Clear Sky Science · pl
Zautomatyzowane wykrywanie stereotypowych dźwięków zwierząt z użyciem augmentacji danych i transferu wiedzy
Słuchając ukrytych głosów w oceanie
Na oceanach całego świata olbrzymie podwodne mikrofony cicho rejestrują krajobraz dźwiękowy: rozbijające się fale, silniki statków, pękający lód – i głębokie pieśni wielorybów. W tych archiwach ukryte są wskazówki mówiące, gdzie żyją zagrożone gatunki, ile ich jest i jak radzą sobie w zmieniającym się świecie. Jest jednak po prostu za dużo nagrań, by ludzie mogli przeglądać je wzrokiem i uchem. W tym badaniu przedstawiono nowy sposób trenowania zautomatyzowanego „słuchacza”, który potrafi wiarygodnie wyłapywać bardzo stereotypowe sygnały zwierzęce – na przykład niektóre pieśni płetwali błękitnych – nawet gdy istnieje tylko jedno dobre nagranie takiego sygnału.
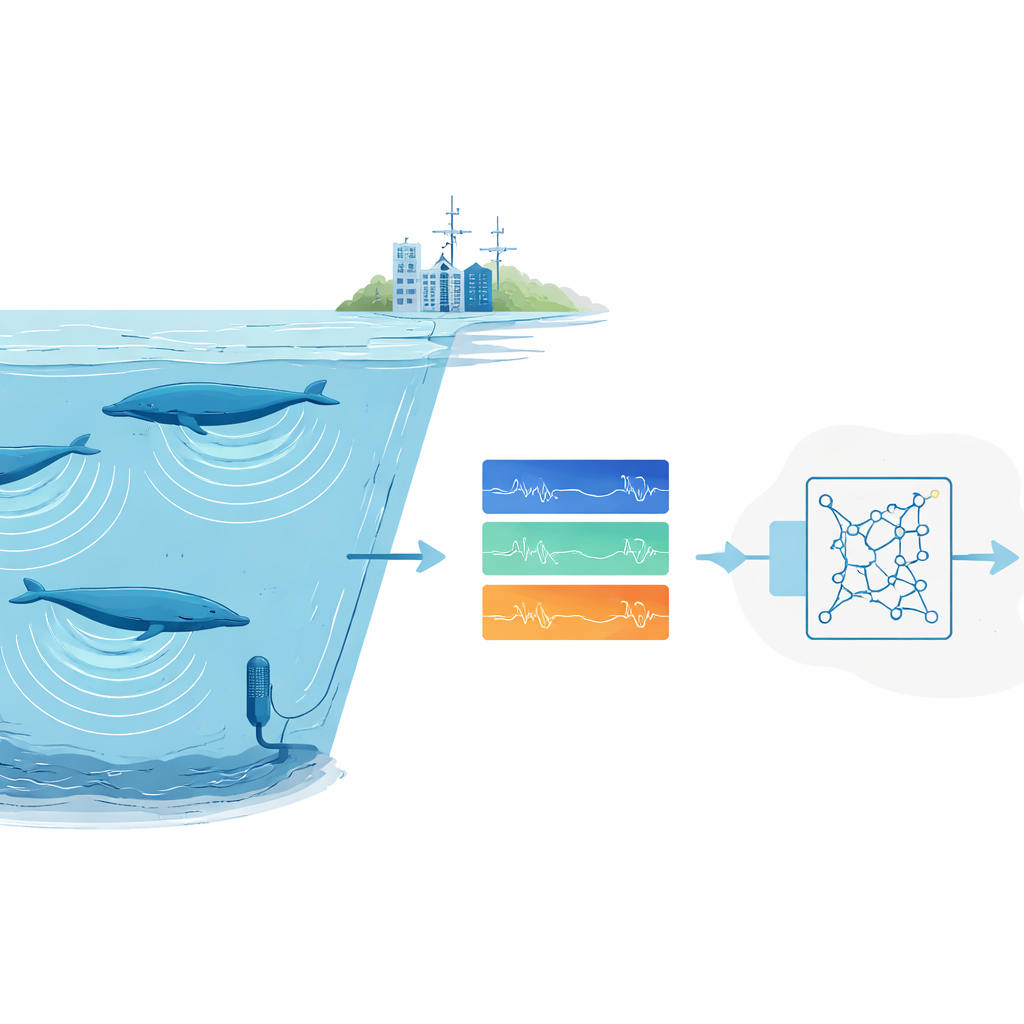
Dlaczego znalezienie dźwięków zwierząt jest takie trudne
Naukowcy coraz częściej polegają na pasywnym monitorowaniu akustycznym: pozostawiają rejestratory w terenie i później skanują nagrania, by odnaleźć odgłosy zwierząt. Dla pospolitych lub głośnych gatunków nowoczesne systemy głębokiego uczenia działają dobrze, ale wymagają tysięcy oznaczonych przykładów i wydajnych komputerów. To staje się barierą dla rzadkich lub trudnych do zaobserwowania gatunków, których odgłosy zarejestrowano tylko kilka razy, oraz dla zespołów badawczych bez dostępu do dużych klastrów obliczeniowych. Na dodatek nagrania oceaniczne są zanieczyszczone. Szumy tła pochodzące od burz, lodu i statków mogą zagłuszać sygnały, a sami eksperci często nie zgadzają się, które słabe oznaczenia w spektrogramie naprawdę należą do wieloryba.
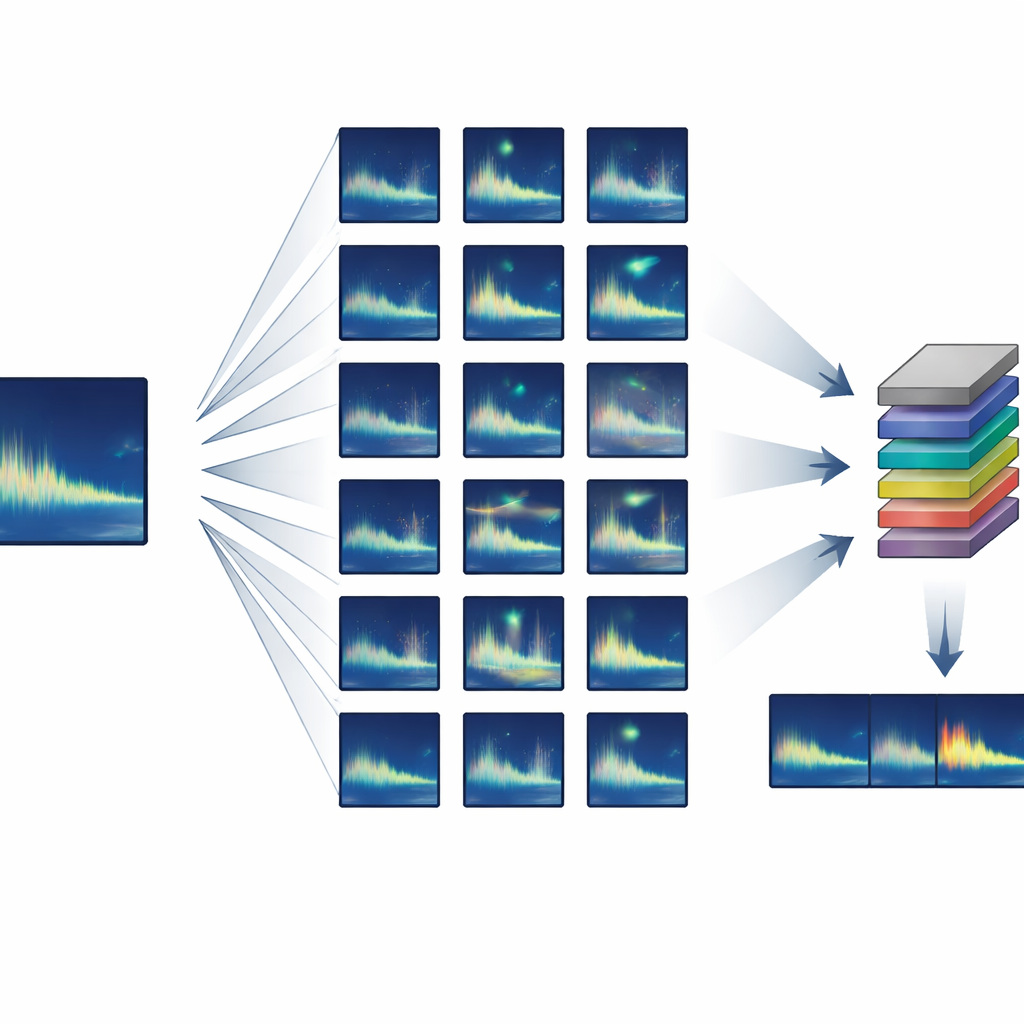
Budowanie dużego zbioru treningowego z niemal niczego
Autorzy skupili się na zwierzętach wydających wysoce powtarzalne, czyli „stereotypowe”, odgłosy – gdzie każda osobnik wydaje niemal identyczny dźwięk. Opracowali półsyntetyczny proces tworzenia danych treningowych, który zaczyna się od zaledwie jednego lub kilku czystych przykładów docelowego sygnału, a następnie tworzy tysiące realistycznych wariantów. Korzystając ze standardowego przetwarzania dźwięku, system nieco rozciąga lub kompresuje każdy sygnał w czasie, przesuwa jego wysokość tonu, by naśladować długoterminowe zmiany pieśni, dodaje łagodne zniekształcenia i echa oraz miesza go z rzeczywistym szumem tła z oceanu. Co kluczowe, wszystkie te zmiany opierają się na znanym zachowaniu wielorybów i propagacji dźwięku, dzięki czemu syntetyczne sygnały nadal wyglądają i brzmią jak coś, co mógł wyprodukować prawdziwy wieloryb.
Wykorzystanie istniejącej sieci neuronowej
Zamiast trenować detektor od podstaw, zespół zastosował transfer learning: rozpoczął od sieci neuronowej pierwotnie zaprojektowanej do wykrywania mowy ludzkiej i dostroił ją do pieśni wielorybów. Sieć traktuje dźwięk jako serię krótkich, nachodzących na siebie „ram” spektrogramu i zawiera warstwy rekurencyjne, które potrafią śledzić wzorce w czasie, co pozwala jej radzić sobie z odgłosami o różnych długościach. Trenowanie odbyło się na sprzęcie konsumenckim – standardowym laptopie z umiarkowanej klasy kartą graficzną – i zakończyło się w około pięć godzin. Po wytrenowaniu system był w stanie przeskanować cztery godziny nagrań oceanicznych w około półtorej minuty, uwzględniając całe przetwarzanie wstępne i końcowe.
Testy detektora
Metodę oceniono na dwóch bardzo różnych niskoczęstotliwościowych sygnałach od zagrożonych płetwali błękitnych: prostym, opadającym „Z-call” płetwali antarktycznych oraz bardziej złożonej, wieloczęściowej pieśni karłowatego płetwala z Chagos na Oceanie Indyjskim. W obu przypadkach detektor trenowano wyłącznie na danych półsyntetycznych. W jednym modelu zbiór treningowy zbudowano zaledwie z jednego rzeczywistego przykładu pieśni z Chagos. Aby uczciwie ocenić skuteczność, autorzy nie polegali ślepo na istniejących dziennikach „prawdy ziemi”, które okazały się zawierać wiele pominiętych wywołań. Zamiast tego doświadczony analityk ręcznie przejrzał tysiące rozbieżności między detektorem a zapisami. Po tej rozstrzygającej weryfikacji najlepszy model dla Chagos poprawnie odnalazł 99,4% docelowych sygnałów przy precyzji 91,2%, podczas gdy model antarktyczny odnalazł 87% przy precyzji 65% według inkluzywnego sposobu punktacji, który liczył zarówno wyraźne sygnały, jak i gęste chóry.
Co wyniki oznaczają dla ochrony przyrody
Dla osoby niebędącej specjalistą liczby te oznaczają, że detektor może przeskanować olbrzymie archiwa i wiarygodnie oznaczyć niemal wszystkie wystąpienia danej pieśni wieloryba, przy stosunkowo niewielkiej liczbie fałszywych alarmów, nawet jeśli trenowano go na podstawie jednego dobrego nagrania. To znaczący krok w badaniu słabo poznanych, zagrożonych gatunków, których dźwięki rzadko bywają zapisywane. Autorzy zastrzegają, że sukces zależy od jasnych ustaleń, co liczyć jako „trafienie” – na przykład, czy obejmować nakładające się chóry – oraz od starannego projektowania zarówno pozytywnych, jak i negatywnych przykładów treningowych. Podkreślają też, że nawet eksperckie etykiety ludzkie są niedoskonałe i potrzebne są lepsze standardy oceny detektorów. Niemniej ramy te pokazują, że dzięki sprytnej augmentacji danych i transferowi wiedzy można tanio zbudować potężne narzędzia słuchowe dla ochrony przyrody i udostępnić je otwarcie, pomagając naukowcom odblokować ukryte głosy już zgromadzone w globalnych archiwach akustycznych.
Cytowanie: Jancovich, B.A., Sanchez, V., Truong, G. et al. Automated detection of stereotyped animal sounds using data augmentation and transfer learning. Sci Rep 16, 13137 (2026). https://doi.org/10.1038/s41598-026-48308-6
Słowa kluczowe: pasywne monitorowanie akustyczne, pieśni płetwali błękitnych, detektor oparty na głębokim uczeniu, syntetyczne dane treningowe, ochrona dzikiej przyrody