Clear Sky Science · ru
Автоматическое обнаружение стереотипных звуков животных с помощью увеличения данных и переноса обучения
Слушая скрытые голоса океана
По всем океанам мира обширные подводные микрофоны тихо записывают звуковой ландшафт: разбивающиеся волны, двигатели кораблей, треск льда — и глубокие песни китов. В этих архивах скрыты подсказки о том, где обитают виды, находящиеся под угрозой, сколько их и как они справляются с меняющимся климатом. Но объём аудиозаписей слишком велик, чтобы люди могли прослушать всё вручную. В этом исследовании предложен новый способ обучения автоматического «слуха», который надёжно выделяет очень стереотипные звонки животных — например, определённые песни синих китов — даже когда имеется лишь одна хорошая запись такого сигнала.
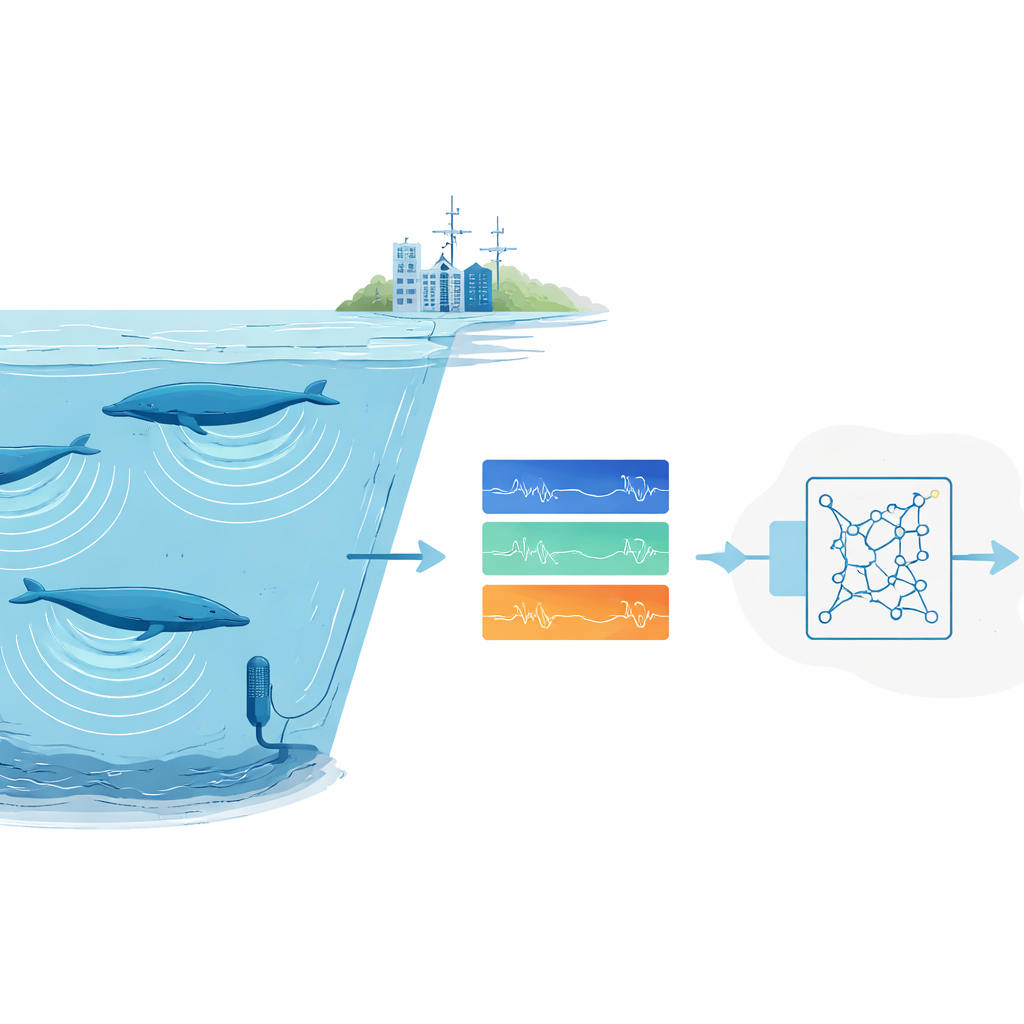
Почему найти звуки животных так сложно
Учёные всё чаще полагаются на пассивный акустический мониторинг: оставляют рекордеры в дикой природе и потом просматривают звукозаписи в поисках сигналов животных. Для обычных или громких видов современные системы глубокого обучения работают хорошо, но им требуются тысячи размеченных примеров и мощные компьютеры. Это становится непреодолимым препятствием для редких или скрытных видов, чьи звонки записаны лишь несколько раз, а также для исследовательских групп без доступа к крупным вычислительным кластерам. Дополнительно морские записи отличаются шумной фоновой обстановкой. Штормы, лёд и корабли могут заглушать сигналы, и эксперты часто спорят о том, какие слабые отметины на спектрограмме действительно принадлежат киту.
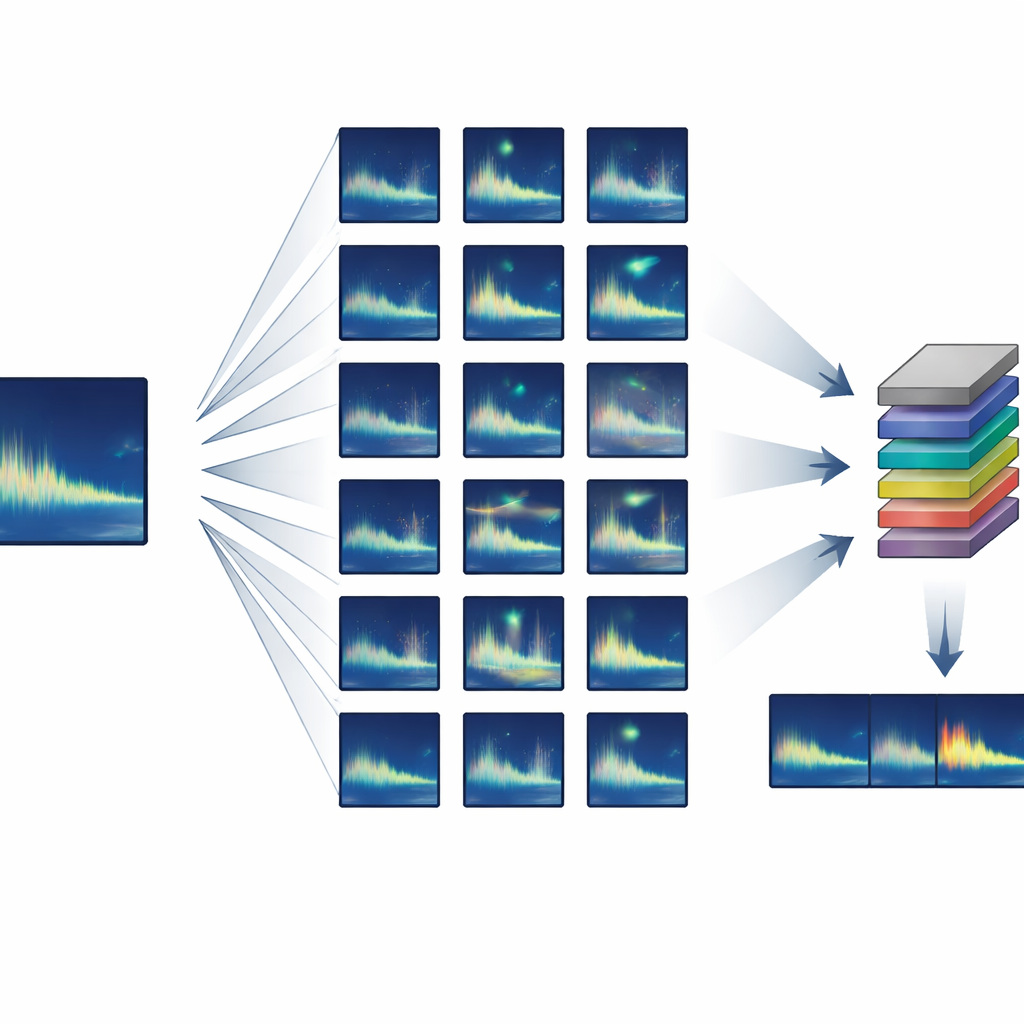
Построение большого обучающего набора из почти ничего
Авторы сосредоточились на животных, которые издают высоко воспроизводимые, или «стереотипные», сигналы — когда каждый индивидуум производит практически одинаковый звук. Они разработали полусинтетический конвейер подготовки данных, который стартует всего с одного-нескольких чистых примеров целевого сигнала и затем создаёт тысячи реалистичных вариантов. Используя стандартную обработку аудио, система слегка растягивает или сжимает сигнал во времени, смещает высоту тона, чтобы имитировать долгосрочные изменения песен, добавляет мягкие искажения и эхо, а затем смешивает это с реальным фоновым шумом океана. Критично то, что все эти преобразования основаны на известных особенностях поведения китов и распространения звука, поэтому синтетические сигналы по-прежнему выглядят и звучат так, как если бы их мог произвести настоящий кит.
Повторное использование существующей нейронной сети
Вместо обучения детектора с нуля команда использовала перенос обучения: они взяли нейронную сеть, изначально созданную для обнаружения речи человека, и дообучили её для распознавания китовых песен. Эта сеть трактует звук как последовательность коротких перекрывающихся фреймов спектрограммы и включает рекуррентные слои, которые могут отслеживать шаблоны во времени, что позволяет ей справляться с сигналами разной длины. Обучение велось на потребительском оборудовании — обычном ноутбуке с относительной компактной видеокартой — и заняло около пяти часов. После обучения система могла просканировать четыре часа океанской записи примерно за полторы минуты, включая все предварительные и последующие этапы обработки.
Испытание детектора
Метод был оценён на двух очень разных низкочастотных сигналах исчезающих синих китов: простом нисходящем «Z-звонке» антарктических синих китов и более сложной многокомпонентной песне карликовых чагосских синих китов в Индийском океане. В обоих случаях детектор обучали полностью на полусинтетических данных. Для одной модели обучающий набор был создан всего из одного реального примера чагосской песни. Чтобы объективно оценить производительность, авторы не полагались слепо на существующие журналы «истинной» разметки, которые оказались содержащими множество пропущенных сигналов. Вместо этого опытный аналитик вручную проверил тысячи расхождений между детектором и журналами. После такой проверки лучшая чагосская модель правильно обнаружила 99,4% целевых сигналов при точности 91,2%, тогда как антарктическая модель выявила 87% при точности 65% по более широким критериям, которые учитывали и чёткие сигналы, и плотные хоры.
Что эти результаты означают для охраны природы
Для неспециалиста эти цифры означают, что детектор способен просканировать огромные архивы и надёжно помечать почти все появления заданной китовой песни с относительно небольшим числом ложных тревог, даже если он обучен на одной хорошей записи. Это большой шаг вперёд для изучения слабо известных, находящихся под угрозой видов, звуки которых редко фиксируются. Авторы предупреждают, что успех зависит от ясности в определении того, что считать «попаданием» — например, следует ли включать перекрывающиеся хоры — и от тщательной разработки как положительных, так и отрицательных обучающих примеров. Они также подчёркивают, что даже экспертная разметка несовершенна, и всё ещё нужны лучшие стандарты для оценки детекторов. Тем не менее представленная структура показывает, что с помощью грамотного увеличения данных и переноса обучения можно дешево создать и открыто распространять мощные инструменты для прослушивания в интересах сохранения природы, помогая учёным раскрывать скрытые голоса, уже хранящиеся в наших глобальных акустических архивах.
Цитирование: Jancovich, B.A., Sanchez, V., Truong, G. et al. Automated detection of stereotyped animal sounds using data augmentation and transfer learning. Sci Rep 16, 13137 (2026). https://doi.org/10.1038/s41598-026-48308-6
Ключевые слова: пассивный акустический мониторинг, песни синих китов, детектор на основе глубокого обучения, синтетические обучающие данные, сохранение дикой природы