Clear Sky Science · de
Automatisierte Erkennung stereotypischer Tierlaute mittels Datenaugmentation und Transferlernen
Den verborgenen Stimmen im Ozean lauschen
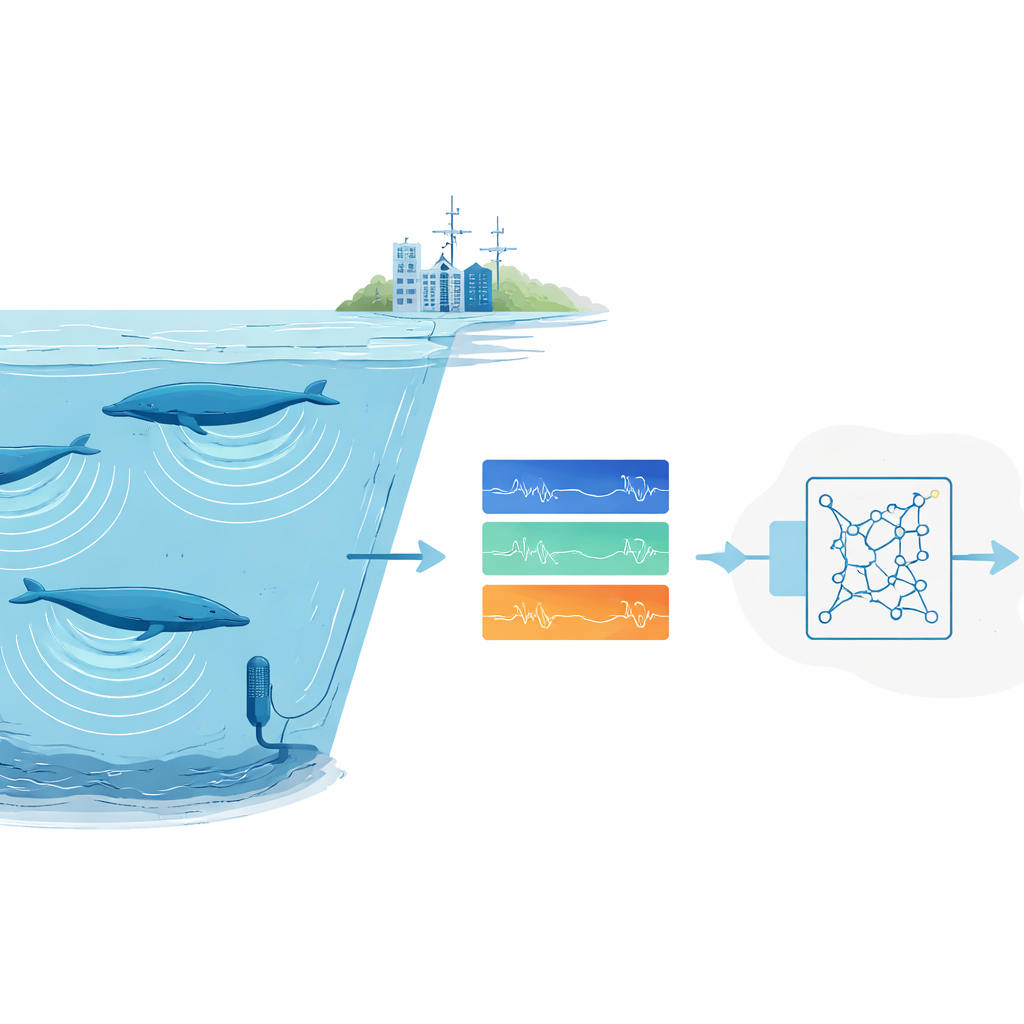
In den Ozeanen dieser Welt zeichnen weit verstreute Unterwassermikrofone still die Klanglandschaft auf: brechende Wellen, Schiffsmotoren, knackendes Eis – und die tiefen Gesänge der Wale. In diesen Archiven stecken Hinweise darauf, wo gefährdete Tiere leben, wie viele es von ihnen gibt und wie sie mit einer sich wandelnden Umwelt zurechtkommen. Doch es gibt schlicht zu viel Audio, um es von Menschen allein mit Auge und Ohr zu durchforsten. Diese Studie stellt eine neue Methode vor, um einen automatisierten „Zuhörer“ zu trainieren, der sehr stereotypische Tierlaute – etwa bestimmte Blauwalsongs – zuverlässig erkennt, selbst wenn nur eine einzige gute Aufnahme dieses Lautes vorliegt.
Warum das Auffinden von Tierlauten so schwierig ist
Wissenschaftlerinnen und Wissenschaftler setzen immer häufiger auf passive akustische Überwachung: Recorder werden in der freien Natur installiert und später wird das aufgenommene Audio nach Tierrufen abgesucht. Für häufige oder laute Arten funktionieren moderne Deep-Learning-Systeme gut, doch sie benötigen Tausende gelabelter Beispiele und leistungsstarke Rechner. Das ist ein Problem für seltene oder scheue Arten, deren Rufe nur wenige Male aufgenommen wurden, und für Forschergruppen ohne Zugang zu großen Rechenclustern. Hinzu kommt, dass Meeresaufnahmen unordentlich sind. Hintergrundgeräusche durch Stürme, Eis und Schiffe können Rufe übertönen, und selbst menschliche Expertinnen und Experten sind sich oft uneins, welche schwachen Markierungen im Spektrogramm tatsächlich zu einem Wal gehören.
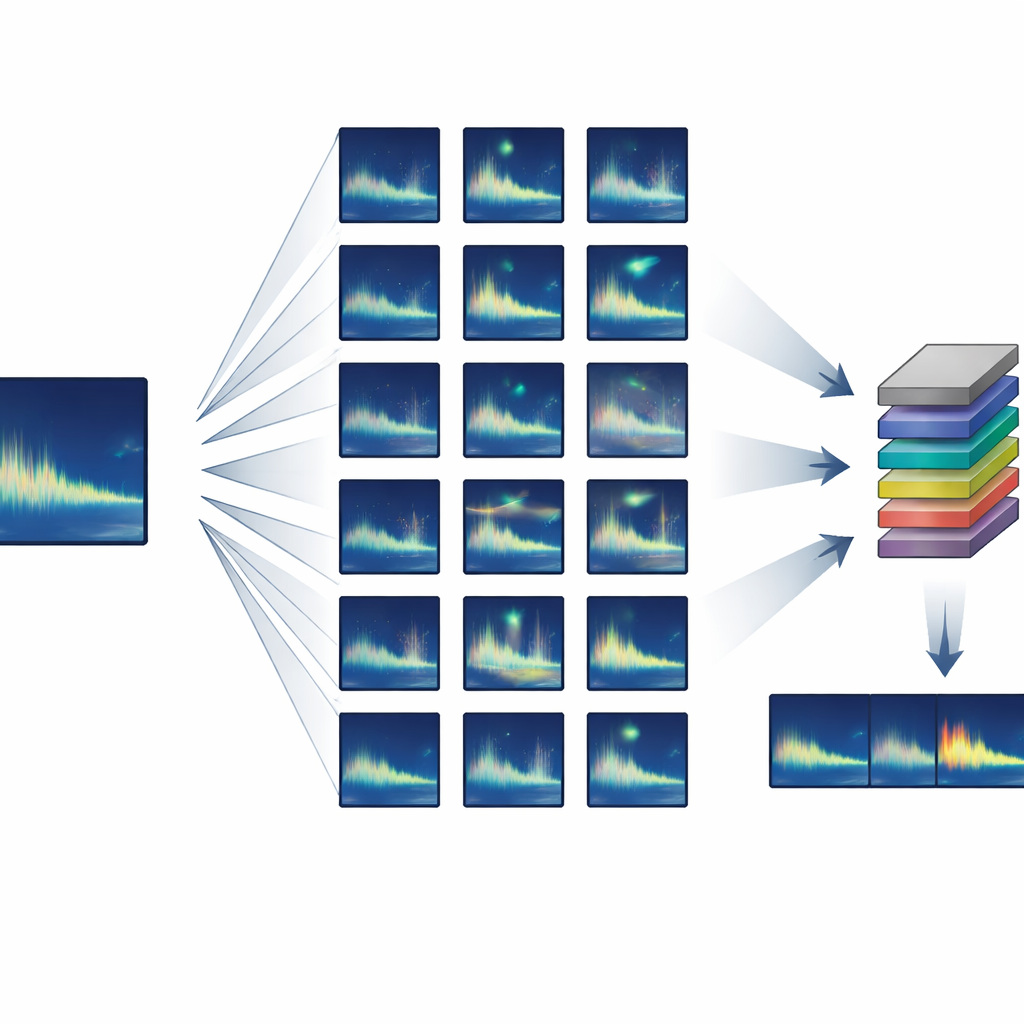
Ein großes Trainingsset aus nahezu nichts aufbauen
Die Autorinnen und Autoren konzentrierten sich auf Tiere, die hochgradig wiederholbare oder „stereotype“ Laute produzieren – bei denen jedes Individuum nahezu denselben Ton von sich gibt. Sie entwickelten eine semi-synthetische Trainingspipeline, die mit nur einem oder wenigen sauberen Beispielen eines Zielrufes beginnt und daraus Tausende realistischer Varianten erzeugt. Mit standardmäßiger Audiobearbeitung wird jeder Ruf leicht in der Zeit gestreckt oder komprimiert, in der Tonhöhe verschoben, um langfristige Änderungen im Gesang nachzuahmen, sanften Verzerrungen und Echos unterzogen und mit echtem Hintergrundrauschen aus dem Ozean gemischt. Entscheidenderweise basieren all diese Veränderungen auf bekanntem Walverhalten und Schallausbreitung, sodass die synthetischen Rufe weiterhin so aussehen und klingen, als könnten sie von einem echten Wal stammen.
Ein bestehendes neuronales Netzwerk wiederverwenden
Statt einen Detektor von Grund auf neu zu trainieren, nutzte das Team Transferlernen: Es startete mit einem neuronalen Netzwerk, das ursprünglich zur Erkennung menschlicher Sprache entwickelt wurde, und passte es für Walsongs fein an. Dieses Netzwerk behandelt Klang als eine Serie kurzer, sich überlappender Spektrogramm‑„Frames“ und enthält rekurrente Schichten, die Muster über die Zeit verfolgen können, sodass es mit Lauten unterschiedlicher Länge zurechtkommt. Das Training lief auf Consumer‑Hardware – einem Standardlaptop mit einer moderaten Grafikkarte – und dauerte etwa fünf Stunden. Einmal trainiert, konnte das System vier Stunden Ozeanaudio in etwa anderthalb Minuten durchsuchen, einschließlich aller Vor‑ und Nachverarbeitungen.
Den Detektor auf die Probe stellen
Die Methode wurde an zwei sehr unterschiedlichen niederfrequenten Lauten gefährdeter Blauwale evaluiert: dem einfachen, absteigenden „Z‑Ruf“ der Antarktischen Blauwale und dem komplexeren, mehrteiligen Gesang der Chagos‑Zwergblauwale im Indischen Ozean. In beiden Fällen wurde der Detektor ausschließlich mit semi‑synthetischen Daten trainiert. Für ein Modell wurde das Trainingsset aus nur einem einzigen realen Beispiel des Chagos‑Gesangs aufgebaut. Um die Leistung fair zu beurteilen, verließen sich die Autorinnen und Autoren nicht blind auf bestehende „Ground‑Truth“‑Annotationsprotokolle, die sich als lückenhaft erwiesen. Stattdessen überprüfte ein erfahrener Analyst manuell Tausende von Abweichungen zwischen Detektor und Protokollen. Nach dieser Begutachtung fand das beste Chagos‑Modell 99,4 % der Zielrufe bei 91,2 % Präzision, während das Antarktik‑Modell 87 % der Rufe mit 65 % Präzision erkannte, gemessen mit einer inklusiven Bewertung, die sowohl klare Rufe als auch dichte Chöre zählte.
Was die Ergebnisse für den Naturschutz bedeuten
Für Nichtfachleute bedeuten diese Zahlen, dass der Detektor massive Archive durchforsten und nahezu alle Vorkommen eines bestimmten Walsongs zuverlässig markieren kann, mit vergleichsweise wenigen Fehlalarmen, selbst wenn er aus einer einzigen guten Aufnahme trainiert wurde. Das ist ein großer Schritt für die Erforschung wenig bekannter, bedrohten Arten, deren Laute nur selten aufgezeichnet werden. Die Autorinnen und Autoren warnen, dass der Erfolg von klaren Entscheidungen darüber abhängt, was als „Treffer" gilt – etwa ob sich überschneidende Chöre einbezogen werden sollen – und von einer sorgfältigen Gestaltung sowohl positiver als auch negativer Trainingsbeispiele. Sie heben außerdem hervor, dass selbst Expertenlabels fehlerbehaftet sind und bessere Standards zur Bewertung von Detektoren noch fehlen. Nichtsdestoweniger zeigt dieses Rahmenkonzept, dass sich mit cleverer Datenaugmentation und Transferlernen leistungsfähige Hörwerkzeuge für den Naturschutz kostengünstig erstellen und offen teilen lassen, was Forschenden hilft, die bereits in unseren globalen Akustikarchiven gespeicherten verborgenen Stimmen zu erschließen.
Zitation: Jancovich, B.A., Sanchez, V., Truong, G. et al. Automated detection of stereotyped animal sounds using data augmentation and transfer learning. Sci Rep 16, 13137 (2026). https://doi.org/10.1038/s41598-026-48308-6
Schlüsselwörter: passive akustische Überwachung, Lieder der Blauwale, Deep-Learning-Detektor, synthetische Trainingsdaten, Naturschutz