Clear Sky Science · it
Rilevamento automatizzato di suoni animali stereotipati usando aumentazione dei dati e transfer learning
Ascoltare voci nascoste nell’oceano
Negli oceani del mondo, grandi microfoni subacquei registrano silenziosamente il paesaggio sonoro: onde che si infrangono, motori delle navi, ghiaccio che scricchiola – e i canti profondi delle balene. Sepolti in questi archivi ci sono indizi su dove vivono specie in pericolo, quante individui ci sono e come si stanno adattando a un pianeta che cambia. Tuttavia, c’è semplicemente troppo audio perché gli esseri umani possano setacciarlo visivamente o con l’orecchio. Questo studio introduce un nuovo modo per addestrare un “ascoltatore” automatizzato in grado di individuare in modo affidabile chiamate animali molto stereotipate – come alcuni canti della balena azzurra – anche quando esiste soltanto una singola buona registrazione di quella chiamata.
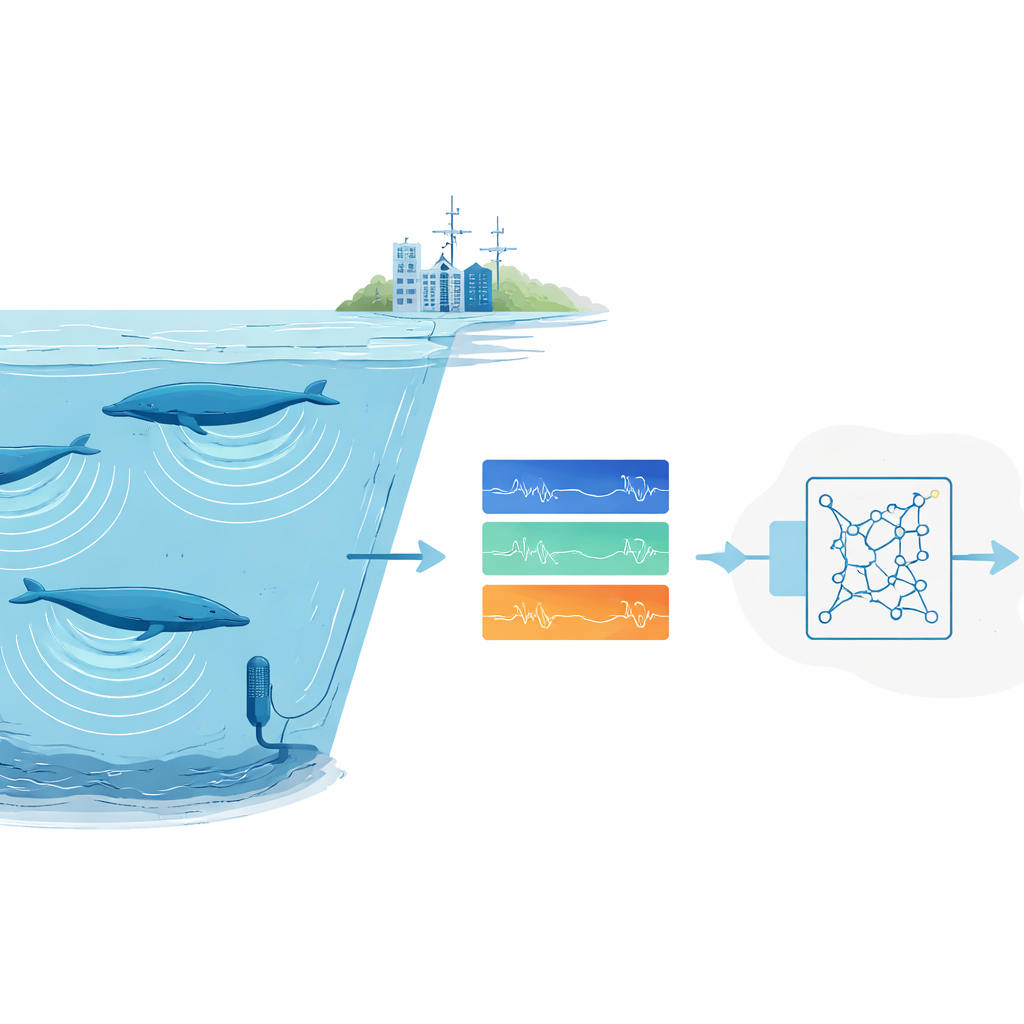
Perché trovare i suoni degli animali è così difficile
Gli scienziati si affidano sempre più al monitoraggio acustico passivo: lasciare registratori in natura e poi analizzare l’audio per trovare le chiamate degli animali. Per specie comuni o rumorose, i moderni sistemi di deep learning funzionano bene, ma richiedono migliaia di esempi etichettati e computer molto potenti. Questo è un problema per specie rare o elusive le cui chiamate sono state registrate poche volte, e per gruppi di ricerca senza accesso a grandi cluster di calcolo. Inoltre, le registrazioni oceaniche sono disordinate. Il rumore di fondo dovuto a tempeste, ghiaccio e navi può sovrastare le chiamate, e gli esperti umani spesso non sono d’accordo su quali deboli marcature in uno spettrogramma appartengano davvero a una balena.
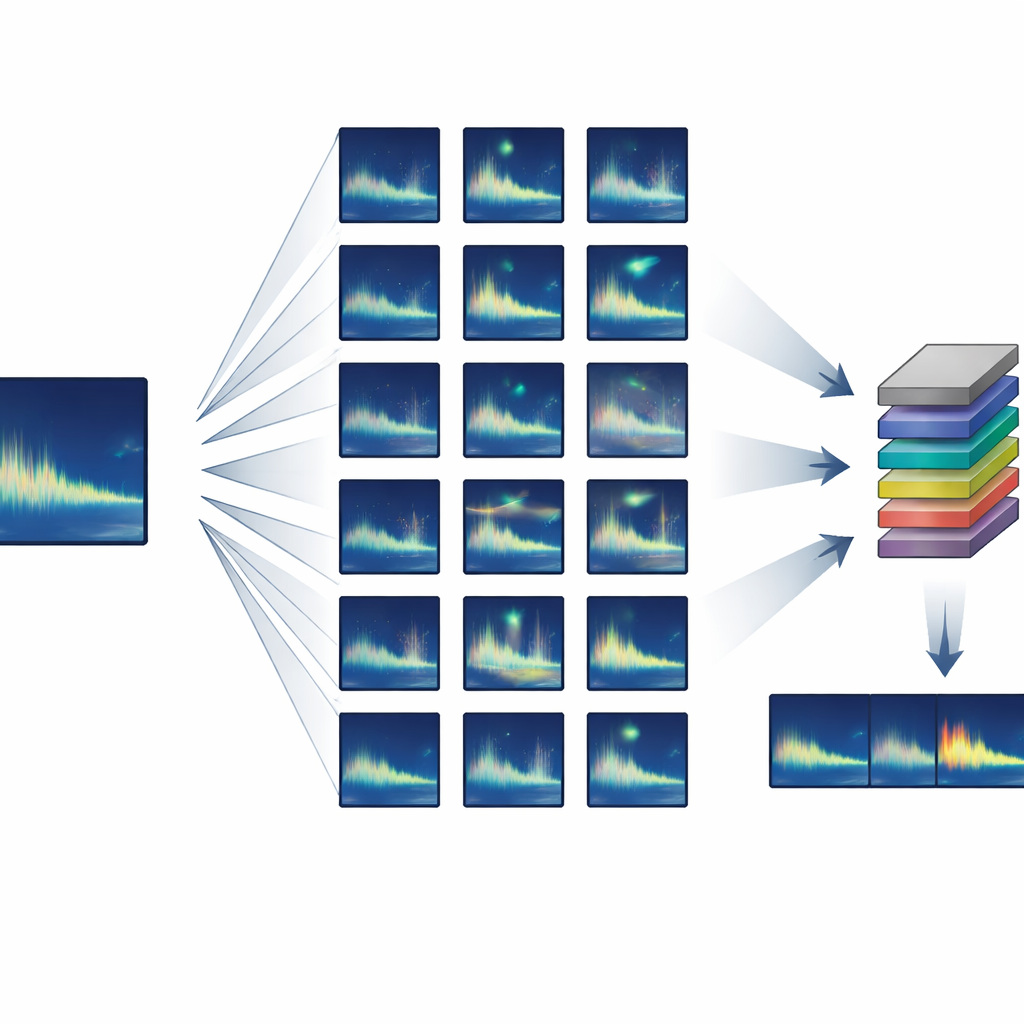
Costruire un grande set di addestramento partendo da quasi nulla
Gli autori si sono concentrati su animali che producono chiamate altamente ripetitive, o “stereotipate”, in cui ogni individuo emette suoni quasi identici. Hanno sviluppato una pipeline di addestramento semi-sintetica che parte da una sola o poche buone registrazioni pulite di una chiamata bersaglio e poi crea migliaia di varianti realistiche. Usando tecniche standard di elaborazione audio, il sistema allunga o comprime leggermente ogni chiamata nel tempo, sposta la frequenza per imitare cambiamenti di lunga durata nel canto, aggiunge leggere distorsioni ed echi e la miscela con rumore di fondo reale dell’oceano. Fondamentale è che tutte queste modifiche si basano su comportamenti noti delle balene e sulla propagazione del suono, quindi le chiamate sintetiche continuano a somigliare a qualcosa che una vera balena potrebbe aver prodotto.
Riutilare una rete neurale esistente
Invece di addestrare un rilevatore da zero, il team ha usato il transfer learning: ha iniziato con una rete neurale progettata originariamente per rilevare il parlato umano e l’ha adattata ai canti delle balene. Questa rete tratta il suono come una serie di brevi “frame” di spettrogramma sovrapposti e include strati ricorrenti che possono seguire i pattern nel tempo, permettendole di gestire chiamate di diverse durate. L’addestramento è avvenuto usando solo hardware di consumo – un portatile standard con una scheda grafica modesta – e si è completato in circa cinque ore. Una volta addestrato, il sistema poteva scansionare quattro ore di audio oceanico in circa un minuto e mezzo, includendo tutto il pre- e post-processing.
Mettere il rilevatore alla prova
Il metodo è stato valutato su due chiamate a bassa frequenza molto diverse provenienti da balene azzurre in pericolo: la semplice e discendente “Z-call” delle balene azzurre dell’Antartide e il canto più complesso e articolato della balena azzurra nana di Chagos nell’Oceano Indiano. In entrambi i casi, il rilevatore è stato addestrato interamente su dati semi-sintetici. Per un modello, il set di addestramento è stato costruito a partire da una sola registrazione reale del canto di Chagos. Per valutare equamente le prestazioni, gli autori non si sono affidati ciecamente ai registri di annotazione “ground truth” esistenti, che si sono rivelati contenere molte chiamate mancanti. Invece, un analista esperto ha riesaminato manualmente migliaia di disaccordi tra il rilevatore e i registri. Dopo questa aggiudicazione, il miglior modello di Chagos ha trovato correttamente il 99,4% delle chiamate bersaglio con una precisione del 91,2%, mentre il modello antartico ha identificato l’87% con il 65% di precisione usando una valutazione inclusiva che contava sia chiamate chiare sia cori densi.
Cosa significano i risultati per la conservazione
Per un non specialista, questi numeri indicano che il rilevatore può scandire archivi enormi e segnalare in modo affidabile quasi tutte le occorrenze di un dato canto di balena, con relativamente pochi falsi allarmi, anche quando è stato addestrato a partire da una singola buona registrazione. Questo rappresenta un passo importante per lo studio di specie minacciate poco conosciute i cui suoni sono raramente catturati. Gli autori avvertono però che il successo dipende da scelte chiare su cosa contare come “hit” – per esempio, se includere cori sovrapposti – e dalla progettazione attenta sia di esempi positivi sia negativi per l’addestramento. Sottolineano inoltre che anche le etichette fornite da esperti sono imperfette e che sono ancora necessari standard migliori per valutare i rilevatori. Nonostante ciò, questo quadro dimostra che con una intelligente aumentazione dei dati e il transfer learning è possibile costruire strumenti di ascolto potenti per la conservazione in modo economico e condivisibile, aiutando gli scienziati a svelare le voci nascoste già conservate nei nostri archivi acustici globali.
Citazione: Jancovich, B.A., Sanchez, V., Truong, G. et al. Automated detection of stereotyped animal sounds using data augmentation and transfer learning. Sci Rep 16, 13137 (2026). https://doi.org/10.1038/s41598-026-48308-6
Parole chiave: monitoraggio acustico passivo, canti della balena azzurra, rilevatore deep learning, dati di addestramento sintetici, conservazione della fauna selvatica