Clear Sky Science · nl
Geautomatiseerde detectie van stereotiepe dierengeluiden met data-augmentatie en transfer learning
Luisteren naar verborgen stemmen in de oceaan
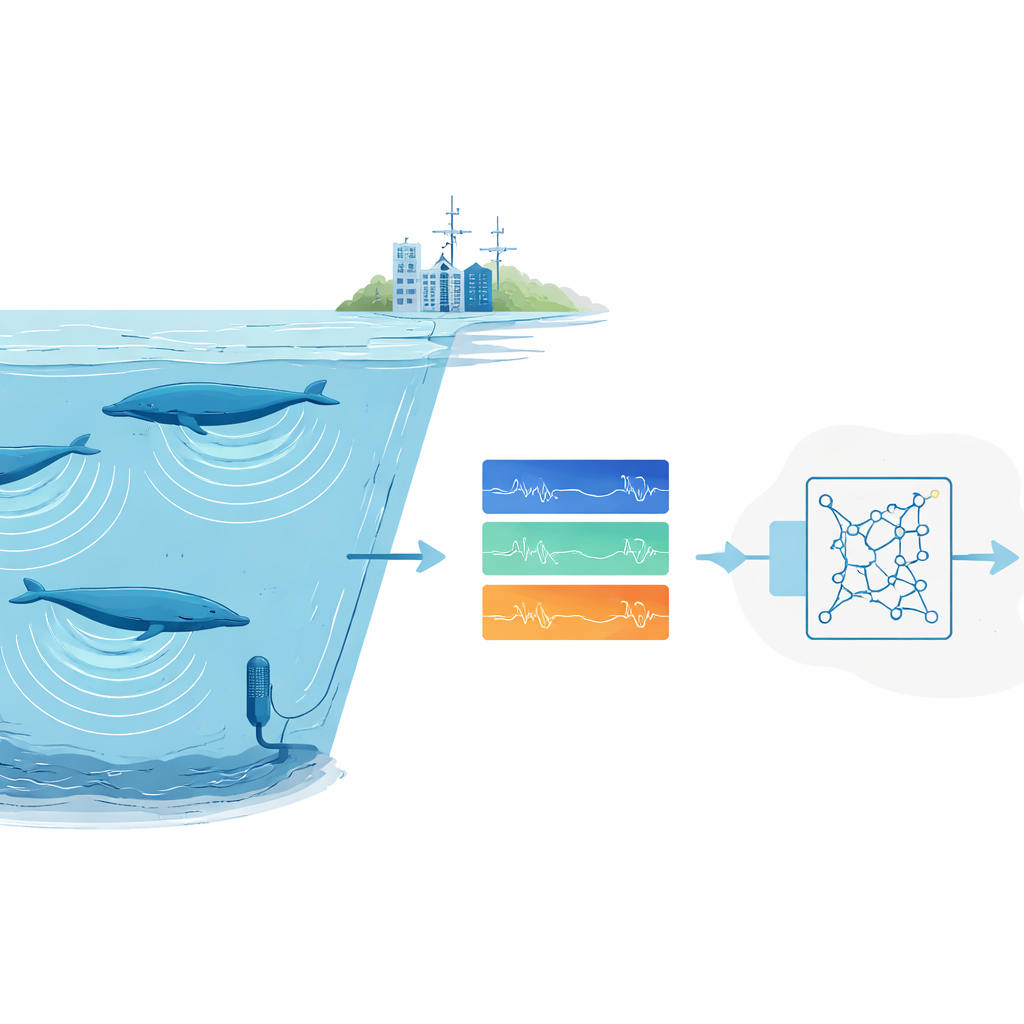
Over de wereldzeeën nemen enorme onderwatermicrofoons stilletjes het geluidstapijt op: brekende golven, scheepsmotoren, krakend ijs – en de diepe liederen van walvissen. In deze archieven liggen aanwijzingen over waar bedreigde dieren leven, hoeveel er zijn en hoe ze omgaan met een veranderende wereld. Maar er is simpelweg te veel audio voor mensen om alles handmatig te doorzoeken. Deze studie presenteert een nieuwe manier om een geautomatiseerde “luisteraar” te trainen die betrouwbaar zeer stereotiepe dierengeluiden kan herkennen – zoals bepaalde blauwe-walvisliederen – zelfs wanneer er maar één goede opname van dat geluid beschikbaar is.
Waarom het vinden van dierengeluiden zo moeilijk is
Wetenschappers vertrouwen steeds vaker op passieve akoestische bewaking: recorders in de natuur achterlaten en later de audio doorzoeken op dierengeluiden. Voor algemene of luide soorten werken moderne deep-learning-systemen goed, maar ze vragen om duizenden gelabelde voorbeelden en krachtige computers. Dat is problematisch voor zeldzame of schuwe dieren waarvan de roepen slechts een paar keer zijn vastgelegd, en voor onderzoeksgroepen zonder toegang tot grote rekenclusters. Daarnaast zijn opnamen uit de oceaan rommelig. Achtergrondgeluid van stormen, ijs en schepen kan roepen overstemmen, en menselijke experts zijn het vaak zelf oneens over welke vage patronen in een spectrogram echt bij een walvis horen.
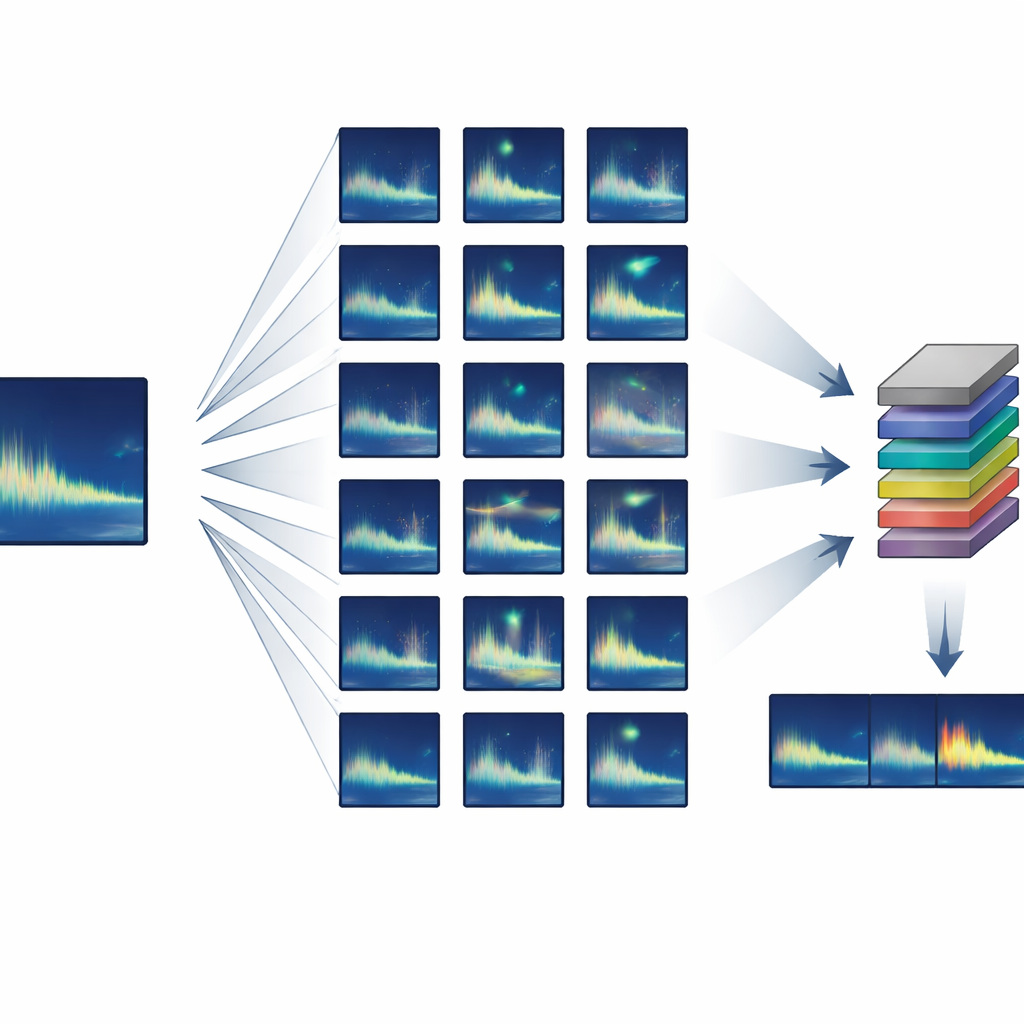
Een grote trainingsset opbouwen uit bijna niets
De auteurs richtten zich op dieren die sterk herhaalbare, of “stereotiepe”, roepen produceren – waarbij elk individu bijna hetzelfde geluid maakt. Ze ontwikkelden een semi-synthetische trainingspijplijn die begint met slechts één of enkele schone voorbeelden van een doelroep en daar vervolgens duizenden realistische varianten van genereert. Met standaard audiobewerking rekt of comprimeert het systeem elke roep licht in de tijd, verschuift de toonhoogte om langetermijnveranderingen in het lied na te bootsen, voegt zachte vervormingen en echo’s toe en mengt het met echte achtergrondruis uit de oceaan. Cruciaal is dat al deze wijzigingen zijn gebaseerd op bekend walvisgedrag en geluidsspreiding, zodat de synthetische roepen er nog steeds uitziet en klinkt alsof een echte walvis ze had kunnen produceren.
Een bestaand neuraal netwerk hergebruiken
In plaats van een detector vanaf nul te trainen, gebruikte het team transfer learning: ze begonnen met een neuraal netwerk dat oorspronkelijk was ontworpen om menselijke spraak te detecteren en stemden het af op walvisliederen. Dit netwerk behandelt geluid als een reeks korte, overlappende spectrogram-„frames” en bevat recurrente lagen die patronen in de tijd kunnen volgen, waardoor het kan omgaan met roepen van verschillende lengte. Het trainen gebruikte alleen consumentenhardware – een standaardlaptop met een bescheiden grafische kaart – en was in ongeveer vijf uur klaar. Eenmaal getraind kon het systeem vier uur oceaanaudio in ongeveer anderhalve minuut scannen, inclusief alle pre- en postprocessing.
De detector op de proef stellen
De methode werd geëvalueerd op twee heel verschillende laagfrequente roepen van bedreigde blauwe walvissen: de eenvoudige, dalende “Z-call” van Antarctische blauwe walvissen en het meer complexe, meerdelige lied van Chagos-pygmee-blauwe walvissen in de Indische Oceaan. In beide gevallen werd de detector volledig getraind op semi-synthetische data. Voor één model werd de trainingsset opgebouwd uit slechts één echt voorbeeld van het Chagos-lied. Om de prestaties eerlijk te beoordelen, vertrouwden de auteurs niet blind op bestaande ’ground truth’-annotatielijsten, die veel gemiste roepen bleken te bevatten. In plaats daarvan beoordeelde een ervaren analist handmatig duizenden verschillen tussen de detector en de lijsten. Na deze oordeelvorming vond het beste Chagos-model 99,4% van de doelroepen correct met 91,2% precisie, terwijl het Antarctische model 87% vond met 65% precisie onder inclusief scoren dat zowel duidelijke roepen als dichte koren meetelde.
Wat de resultaten betekenen voor natuurbehoud
Voor niet-specialisten betekenen deze cijfers dat de detector enorme archieven kan doorzoeken en vrijwel alle voorvallen van een bepaald walvislied betrouwbaar kan markeren, met relatief weinig valse alarmen, zelfs wanneer hij is getraind met slechts één goede opname. Dat is een grote stap voor het bestuderen van weinig bekende, bedreigde soorten waarvan geluiden zelden worden vastgelegd. De auteurs waarschuwen dat succes afhangt van duidelijke keuzes over wat als een “treffer” telt – bijvoorbeeld of overlappende koren moeten worden meegeteld – en van zorgvuldige ontwerpen van zowel positieve als negatieve trainingsvoorbeelden. Ze benadrukken ook dat zelfs menselijke experts imperfecte labels leveren en dat er betere standaarden nodig zijn om detectors te beoordelen. Niettemin toont dit raamwerk dat met slimme data-augmentatie en transfer learning krachtige luisterhulpmiddelen voor natuurbehoud goedkoop te bouwen en open te delen zijn, waardoor wetenschappers de verborgen stemmen in onze wereldwijde akoestische archieven kunnen ontsluiten.
Bronvermelding: Jancovich, B.A., Sanchez, V., Truong, G. et al. Automated detection of stereotyped animal sounds using data augmentation and transfer learning. Sci Rep 16, 13137 (2026). https://doi.org/10.1038/s41598-026-48308-6
Trefwoorden: passieve akoestische bewaking, blauwe walvisliederen, deep learning-detector, synthetische trainingsdata, natuurbehoud