Clear Sky Science · pt
Detecção automatizada de sons animais estereotipados usando aumento de dados e transferência de aprendizado
Ouvindo vozes ocultas no oceano
Por todos os oceanos do mundo, vastos microfones subaquáticos gravam silenciosamente a paisagem sonora: ondas quebrando, motores de navios, gelo estalando – e as canções profundas das baleias. Enterrados nesses arquivos estão indícios sobre onde animais em risco vivem, quantos existem e como estão lidando com um planeta em mudança. Ainda assim, há simplesmente áudio demais para que humanos o examinem visual e auditivamente. Este estudo apresenta uma nova forma de treinar um “ouvinte” automatizado que pode identificar com confiança chamadas animais muito estereotipadas – como certas canções de baleia azul – mesmo quando existe apenas uma única boa gravação dessa chamada.
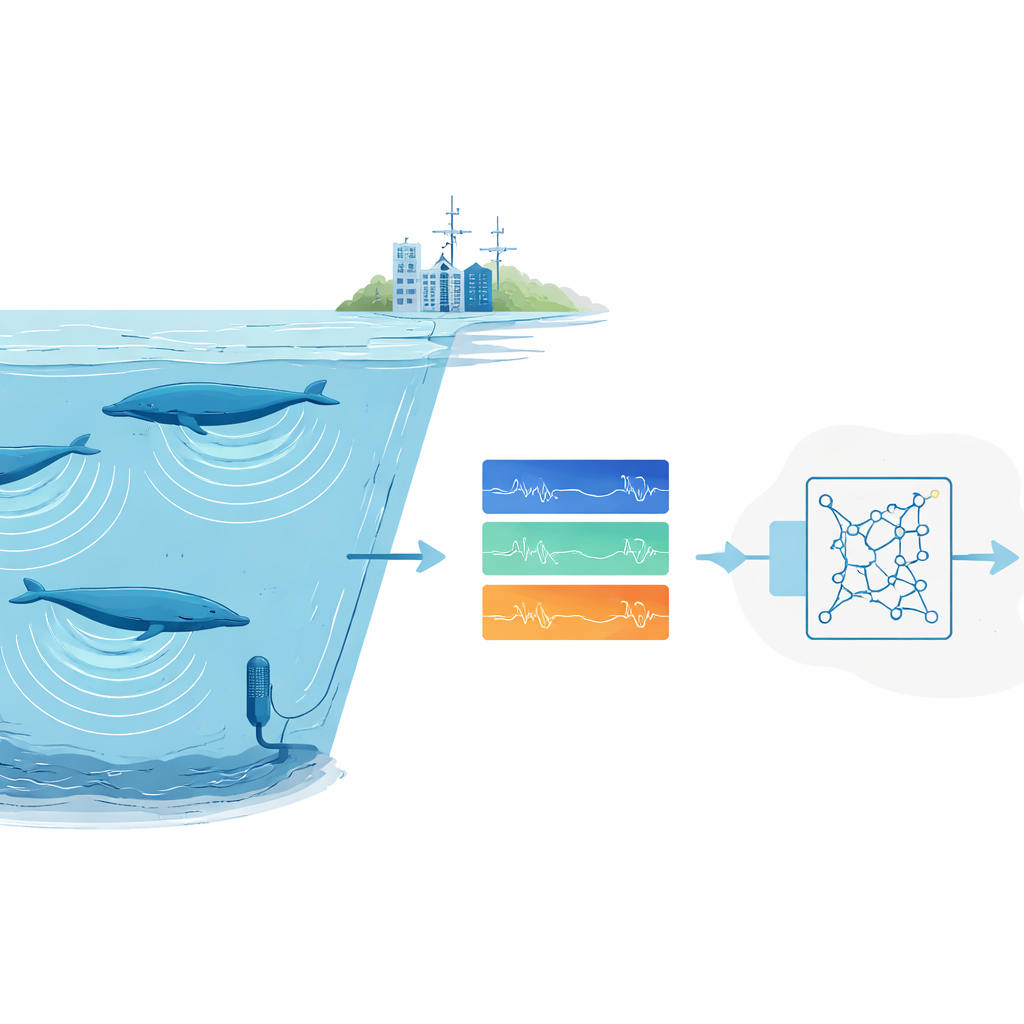
Por que encontrar sons de animais é tão difícil
Cientistas dependem cada vez mais do monitoramento acústico passivo: deixarem gravadores na natureza e, depois, vasculharem o áudio para encontrar chamadas animais. Para espécies comuns ou ruidosas, sistemas modernos de aprendizado profundo funcionam bem, mas exigem milhares de exemplos rotulados e computadores potentes. Isso é um impeditivo para animais raros ou elusivos cujas chamadas foram registradas apenas algumas vezes, e para grupos de pesquisa sem acesso a grandes clusters de computação. Além disso, gravações oceânicas são confusas. Ruído de fundo de tempestades, gelo e navios pode encobrir chamadas, e especialistas humanos frequentemente discordam sobre quais marcas tênues em um espectrograma realmente pertencem a uma baleia.
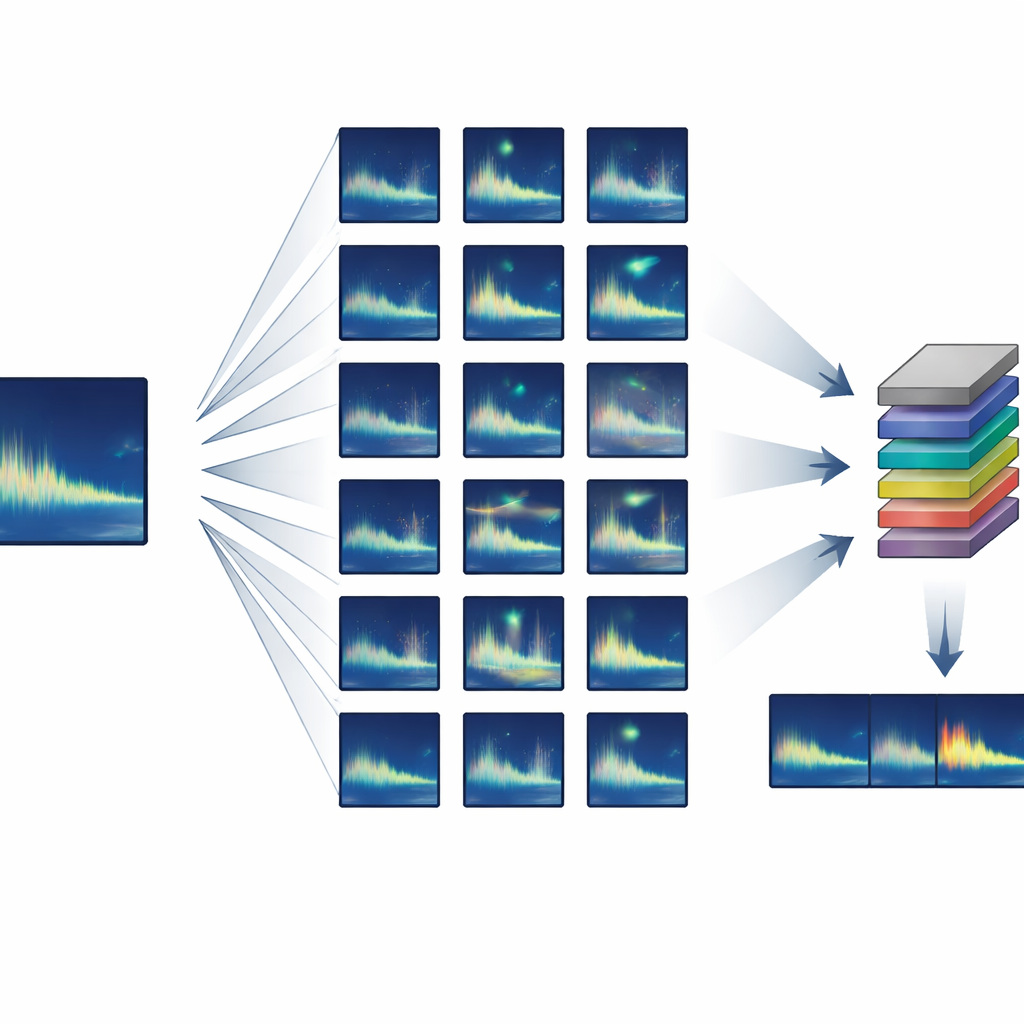
Construindo um grande conjunto de treinamento a partir de quase nada
Os autores concentraram-se em animais que produzem chamadas altamente repetíveis, ou “estereotipadas” – em que cada indivíduo emite quase o mesmo som. Eles desenvolveram um pipeline de treinamento semi-sintético que parte de apenas um ou alguns exemplos limpos de uma chamada-alvo e então cria milhares de variantes realistas. Usando processamento de áudio padrão, o sistema alonga ou comprime ligeiramente cada chamada no tempo, desloca sua afinação para imitar mudanças de longo prazo na canção, adiciona distorções suaves e ecos, e mistura com ruído de fundo real do oceano. Crucialmente, todas essas alterações são fundamentadas em comportamentos conhecidos de baleias e na propagação do som, de modo que as chamadas sintéticas ainda parecem e soam como algo que uma baleia real poderia ter produzido.
Reaproveitando uma rede neural existente
Em vez de treinar um detector do zero, a equipe usou transferência de aprendizado: começaram com uma rede neural originalmente projetada para detectar fala humana e a ajustaram para canções de baleia. Essa rede trata o som como uma sequência de “quadros” de espectrograma curtos e sobrepostos e inclui camadas recorrentes capazes de seguir padrões ao longo do tempo, permitindo que lide com chamadas de diferentes durações. O treinamento utilizou apenas hardware de consumo – um laptop padrão com uma placa gráfica modesta – e foi concluído em cerca de cinco horas. Uma vez treinado, o sistema podia escanear quatro horas de áudio oceânico em aproximadamente um minuto e meio, incluindo todo o pré e pós-processamento.
Colocando o detector à prova
O método foi avaliado em duas chamadas de baixa frequência muito diferentes de baleias-azuis ameaçadas: a simples e descendente “Z-call” das baleias-azuis antárticas e a canção mais complexa e multipartida das baleias-azuis pigmeias de Chagos, no Oceano Índico. Em ambos os casos, o detector foi treinado inteiramente com dados semi-sintéticos. Para um modelo, o conjunto de treinamento foi construído a partir de apenas um exemplo real da canção de Chagos. Para julgar o desempenho de forma justa, os autores não confiaram cegamente em registros de anotação “verdadeiros” existentes, que se mostraram conter muitas chamadas perdidas. Em vez disso, um analista experiente revisou manualmente milhares de discordâncias entre o detector e os registros. Após essa adjudicação, o melhor modelo de Chagos encontrou corretamente 99,4% das chamadas-alvo com 91,2% de precisão, enquanto o modelo antártico encontrou 87% com 65% de precisão sob uma pontuação inclusiva que contou tanto chamadas claras quanto coros densos.
O que os resultados significam para a conservação
Para um não especialista, esses números significam que o detector pode vasculhar arquivos massivos e sinalizar de forma confiável quase todas as ocorrências de uma dada canção de baleia, com relativamente poucos alarmes falsos, mesmo quando foi treinado a partir de uma única boa gravação. Isso é um grande avanço para o estudo de espécies pouco conhecidas e ameaçadas cujos sons são raramente capturados. Os autores avisam que o sucesso depende de escolhas claras sobre o que conta como um “acerto” – por exemplo, se coros sobrepostos devem ser incluídos – e de projetar cuidadosamente exemplos positivos e negativos de treinamento. Eles também destacam que mesmo rótulos humanos de especialistas são imperfeitos, e que padrões melhores para avaliar detectores ainda são necessários. Ainda assim, essa estrutura mostra que, com aumento de dados inteligente e transferência de aprendizado, ferramentas de escuta poderosas para a conservação podem ser construídas de forma barata e compartilhadas abertamente, ajudando cientistas a desbloquear as vozes ocultas já armazenadas em nossos arquivos acústicos globais.
Citação: Jancovich, B.A., Sanchez, V., Truong, G. et al. Automated detection of stereotyped animal sounds using data augmentation and transfer learning. Sci Rep 16, 13137 (2026). https://doi.org/10.1038/s41598-026-48308-6
Palavras-chave: monitoramento acústico passivo, canções de baleia azul, detector de aprendizado profundo, dados sintéticos de treinamento, conservação da vida selvagem