Clear Sky Science · en
Automated detection of stereotyped animal sounds using data augmentation and transfer learning
Listening to Hidden Voices in the Ocean
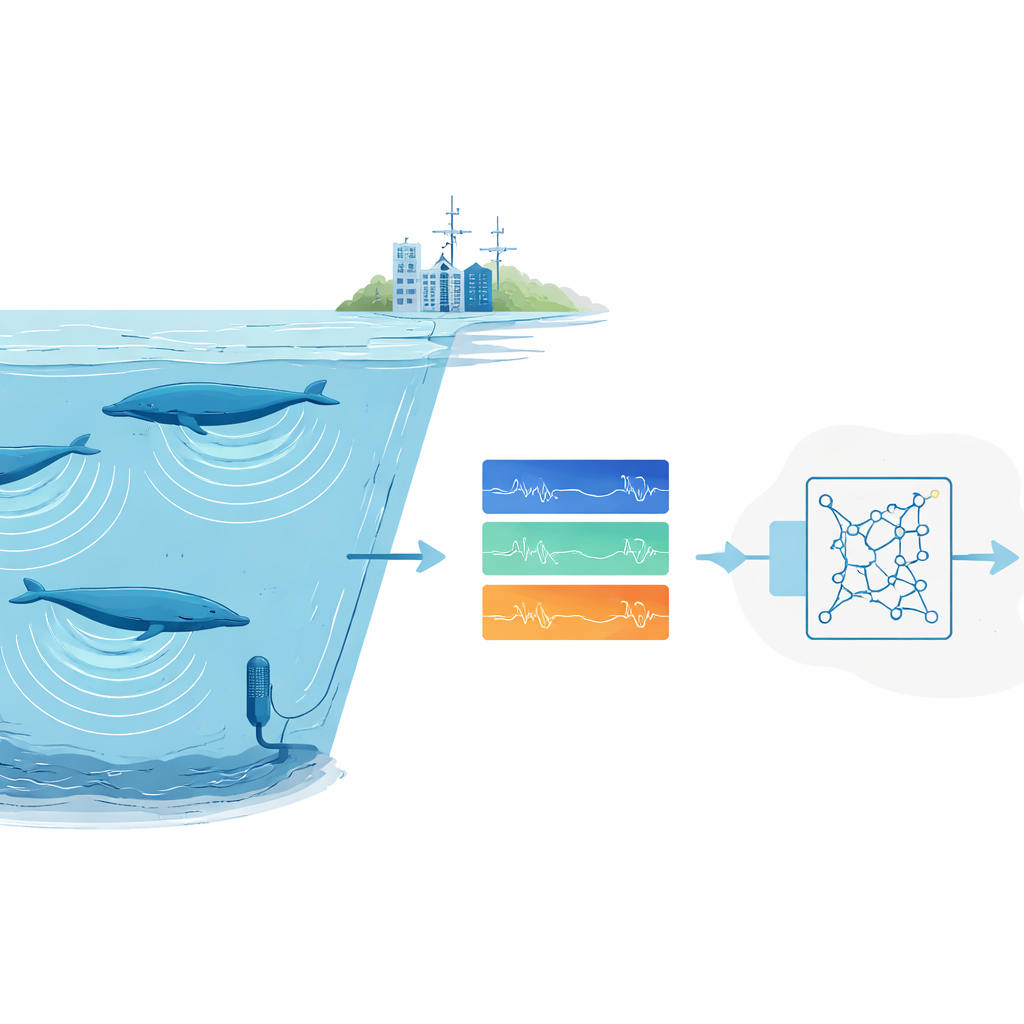
Across the world’s oceans, vast underwater microphones are quietly recording the soundscape: crashing waves, ship engines, cracking ice – and the deep songs of whales. Buried in these archives are clues about where endangered animals live, how many there are, and how they are coping with a changing planet. Yet there is simply too much audio for humans to sift through by eye and ear. This study introduces a new way to train an automated “listener” that can reliably pick out very stereotyped animal calls – such as certain blue whale songs – even when only a single good recording of that call exists.
Why Finding Animal Sounds Is So Hard
Scientists increasingly rely on passive acoustic monitoring: leaving recorders in the wild and later scanning the audio to find animal calls. For common or noisy species, modern deep-learning systems work well, but they demand thousands of labelled examples and powerful computers. That is a deal-breaker for rare or elusive animals whose calls have been recorded only a handful of times, and for research groups without access to large computing clusters. On top of this, ocean recordings are messy. Background noise from storms, ice, and ships can drown out calls, and human experts themselves often disagree about which faint markings in a spectrogram really belong to a whale.
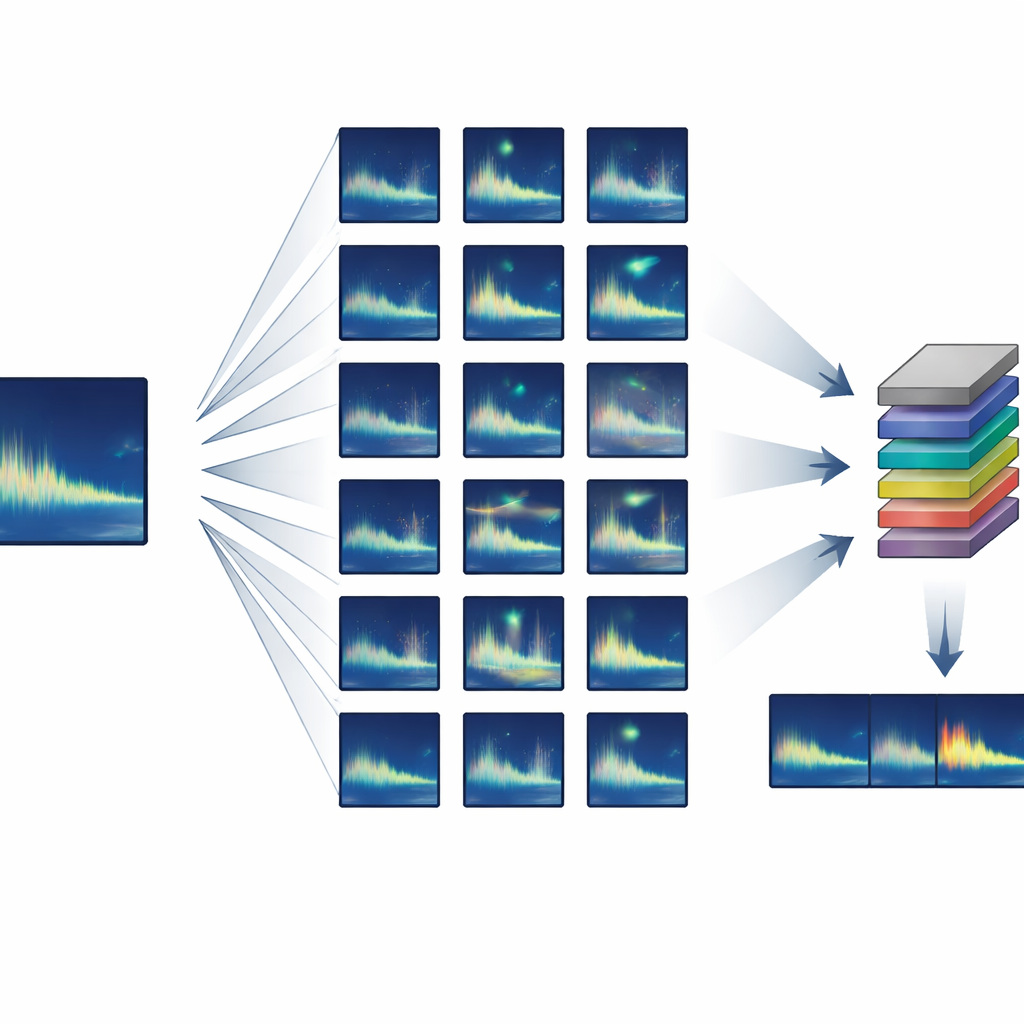
Building a Big Training Set from Almost Nothing
The authors focused on animals that produce highly repeatable, or “stereotyped”, calls – where every individual makes nearly the same sound. They developed a semi-synthetic training pipeline that starts from just one or a few clean examples of a target call and then creates thousands of realistic variants. Using standard audio processing, the system slightly stretches or compresses each call in time, shifts its pitch to mimic long-term changes in song, adds gentle distortions and echoes, and mixes it with real background noise from the ocean. Crucially, all of these changes are grounded in known whale behavior and sound propagation, so the synthetic calls still look and sound like something a real whale could have produced.
Reusing an Existing Neural Network
Instead of training a detector from scratch, the team used transfer learning: they began with a neural network originally designed to detect human speech and fine-tuned it for whale songs. This network treats sound as a series of short, overlapping spectrogram “frames” and includes recurrent layers that can follow patterns over time, allowing it to cope with calls of different lengths. Training used only consumer-grade hardware – a standard laptop with a modest graphics card – and completed in about five hours. Once trained, the system could scan four hours of ocean audio in roughly a minute and a half, including all pre- and post-processing.
Putting the Detector to the Test
The method was evaluated on two very different low-frequency calls from endangered blue whales: the simple, descending “Z-call” of Antarctic blue whales and the more complex, multi-part song of Chagos pygmy blue whales in the Indian Ocean. In both cases, the detector was trained entirely on semi-synthetic data. For one model, the training set was built from just a single real example of the Chagos song. To fairly judge performance, the authors did not rely blindly on existing “ground truth” annotation logs, which turned out to contain many missed calls. Instead, an experienced analyst manually reviewed thousands of disagreements between the detector and the logs. After this adjudication, the best Chagos model correctly found 99.4% of target calls with 91.2% precision, while the Antarctic model found 87% with 65% precision under inclusive scoring that counted both clear calls and dense choruses.
What the Results Mean for Conservation
To a non-specialist, these numbers mean that the detector can scan massive archives and reliably flag almost all occurrences of a given whale song, with relatively few false alarms, even when it was trained from a single good recording. That is a major step for studying little-known, threatened species whose sounds are rarely captured. The authors caution that success depends on clear choices about what counts as a “hit” – for example, whether overlapping choruses should be included – and on carefully designing both positive and negative training examples. They also highlight that even expert human labels are imperfect, and better standards for evaluating detectors are still needed. Nonetheless, this framework shows that with clever data augmentation and transfer learning, powerful listening tools for conservation can be built cheaply and shared openly, helping scientists unlock the hidden voices already stored in our global acoustic archives.
Citation: Jancovich, B.A., Sanchez, V., Truong, G. et al. Automated detection of stereotyped animal sounds using data augmentation and transfer learning. Sci Rep 16, 13137 (2026). https://doi.org/10.1038/s41598-026-48308-6
Keywords: passive acoustic monitoring, blue whale songs, deep learning detector, synthetic training data, wildlife conservation