Clear Sky Science · zh
利用数据增强与迁移学习自动检测刻板化的动物声音
倾听海洋中隐藏的声音
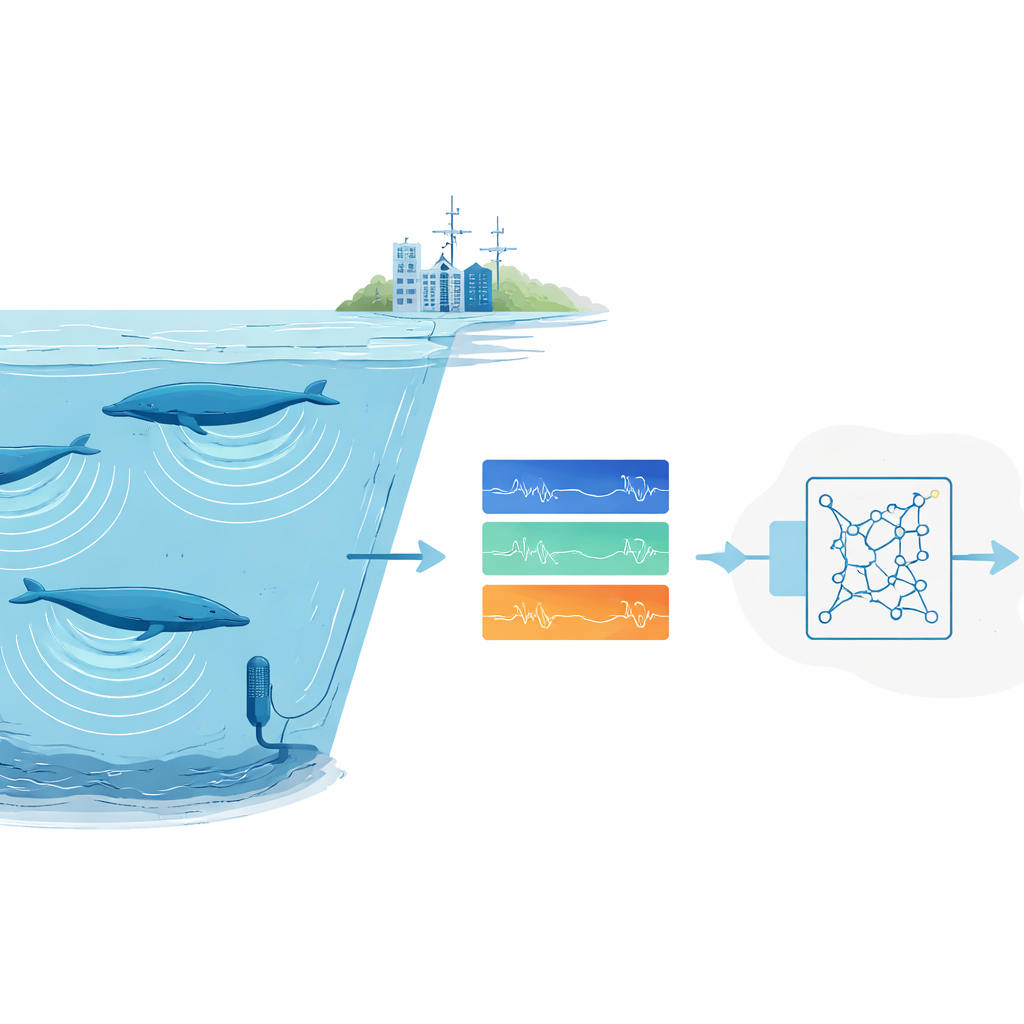
在世界各地的海洋中,庞大的水下麦克风静静记录着声景:海浪拍打、船舶引擎、冰层破裂——以及鲸鱼的深沉歌声。这些档案中藏有关于濒危动物栖息地、数量以及它们如何应对变化环境的线索。然而,人类无法逐一通过目视和听觉筛阅如此海量的音频。本研究提出了一种新的训练自动“听者”的方法,能够可靠地识别高度刻板化的动物叫声——例如某些蓝鲸的歌声——即便只有一条高质量的录音可用。
为什么发现动物声音如此困难
科学家越来越依赖被动声学监测:在野外放置录音设备,随后扫描音频以寻找动物叫声。对于常见或响亮的物种,现代深度学习系统表现良好,但它们需要数千个标注样本和强大的计算资源。这对于那些仅有少量录音的稀有或难觅物种,以及没有大型计算集群的研究团队来说,是一个致命障碍。此外,海洋录音往往非常嘈杂。风暴、冰与船舶产生的背景噪声可能掩盖叫声,而人类专家本身也常常对频谱图中哪些微弱标记确实属于鲸鱼存在分歧。
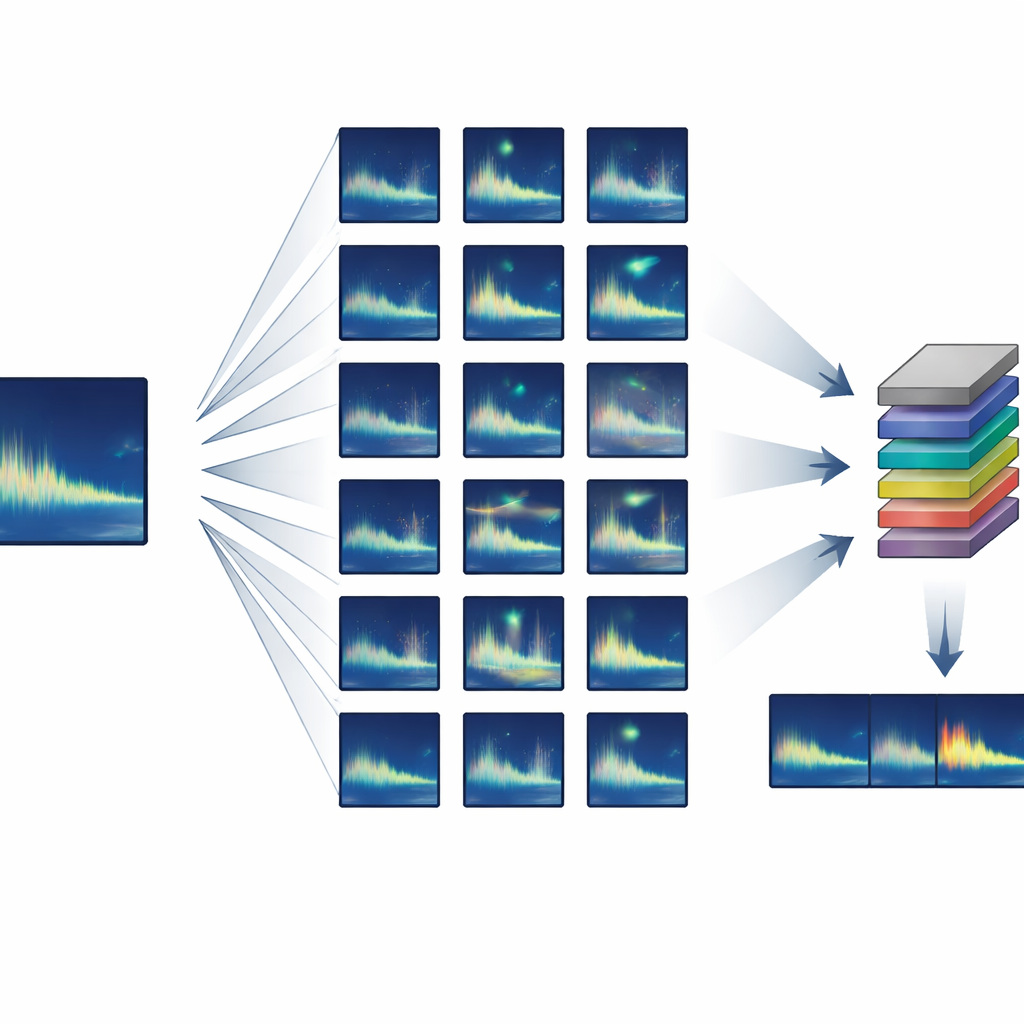
从几乎没有数据构建大型训练集
作者将注意力集中在发出高度重复、或“刻板化”叫声的动物——每个个体发出的声音几乎相同。他们开发了一套半合成训练流水线,从只有一条或几条干净的目标叫声样例开始,生成数千个逼真的变体。利用标准音频处理技术,系统对每个叫声做轻微的时间拉伸或压缩、调整音高以模拟随时间的歌曲变化、加入柔和的失真与回声,并与真实的海洋背景噪声混合。关键在于:所有这些变化都基于已知的鲸类行为和声波传播规律,因此合成的叫声在外观和听感上仍像是真正鲸类可能发出的声音。
重用现有的神经网络
团队没有从头训练检测器,而是采用迁移学习:先使用一个最初为检测人类语音设计的神经网络,然后对其进行微调以识别鲸歌。该网络将声音视为一系列短且重叠的频谱“帧”,并包含能跟随时间模式的循环层,使其可以处理不同长度的叫声。训练仅使用消费级硬件——一台配备中等显卡的普通笔记本——约五小时即可完成。训练完成后,系统能够在大约一分钟半内扫描四小时的海洋音频(包括所有前后处理)。
将检测器付诸考验
该方法在两种截然不同的低频蓝鲸叫声上进行了评估:南极蓝鲸简单且下降的“Z-呼叫”,以及印度洋查戈斯群岛侏儒蓝鲸更复杂的多段歌声。在两种情况下,检测器均完全以半合成数据训练。对于其中一个模型,训练集仅由一条真实的查戈斯歌曲样本构建。为公正评估性能,作者没有盲目依赖现有的“真实”注释日志——这些日志被发现遗漏了许多叫声。相反,一位有经验的分析员手动复核了检测器与日志之间数千处不一致之处。经过裁定,最佳的查戈斯模型以91.2%的精确率正确找到了99.4%的目标叫声,而南极模型在包容性评分(将清晰呼叫与密集合唱均计入)下找到了87%的目标,精确率为65%。
这些结果对保护工作的意义
对非专业读者而言,这些数字意味着检测器可以扫描庞大的档案并可靠地标注出几乎所有特定鲸歌的出现,误报相对较少,即便其训练仅来自一条高质量录音。对于研究声音罕见的濒危物种,这是一个重要进展。作者提醒,成功依赖于对何谓“命中”的明确定义——例如,是否应包含重叠的合唱——以及对正负训练样本的谨慎设计。他们还强调,即便是专家的人工标注也并不完美,因此需要更好的检测器评估标准。尽管如此,该框架展示了通过巧妙的数据增强与迁移学习,可以廉价构建并开放共享强大的监听工具,帮助科学家发掘已存于全球声学档案中的隐藏之声。
引用: Jancovich, B.A., Sanchez, V., Truong, G. et al. Automated detection of stereotyped animal sounds using data augmentation and transfer learning. Sci Rep 16, 13137 (2026). https://doi.org/10.1038/s41598-026-48308-6
关键词: 被动声学监测, 蓝鲸歌声, 深度学习检测器, 合成训练数据, 野生动物保护