Clear Sky Science · es
Detección automatizada de sonidos animales estereotipados mediante aumento de datos y aprendizaje por transferencia
Escuchando voces ocultas en el océano
En los océanos del mundo, vastos micrófonos submarinos graban en silencio el paisaje sonoro: olas rompiendo, motores de barcos, hielo crujiendo, y los cantos profundos de las ballenas. Enterrados en esos archivos hay pistas sobre dónde viven animales en peligro, cuántos son y cómo afrontan un planeta en cambio. Sin embargo, hay simplemente demasiado audio para que los humanos lo examinen visual o auditivamente. Este estudio presenta una nueva forma de entrenar un “oyente” automatizado que puede identificar de forma fiable llamadas animales muy estereotipadas —como ciertos cantos de ballena azul— incluso cuando solo existe una única buena grabación de esa llamada.
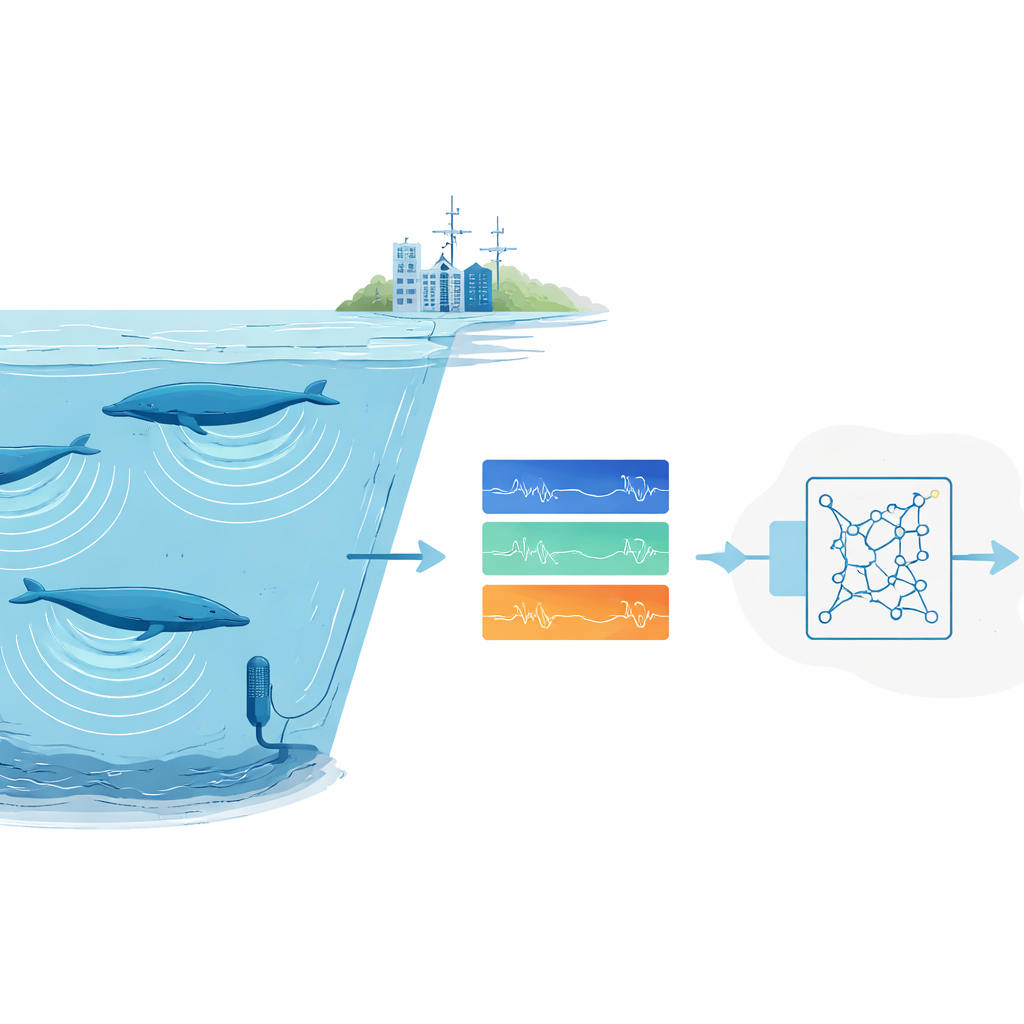
Por qué es tan difícil encontrar sonidos animales
Los científicos confían cada vez más en el monitoreo acústico pasivo: dejar grabadores en la naturaleza y luego escanear el audio para encontrar llamadas animales. Para especies comunes o ruidosas, los sistemas modernos de aprendizaje profundo funcionan bien, pero exigen miles de ejemplos anotados y equipos informáticos potentes. Eso es un problema para animales raros o esquivos cuyas llamadas se han registrado solo en contadas ocasiones, y para grupos de investigación sin acceso a grandes clústeres de cálculo. Además, las grabaciones oceánicas son desordenadas: el ruido de fondo de tormentas, hielo y barcos puede enmascarar las llamadas, y los expertos humanos a menudo discrepan sobre qué marcas tenues en un espectrograma realmente pertenecen a una ballena.
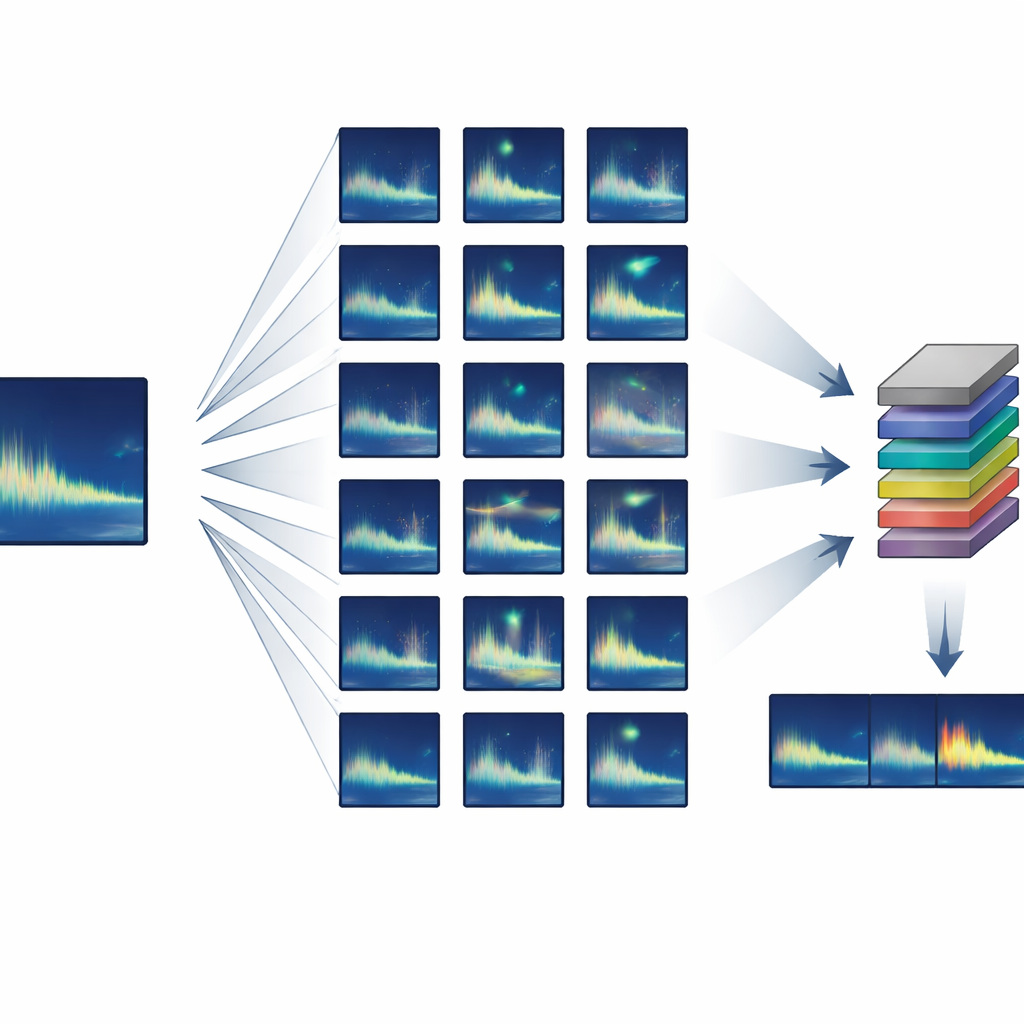
Construir un gran conjunto de entrenamiento a partir de casi nada
Los autores se centraron en animales que producen llamadas altamente repetibles, o “estereotipadas”, donde cada individuo emite casi el mismo sonido. Desarrollaron una tubería de entrenamiento semisintética que parte de solo uno o unos pocos ejemplos limpios de una llamada objetivo y crea miles de variantes realistas. Empleando procesos estándar de audio, el sistema estira o comprime ligeramente cada llamada en el tiempo, desplaza su tono para imitar cambios de canción a largo plazo, añade distorsiones y ecos suaves, y la mezcla con ruido de fondo real del océano. Crucialmente, todos estos cambios están basados en comportamientos conocidos de las ballenas y en la propagación del sonido, por lo que las llamadas sintéticas siguen pareciendo y sonando como algo que una ballena real podría haber producido.
Reutilizando una red neuronal existente
En lugar de entrenar un detector desde cero, el equipo usó aprendizaje por transferencia: comenzaron con una red neuronal diseñada originalmente para detectar el habla humana y la ajustaron finamente para los cantos de ballena. Esta red trata el sonido como una serie de “frames” superpuestos de espectrograma y contiene capas recurrentes que pueden seguir patrones en el tiempo, lo que le permite manejar llamadas de distintas duraciones. El entrenamiento se realizó solo con hardware de consumo —un ordenador portátil estándar con una tarjeta gráfica modesta— y se completó en unas cinco horas. Una vez entrenado, el sistema podía escanear cuatro horas de audio oceánico en aproximadamente minuto y medio, incluyendo todo el preprocesado y postprocesado.
Poniendo a prueba el detector
El método se evaluó con dos llamadas de muy baja frecuencia y muy diferentes de ballenas azules en peligro: la simple y descendente “Z-call” de las ballenas azules antárticas y la canción más compleja y multipartida de las ballenas azules enanas de Chagos en el océano Índico. En ambos casos, el detector se entrenó íntegramente con datos semisintéticos. Para uno de los modelos, el conjunto de entrenamiento se construyó a partir de un único ejemplo real de la canción de Chagos. Para juzgar el rendimiento de forma justa, los autores no se fiaron ciegamente de los registros de anotación “verdad terreno” existentes, que resultaron contener muchas llamadas omitidas. En su lugar, un analista experimentado revisó manualmente miles de desacuerdos entre el detector y los registros. Tras esta adjudicación, el mejor modelo de Chagos encontró correctamente el 99,4% de las llamadas objetivo con un 91,2% de precisión, mientras que el modelo antártico encontró el 87% con un 65% de precisión bajo una puntuación inclusiva que contaba tanto llamadas claras como coros densos.
Qué significan los resultados para la conservación
Para un no especialista, estos números significan que el detector puede escanear archivos masivos y señalar de forma fiable casi todas las ocurrencias de un canto de ballena dado, con relativamente pocas falsas alarmas, incluso cuando se entrenó a partir de una sola buena grabación. Eso supone un avance importante para estudiar especies poco conocidas y amenazadas cuyas voces rara vez se capturan. Los autores advierten que el éxito depende de elecciones claras sobre qué cuenta como un “acierto” —por ejemplo, si deben incluirse los coros superpuestos— y de diseñar con cuidado ejemplos positivos y negativos de entrenamiento. También destacan que incluso las etiquetas humanas expertas son imperfectas, y que aún se necesitan mejores estándares para evaluar detectores. No obstante, este marco muestra que con un aumento de datos ingenioso y aprendizaje por transferencia, se pueden construir herramientas de escucha potentes para la conservación de forma barata y compartida abiertamente, ayudando a los científicos a desbloquear las voces ocultas ya almacenadas en nuestros archivos acústicos globales.
Cita: Jancovich, B.A., Sanchez, V., Truong, G. et al. Automated detection of stereotyped animal sounds using data augmentation and transfer learning. Sci Rep 16, 13137 (2026). https://doi.org/10.1038/s41598-026-48308-6
Palabras clave: monitoreo acústico pasivo, cantos de ballena azul, detector de aprendizaje profundo, datos sintéticos de entrenamiento, conservación de la vida silvestre