Clear Sky Science · sv
scDecorr: funktion-dekorrelationsbaserat representationslärande möjliggör självövervakat justering av flera enkelcellsexperiment
Varför samordning av enkelcellsdata är viktig
Modern biologi kan nu avläsa aktiviteten hos tusentals gener i enskilda celler, vilket avslöjar sällsynta celltyper och subtila sjukdomstillstånd. Men dessa enkelcellsstudier utförs ofta i olika laboratorier, med olika instrument och protokoll, vilket gör resultat svåra att kombinera. Artikeln presenterar scDecorr, en ny beräkningsmetod som automatiskt jämför sådana skiftande dataset så att liknande celler hamnar tillsammans, även om de mättes på mycket olika sätt. Det gör det lättare för forskare att bygga detaljerade cellatlaser och att återanvända data över studier.
Många dataset, ett gemensamt språk
Single-cell RNA-sekvensering mäter vilka gener som är aktiva i varje cell. I teorin låter det forskare jämföra celler över organ, patienter eller sjukdomar. I praktiken kan tekniska särdrag—så kallade batch-effekter—drukna de verkliga biologiska skillnaderna. Celler av samma typ kan se olika ut bara för att de hanterats en annan dag eller med en annan teknik. scDecorr tacklar detta genom att lära en kompakt numerisk "profil" för varje cell, där celler med liknande funktion placeras nära varandra medan olika celltyper hålls isär. Avgörande är att det görs utan behov av expertmärkta celltypsetiketter, vilket gör metoden lämplig för stora, röriga dataset.
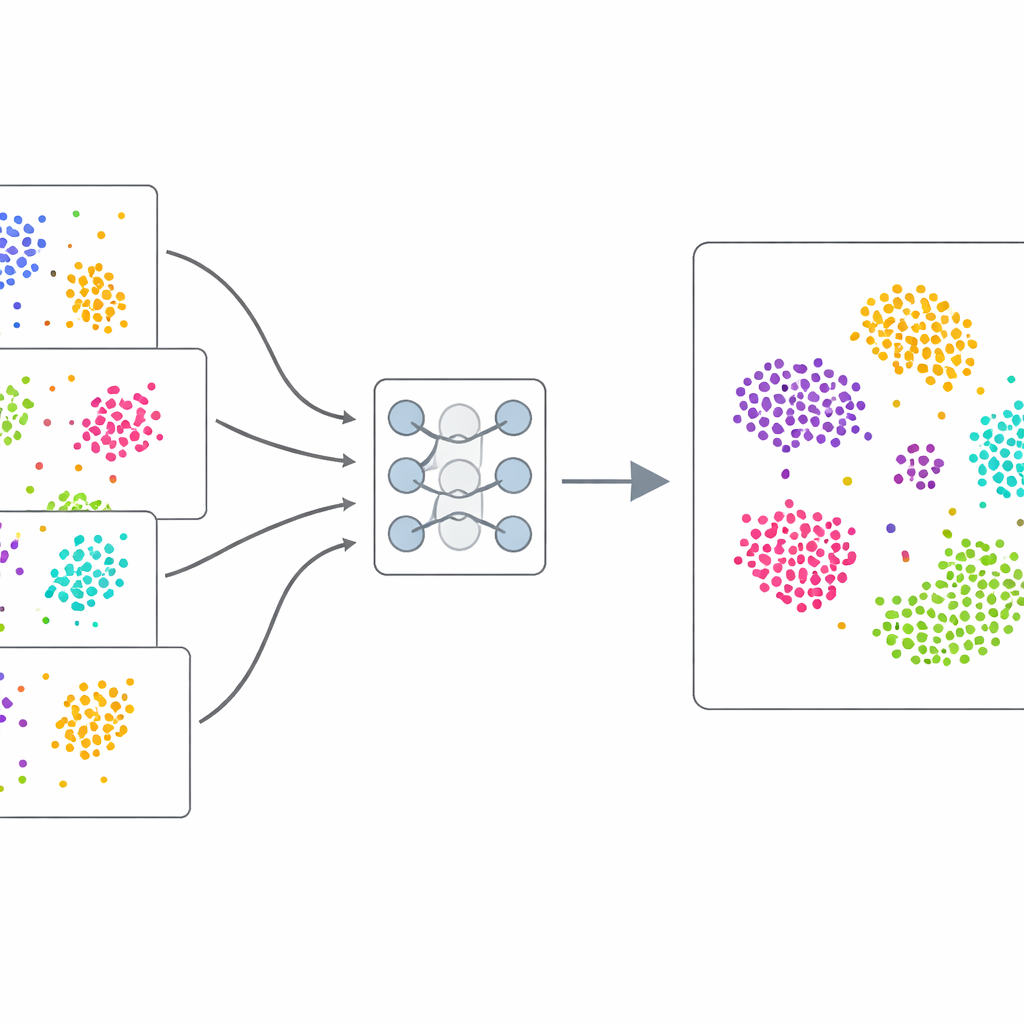
Lärande från data själva
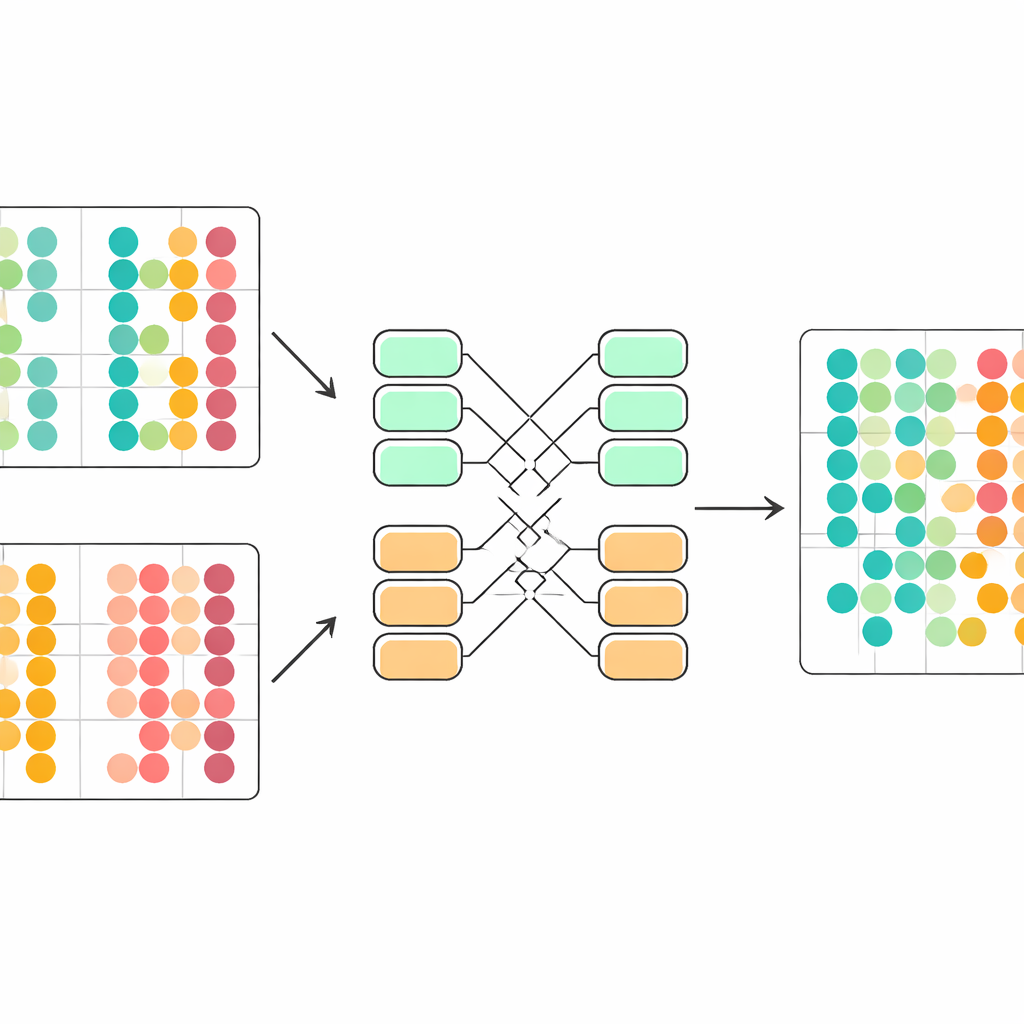
I stället för att förlita sig på handmärkta exempel använder scDecorr självövervakat lärande: datan ger sin egen träningssignal. För varje cell skapar metoden två lätt förvrängda kopior av dess genuttrycksprofil, till exempel genom att slumpmässigt ta bort eller blanda vissa värden. Ett tvillingneuralt nätverk bearbetar båda versionerna och tränas att producera mycket liknande interna sammanfattningar för de två vyerna av samma cell, men olika sammanfattningar för olika celler. Samtidigt uppmuntrar scDecorr varje komponent i dessa sammanfattningar att bära unik information, så att ingen enskild funktion bara duplicerar en annan. Detta steg med "dekorrelation" hjälper till att förhindra att modellen kollapsar till några få dominerande mönster och fångar istället ett brett spektrum av biologiska signaler.
Tyst korrigering av tekniska skillnader
En central utmaning är att celler från olika studier följer något olika statistiska regler. Om dessa blandas naivt kan modellen feltolka tekniska skillnader som biologiska. scDecorr tar itu med detta med en idé hämtad från domänanpassning. Alla batchar delar samma encoder-nätverk, men varje batch har sina egna normaliseringslager som skalar om funktionerna så att varje dimension inom den batchen har en enhetlig form. Dekorrelationsmålet tillämpas sedan separat inom varje batch, men alla batchar måste passera genom samma encoder. Detta driver försiktigt encodern att producera representationer som följer en gemensam struktur över experimenten, så att liknande celltyper från olika källor naturligt linjerar upp i det inlärda utrymmet utan något explicit matchningssteg.
Slår etablerade verktyg på verkliga dataset
Författarna testar noggrant scDecorr på fem krävande samlingar av enkelcellsdata, från mänsklig och musvävnad till immunceller över organ och flera sekvenseringstekniker. De jämför metoden med flera vida använda integrationsverktyg samt enkla tillvägagångssätt som huvudkomponentsanalys. Uppgift efter uppgift bevarar scDecorr de verkliga biologiska grupperingarna av celler bättre—mätt med standardklusterpoäng—samtidigt som den blandar batcharna tillräckligt för att ta bort uppenbar teknisk separation. Den är särskilt bra på att undvika överkorrigering, där olika celltyper felaktigt slås ihop i batchborttagningens namn, och tenderar att behålla tydliga gränser för sällsynta eller batch-specifika celltyper som andra metoder suddar ut eller förlorar.
Pålitlig överföring av celletiketter
Utöver att slå ihop dataset testas scDecorr för etikettöverföring: att använda ett annoterat referensdataset för att tilldela celltypsetiketter till ett nytt, oannoterat dataset. Med enkla klassificerare eller klustring i scDecorr-rummet återfinner metoden pålitligt kända celltyper över olika kemier, plattformar och studier. Den överträffar eller matchar ofta de bästa befintliga verktygen i klassificeringsnoggrannhet, samtidigt som den mer konsekvent bevarar den interna celltypstrukturen inom varje dataset. Denna prestanda håller i sig även när endast vissa celltyper delas mellan dataset eller när batcharna är mycket obalanserade, även om författarna noterar att extremt missanpassade situationer fortfarande är utmanande för alla metoder.
Vad detta betyder för framtida cellatlaser
Enkelt uttryckt erbjuder scDecorr ett sätt att låta skilda enkelcellsexperiment "tala samma språk" utan tunga korrigeringar som suddar ut viktiga skillnader. Genom att lära rika, lågdimensionella sammanfattningar som är robusta mot brus men känsliga för verklig biologisk mångfald underlättar metoden att bygga kombinerade kartor över celler i olika vävnader, tekniker och studier, och att återanvända befintlig data för att annotera nya experiment. Även om det finns utrymme för framtida förbättringar—särskilt för mycket obalanserade dataset—ger scDecorr ett kraftfullt och mer försiktigt alternativ till batchkorrigering, vilket hjälper forskare att se det verkliga cellulära landskapet med färre tekniska förvrängningar.
Citering: Sanyal, R., Xu, Y., Kim, H. et al. scDecorr: feature decorrelation based representation learning enables self-supervised alignment of multiple single-cell experiments. Sci Rep 16, 13782 (2026). https://doi.org/10.1038/s41598-026-50586-z
Nyckelord: single-cell RNA sequencing, data integration, self-supervised learning, batch effect correction, cell atlas