Clear Sky Science · pt
scDecorr: aprendizado de representação baseado em descarrelação de características possibilita alinhamento auto-supervisionado de múltiplos experimentos de célula única
Por que reunir dados de célula única importa
A biologia moderna já consegue ler a atividade de milhares de genes em células individuais, revelando tipos celulares raros e estados de doença sutis. Mas esses experimentos de célula única frequentemente são realizados em diferentes laboratórios, usando máquinas e protocolos distintos, o que dificulta combinar seus resultados. O artigo apresenta o scDecorr, um novo método computacional que alinha automaticamente conjuntos de dados tão diversos para que células semelhantes fiquem juntas, mesmo quando foram medidas de maneiras muito diferentes. Isso facilita a construção de atlas celulares ricos e a reutilização de dados entre estudos.
Muitos conjuntos de dados, uma linguagem comum
O sequenciamento de RNA em célula única mede quais genes estão ativados em cada célula. Em princípio, isso permite comparar células entre órgãos, pacientes ou doenças. Na prática, peculiaridades técnicas — conhecidas como efeitos de lote — podem abafar as verdadeiras diferenças biológicas. Células do mesmo tipo podem parecer diferentes apenas porque foram processadas em outro dia ou com outra tecnologia. O scDecorr enfrenta isso aprendendo um "perfil" numérico compacto para cada célula, no qual células que se comportam de maneira semelhante ficam próximas, enquanto células dissimilares são mantidas afastadas. Crucialmente, ele faz isso sem precisar de rótulos de tipos celulares fornecidos por especialistas, tornando-o adequado para conjuntos de dados grandes e desordenados.
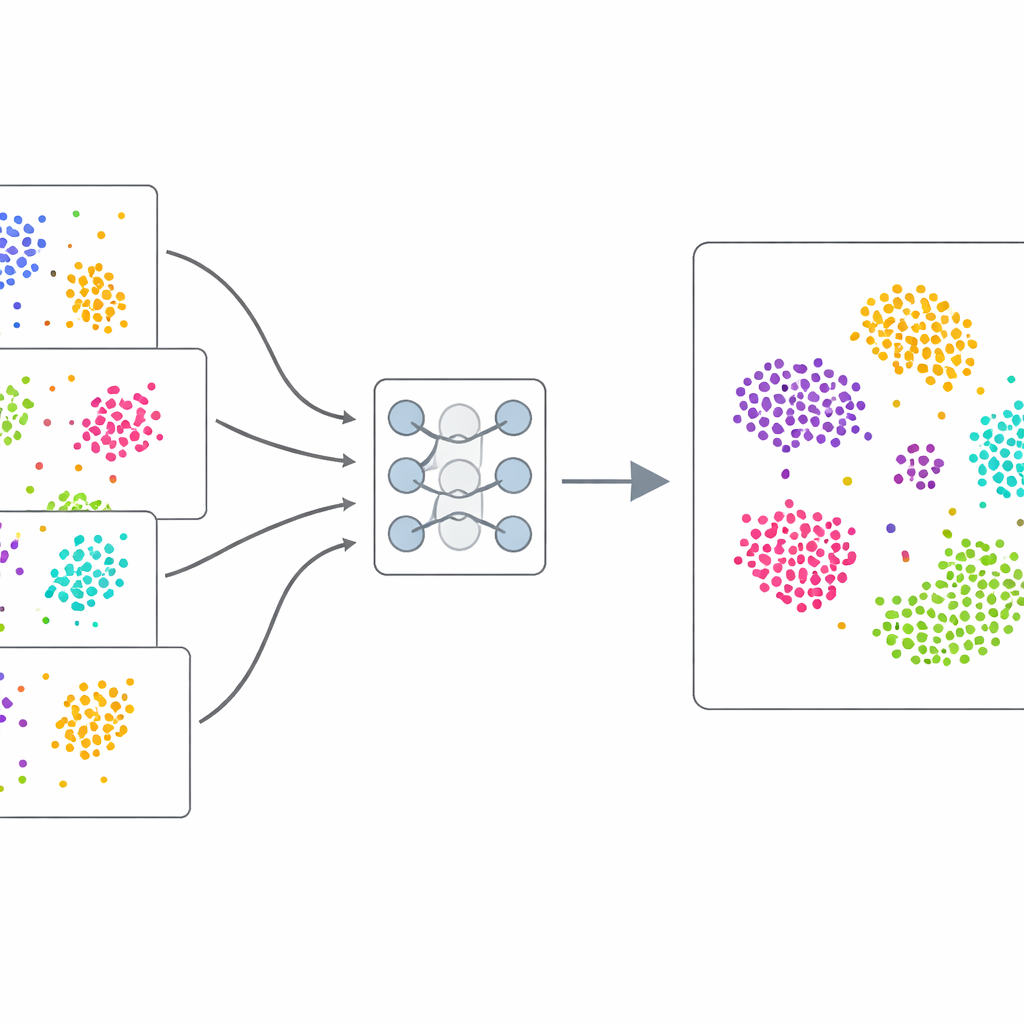
Aprendendo a partir dos próprios dados
Em vez de depender de exemplos rotulados manualmente, o scDecorr usa aprendizado auto-supervisionado: os próprios dados fornecem o sinal de treinamento. Para cada célula, o método cria duas cópias levemente distorcidas de seu padrão de expressão gênica, por exemplo, removendo ou embaralhando aleatoriamente alguns valores. Uma rede neural gêmea processa ambas as versões e é treinada para produzir resumos internos muito semelhantes para as duas visões da mesma célula, mas resumos diferentes para células distintas. Ao mesmo tempo, o scDecorr incentiva que cada componente desses resumos carregue informação única, para que nenhuma característica simplesmente duplique outra. Essa etapa de “descarrelação” ajuda a evitar que o modelo colapse em poucos padrões dominantes e, em vez disso, capture uma ampla gama de sinais biológicos.
Corrigindo discretamente as diferenças técnicas
Um desafio central é que células de estudos diferentes seguem regras estatísticas ligeiramente distintas. Se essas diferenças forem misturadas de forma ingênua, o modelo pode interpretar erroneamente variações técnicas como biologia. O scDecorr aborda isso com uma ideia emprestada da adaptação de domínio. Todos os lotes compartilham a mesma rede codificadora, mas cada lote tem suas próprias camadas de normalização que reescalam as características para que, dentro daquele lote, cada dimensão tenha uma forma padrão. O objetivo de descarrelação é então aplicado separadamente dentro de cada lote, contudo todos os lotes devem passar pela mesma codificadora. Isso empurra suavemente a codificadora a produzir representações que seguem uma estrutura compartilhada entre experimentos, de modo que tipos celulares semelhantes de fontes distintas se alinhem naturalmente no espaço aprendido sem qualquer etapa explícita de pareamento.
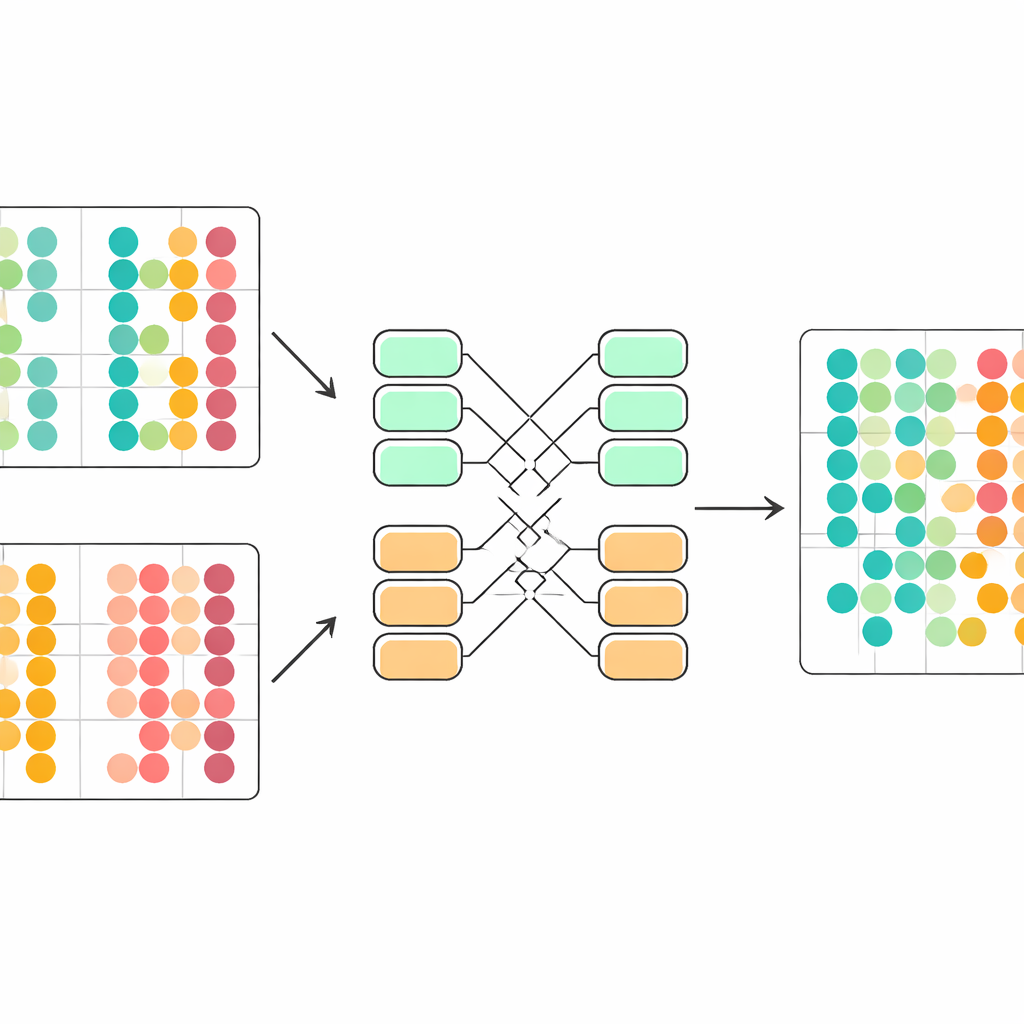
Superando ferramentas estabelecidas em conjuntos reais
Os autores testam rigorosamente o scDecorr em cinco coleções exigentes de dados de célula única, abrangendo tecidos humanos e de camundongo, células imunes entre órgãos e múltiplas tecnologias de sequenciamento. Eles comparam com várias ferramentas de integração amplamente usadas, bem como com abordagens simples como análise de componentes principais. Em tarefa após tarefa, o scDecorr preserva melhor os agrupamentos biológicos verdadeiros das células — medido por pontuações padrão de clusterização — enquanto ainda mistura lotes o suficiente para remover separações técnicas óbvias. Ele é especialmente eficaz em evitar a correção excessiva, onde diferentes tipos celulares são erroneamente fundidos em nome da remoção de lote, e tende a manter limites claros para tipos celulares raros ou específicos de um lote que outros métodos borram ou perdem.
Transferência confiável de rótulos celulares
Além de mesclar conjuntos, o scDecorr é testado em transferência de rótulos: usar um conjunto de referência anotado para atribuir rótulos de tipo celular a um novo conjunto não anotado. Usando classificadores simples ou clusterização no espaço do scDecorr, o método recupera de forma confiável tipos celulares conhecidos através de diferentes químicas, plataformas e estudos. Frequentemente supera ou iguala as melhores ferramentas existentes em acurácia de classificação, ao mesmo tempo em que preserva de forma mais consistente a estrutura interna de tipos celulares dentro de cada conjunto. Esse desempenho se mantém mesmo quando apenas alguns tipos celulares são compartilhados entre conjuntos, ou quando os lotes são altamente desequilibrados, embora os autores observem que cenários extremamente incompatíveis continuam desafiadores para todos os métodos.
O que isso significa para futuros atlas celulares
Em termos simples, o scDecorr oferece uma maneira de permitir que experimentos diversos de célula única “falem a mesma língua” sem correções pesadas que apaguem diferenças importantes. Ao aprender resumos ricos e de baixa dimensionalidade que são robustos ao ruído, mas sensíveis à diversidade biológica genuína, ele facilita a construção de mapas combinados de células através de tecidos, tecnologias e estudos, e a reutilização de dados existentes para anotar novos experimentos. Embora haja espaço para refinamentos futuros — especialmente para conjuntos muito desequilibrados — o scDecorr fornece uma alternativa poderosa e mais cautelosa à correção de lote, ajudando cientistas a ver o verdadeiro panorama celular com menos distorções técnicas.
Citação: Sanyal, R., Xu, Y., Kim, H. et al. scDecorr: feature decorrelation based representation learning enables self-supervised alignment of multiple single-cell experiments. Sci Rep 16, 13782 (2026). https://doi.org/10.1038/s41598-026-50586-z
Palavras-chave: sequenciamento de RNA em célula única, integração de dados, aprendizado auto-supervisionado, correção de efeito de lote, atlas celular