Clear Sky Science · fr
scDecorr : l’apprentissage de représentations par décorrelation de caractéristiques permet l’alignement auto-supervisé de multiples expériences unicellulaires
Pourquoi il est important de rassembler les données unicellulaires
La biologie moderne peut désormais lire l’activité de milliers de gènes dans des cellules individuelles, révélant des types cellulaires rares et des états pathologiques subtils. Mais ces expériences unicellulaires sont souvent réalisées dans des laboratoires différents, avec des machines et protocoles variés, ce qui complique leur combinaison. L’article présente scDecorr, une nouvelle méthode computationnelle qui aligne automatiquement ces jeux de données hétérogènes de sorte que des cellules similaires se retrouvent ensemble, même si elles ont été mesurées de façons très différentes. Cela facilite la construction d’atlas cellulaires riches et la réutilisation des données entre études.
De nombreux jeux de données, un langage commun
Le séquençage ARN unicellulaire mesure quels gènes sont activés dans chaque cellule. En principe, cela permet de comparer des cellules entre organes, patients ou maladies. En pratique, des particularités techniques—appelées effets de lot—peuvent masquer les véritables différences biologiques. Des cellules d’un même type peuvent sembler différentes simplement parce qu’elles ont été traitées un autre jour ou avec une autre technologie. scDecorr s’attaque à ce problème en apprenant un « profil » numérique compact pour chaque cellule, dans lequel les cellules qui se comportent de manière similaire sont rapprochées, tandis que les cellules dissemblables sont écartées. Fait crucial : cela se fait sans nécessiter d’étiquettes de types cellulaires fournies par des experts, ce qui rend la méthode adaptée à des jeux de données volumineux et désordonnés.
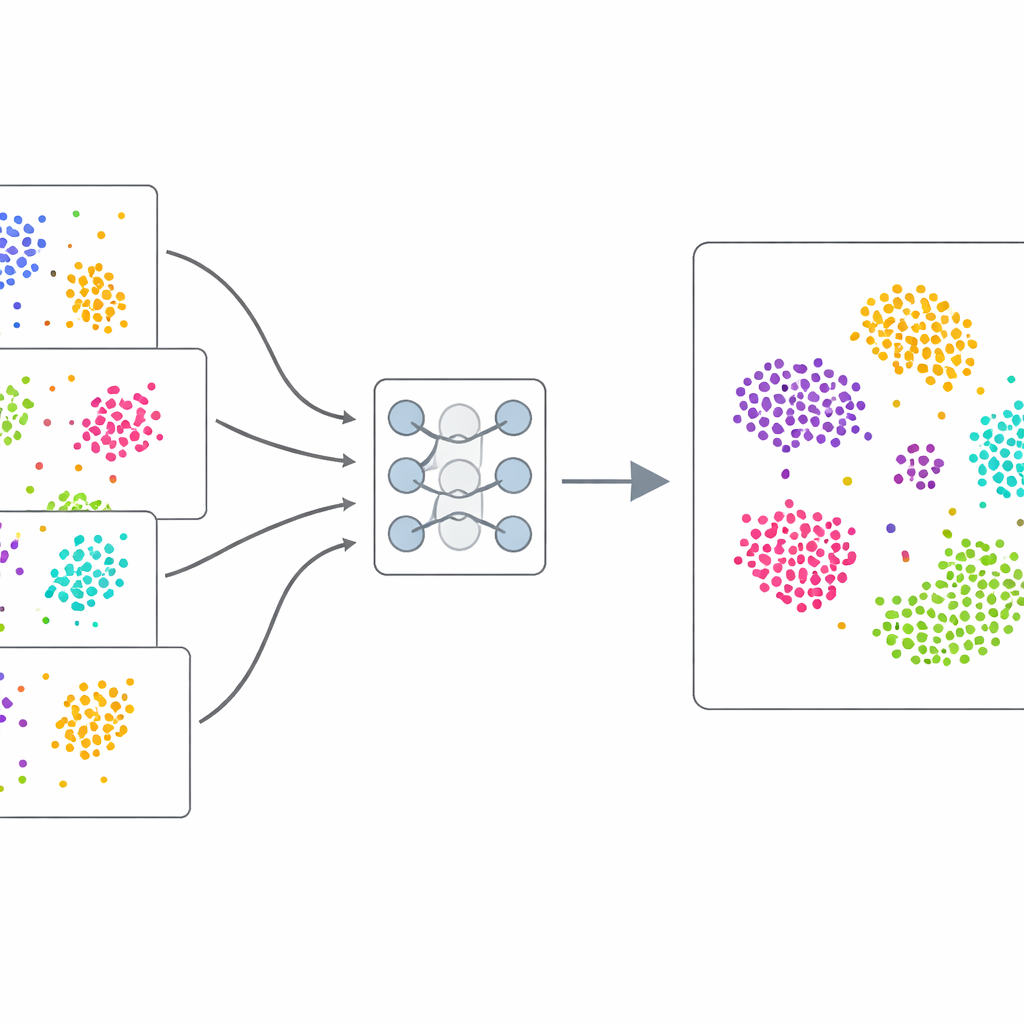
Apprendre à partir des données elles‑mêmes
Plutôt que de s’appuyer sur des exemples annotés manuellement, scDecorr utilise l’apprentissage auto‑supervisé : les données fournissent leur propre signal d’entraînement. Pour chaque cellule, la méthode crée deux copies légèrement altérées de son profil d’expression génique, par exemple en supprimant ou en mélangeant aléatoirement certaines valeurs. Un réseau neuronal jumeau traite les deux versions et est entraîné à produire des résumés internes très similaires pour les deux vues d’une même cellule, mais des résumés différents pour des cellules distinctes. En parallèle, scDecorr encourage chaque composante de ces résumés à porter une information unique, de sorte qu’aucune caractéristique ne duplique simplement une autre. Cette étape de « décorrelation » aide à empêcher le modèle de se concentrer sur quelques motifs dominants et permet de capter un large éventail de signaux biologiques.
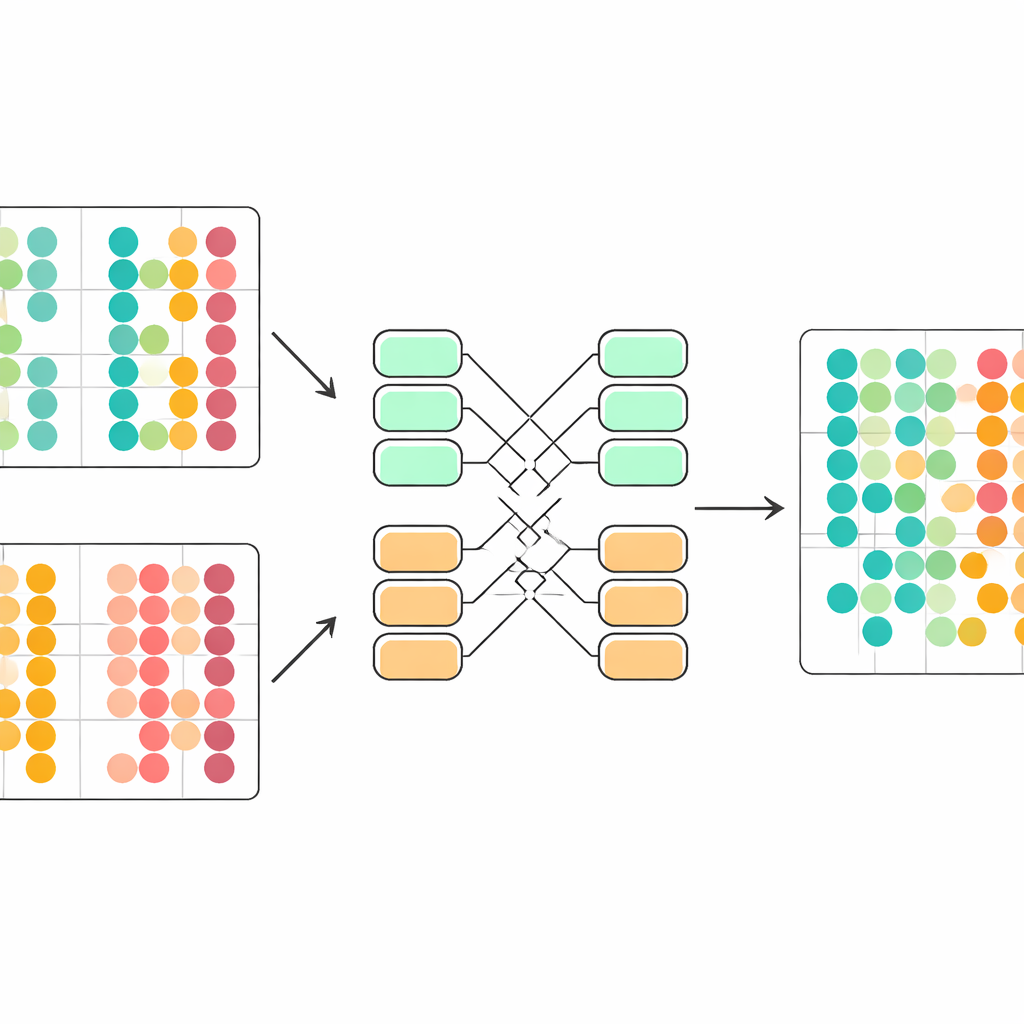
Corriger discrètement les différences techniques
Un défi central est que les cellules issues d’études différentes suivent des règles statistiques légèrement distinctes. Si on les mélange naïvement, le modèle peut interpréter à tort des différences techniques comme biologiques. scDecorr résout cela avec une idée empruntée à l’adaptation de domaine. Tous les lots partagent le même encodeur, mais chaque lot dispose de ses propres couches de normalisation qui remettent à l’échelle les caractéristiques afin que, au sein de ce lot, chaque dimension ait une forme standard. L’objectif de décorrelation est alors appliqué séparément à l’intérieur de chaque lot, tandis que tous les lots passent par le même encodeur. Cela pousse doucement l’encodeur à produire des représentations suivant une structure commune à travers les expériences, de sorte que des types cellulaires similaires provenant de sources différentes s’alignent naturellement dans l’espace appris sans étape explicite d’appariement.
Meilleure performance que les outils établis sur des jeux de données réels
Les auteurs évaluent rigoureusement scDecorr sur cinq collections exigeantes de données unicellulaires, couvrant tissus humains et murins, cellules immunitaires à travers les organes et plusieurs technologies de séquençage. Ils le comparent à plusieurs outils d’intégration largement utilisés, ainsi qu’à des approches simples comme l’analyse en composantes principales. À maintes reprises, scDecorr préserve mieux les regroupements biologiques réels des cellules—mesurés par des scores de clustering standards—tout en mélangeant suffisamment les lots pour éliminer une séparation technique évidente. Il se montre particulièrement performant pour éviter la surcorrection, où des types cellulaires différents sont fusionnés à tort au nom de la suppression des lots, et tend à maintenir des frontières nettes pour des types cellulaires rares ou spécifiques à un lot que d’autres méthodes brouillent ou perdent.
Transfert d’étiquettes cellulaires fiable
Au‑delà de la fusion de jeux de données, scDecorr est testé sur le transfert d’étiquettes : utiliser un jeu de référence annoté pour attribuer des types cellulaires à un nouveau jeu non annoté. En utilisant des classifieurs simples ou du clustering dans l’espace scDecorr, la méthode retrouve de manière fiable les types cellulaires connus à travers différentes chimies, plateformes et études. Elle dépasse souvent ou égale les meilleurs outils existants en précision de classification, tout en préservant plus systématiquement la structure interne des types cellulaires au sein de chaque jeu. Cette performance tient même lorsque seuls certains types cellulaires sont partagés entre jeux, ou lorsque les lots sont fortement déséquilibrés, bien que les auteurs notent que des configurations extrêmement inadaptées restent difficiles pour toutes les méthodes.
Ce que cela signifie pour les atlas cellulaires futurs
En termes simples, scDecorr offre un moyen de faire « parler le même langage » à des expériences unicellulaires diverses sans corrections lourdes qui effacent des différences importantes. En apprenant des résumés riches et de faible dimension robustes au bruit mais sensibles à la diversité biologique réelle, il facilite la construction de cartes combinées des cellules à travers tissus, technologies et études, et la réutilisation de données existantes pour annoter de nouvelles expériences. S’il reste de la place pour des améliorations futures—notamment pour des jeux de données très déséquilibrés—scDecorr propose une alternative puissante et plus prudente à la correction d’effet lot, aidant les scientifiques à percevoir le paysage cellulaire réel avec moins de distorsions techniques.
Citation: Sanyal, R., Xu, Y., Kim, H. et al. scDecorr: feature decorrelation based representation learning enables self-supervised alignment of multiple single-cell experiments. Sci Rep 16, 13782 (2026). https://doi.org/10.1038/s41598-026-50586-z
Mots-clés: séquençage ARN unicellulaire, intégration de données, apprentissage auto-supervisé, correction d’effet lot, atlas cellulaire