania komórek — mierzone standardowymi miarami klastrowania — jednocześnie wystarczająco mieszając partie, by usunąć oczywiste rozdzielenie techniczne. Jest szczególnie skuteczny w unikaniu nadkorekcji, gdy różne typy komórek są błędnie scalane w imię usuwania efektu partii, i ma tendencję do utrzymywania wyraźnych granic dla rzadkich lub specyficznych dla partii typów komórek, które inne metody zacierają lub tracą.
Niezawodne przenoszenie etykiet komórek
Ponad integrację zbiorów, scDecorr testowany jest także w zadaniu przenoszenia etykiet: użyciu anotowanego zestawu referencyjnego do przypisania typów komórek do nowego, nieoznaczonego zbioru. Przy użyciu prostych klasyfikatorów lub klastrowania w przestrzeni scDecorr, metoda niezawodnie odtwarza znane typy komórek między różnymi chemiami, platformami i badaniami. Często przewyższa lub dorównuje najlepszym istniejącym narzędziom pod względem dokładności klasyfikacji, a jednocześnie bardziej konsekwentnie zachowuje wewnętrzną strukturę typów komórek w każdym zbiorze. Ta wydajność utrzymuje się nawet wtedy, gdy tylko część typów komórek jest współdzielona między zbiorami lub gdy partie są silnie niezrównoważone, choć autorzy zauważają, że skrajnie niedopasowane ustawienia pozostają trudne dla wszystkich metod.
Co to oznacza dla przyszłych atlasów komórek
Mówiąc prosto, scDecorr oferuje sposób, by różnorodne eksperymenty pojedynczych komórek „mówiły tym samym językiem” bez ciężkich korekt, które wymazują istotne różnice. Ucząc bogatych, niskowymiarowych podsumowań odpornych na szum, a jednocześnie wrażliwych na prawdziwą różnorodność biologiczną, ułatwia budowanie połączonych map komórek w przekroju tkanek, technologii i badań oraz ponowne wykorzystanie istniejących danych do anotowania nowych eksperymentów. Chociaż jest miejsce na przyszłe udoskonalenia — zwłaszcza dla bardzo niezrównoważonych zbiorów — scDecorr stanowi potężną i bardziej ostrożną alternatywę dla korekcji efektu partii, pomagając naukowcom dostrzec prawdziwy krajobraz komórkowy przy mniejszej liczbie zniekształceń technicznych.
Cytowanie: Sanyal, R., Xu, Y., Kim, H. et al. scDecorr: feature decorrelation based representation learning enables self-supervised alignment of multiple single-cell experiments. Sci Rep 16, 13782 (2026). https://doi.org/10.1038/s41598-026-50586-z
Słowa kluczowe: sekwencjonowanie RNA pojedynczych komórek, integracja danych, uczenie samonadzorowane, korekcja efektu partii, atlas komórek