Clear Sky Science · ar
الكشف الآلي عن أصوات الحيوانات النمطية باستخدام زيادة البيانات والتعلّم بالنقل
الاستماع إلى الأصوات الخفية في المحيط
عبر محيطات العالم، تسجل ميكروفونات تحت الماء بهدوء المشهد الصوتي: أمواج متلاطمة، محركات سفن، تشقق الجليد — وأغاني الحيتان العميقة. تُخزن في هذه الأرشيفات دلائل حول أماكن تواجد الحيوانات المهددة، وعددها، وكيف تتأقلم مع كوكب متغير. ومع ذلك، هناك كمية هائلة من الصوت تفوق قدرة البشر على فحصها بالعين والأذن. تقدم هذه الدراسة طريقة جديدة لتدريب «مستمع» آلي يمكنه تمييز نداءات حيوانية نمطية جداً — مثل بعض أغاني الحوت الأزرق — حتى عندما يتوافر تسجيل جيد واحد فقط لذلك النداء.
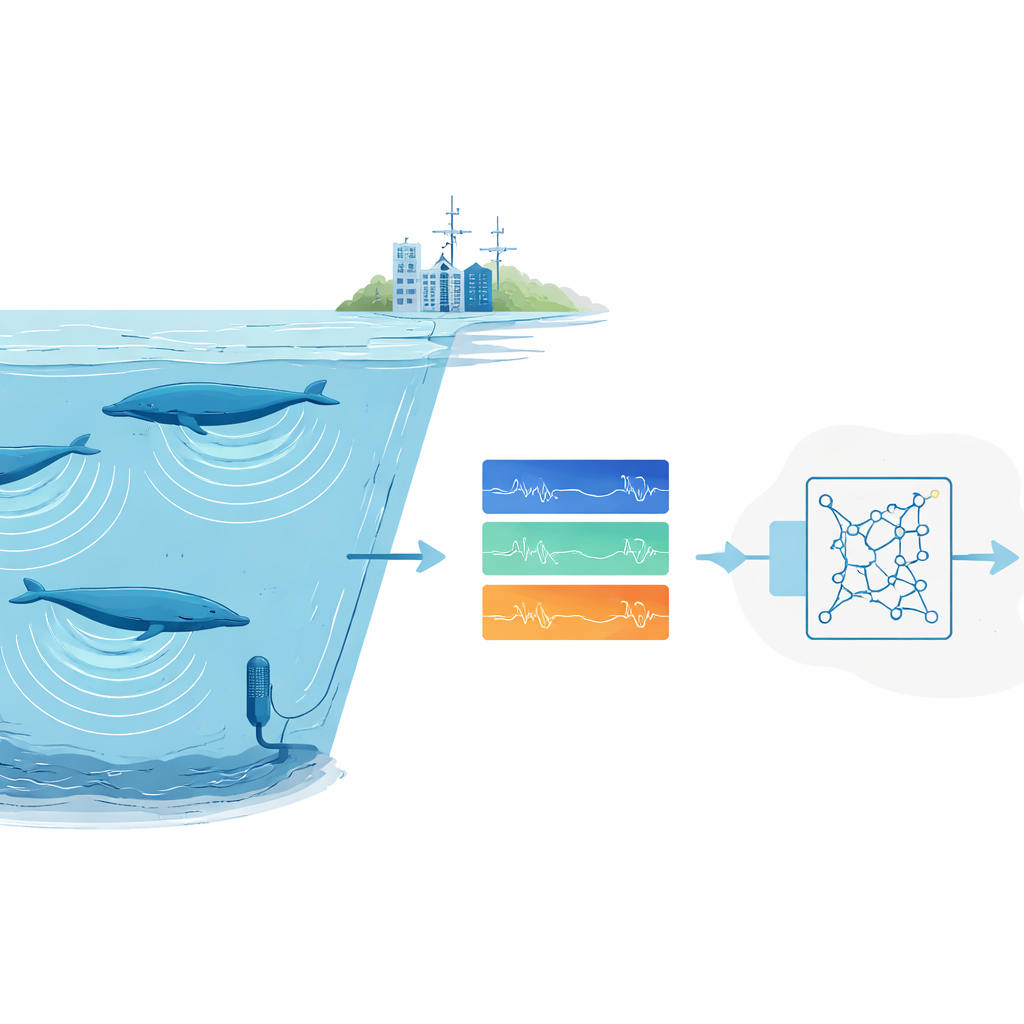
لماذا العثور على أصوات الحيوانات صعب للغاية
يعتمد العلماء بشكل متزايد على المراقبة الصوتية السلبية: ترك مسجلات في البرية ثم فحص الصوت لاحقاً للعثور على نداءات الحيوانات. بالنسبة للأنواع الشائعة أو الصاخبة، تعمل أنظمة التعلم العميق الحديثة جيداً، لكنها تتطلب آلاف الأمثلة المصنفة وحواسيب قوية. هذا يمثل عائقاً للأنواع النادرة أو المراوغة التي سُجلت نداءاتها مرات قليلة فقط، وللمجموعات البحثية التي لا تملك وصولاً إلى عناقيد حوسبة كبيرة. علاوة على ذلك، تسجيلات المحيط فوضوية. يمكن أن تطمر الضوضاء الخلفية الناتجة عن العواصف والجليد والسفن الأصوات، وغالباً ما يختلف خبراء البشر فيما بينهم حول أي العلامات الخافتة في مخطط الطيف تنتمي فعلاً إلى حوت.
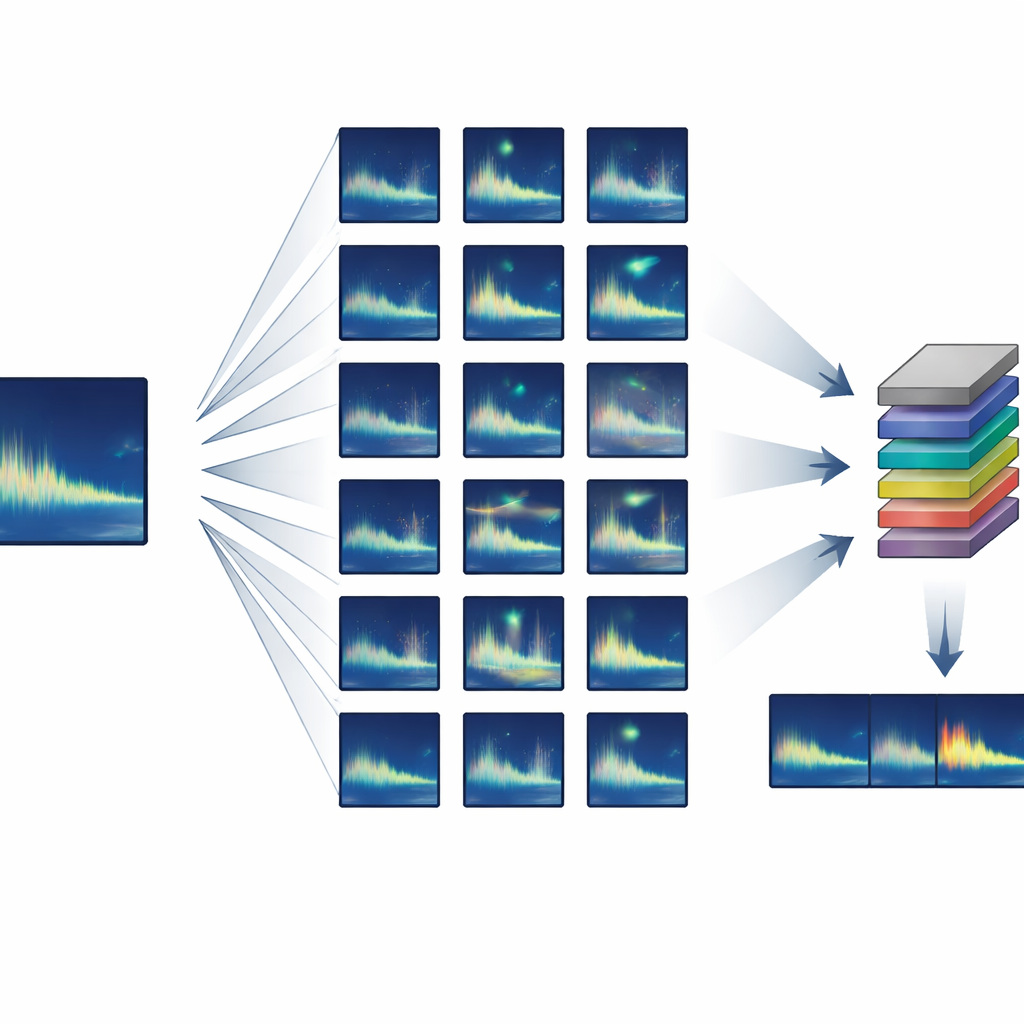
بناء مجموعة تدريب كبيرة من لا شيء تقريباً
ركز المؤلفون على الحيوانات التي تُنتج نداءات متكررة للغاية، أو «نمطية» — حيث يُصدر كل فرد تقريباً نفس الصوت. طوروا خطاً لنشر تدريب شبه اصطناعي يبدأ من مثال نظيف واحد أو بضعة أمثلة للنداء المستهدف ثم يخلق آلاف المتغيرات الواقعية. باستخدام معالجة صوتية قياسية، يُطيل أو يُقصر النظام كل نداء قليلاً في الزمن، ويغير طبقه لمحاكاة التغيرات الطويلة الأمد في الأغنية، ويضيف تشويهات خفيفة وصدى، ويمزجه مع ضوضاء خلفية حقيقية من المحيط. والأهم أن كل هذه التعديلات مبنية على سلوكيات الحيتان المعروفة وانتشار الصوت، لذا تبقى النداءات الاصطناعية تبدو وتسمع كما لو أن حوتاً حقيقياً قد أصدرها.
إعادة استخدام شبكة عصبية موجودة
بدلاً من تدريب كاشف من الصفر، استخدم الفريق التعلّم بالنقل: بدأوا بشبكة عصبية صممت أصلاً لاكتشاف الكلام البشري وقاموا بضبطها لتناسب أغاني الحيتان. تعالج هذه الشبكة الصوت كسلسلة من «إطارات» قصيرة متداخلة في مخططات الطيف وتضم طبقات متكررة يمكنها متابعة الأنماط مع مرور الزمن، مما يتيح لها التعامل مع نداءات ذات أطوال مختلفة. استُخدم للتدريب جهاز حاسوب استهلاكي — حاسوب محمول عادي ببطاقة رسوميات متواضعة — واستغرق التدريب نحو خمس ساعات. وبمجرد التدريب، تمكن النظام من فحص أربع ساعات من صوت المحيط في نحو دقيقة ونصف تقريباً، شاملاً كل المعالجات المسبقة واللاحقة.
اختبار الكاشف
قُيِّمت الطريقة على ندائين منخفضَي التردد مختلفين تماماً من الحيتان الزرقاء المهددة: النداء البسيط المتنازل «نداء Z» للحيتان الزرقاء القطبية والأغنية المعقدة متعددة الأجزاء لحيتان شاغوس القزمة في المحيط الهندي. في كلتا الحالتين، تم تدريب الكاشف كلياً على بيانات شبه اصطناعية. لبناء أحد النماذج، استُخدمت مجموعة تدريب مبنية على مثال حقيقي واحد فقط لأغنية شاغوس. وللحكم العادل على الأداء، لم يعتمد المؤلفون بشكل أعمى على سجلات الوسم «الحقيقة الأرضية» الموجودة، والتي تبين أنها تحتوي على العديد من النداءات الفائتة. بدلاً من ذلك، راجع محلل ذو خبرة يدوياً آلاف الاختلافات بين ما رصده الكاشف والسجلات. بعد هذا التحكيم، وجد أفضل نموذج لشاغوس 99.4% من النداءات المستهدفة بدقة 91.2%، بينما وجد نموذج القطب الجنوبي 87% بدقة 65% تحت قياس شامل احتسب كل من النداءات الواضحة والجوقات الكثيفة.
ما الذي تعنيه النتائج للحفظ
لغير المتخصص، تعني هذه الأرقام أن الكاشف يمكنه مسح أرشيفات هائلة والإشارة بثقة إلى ما يقرب من كل الحالات لاغنية حيتان معينة، مع عدد نسبي قليل من الإنذارات الكاذبة، حتى عندما تم تدريبه من تسجيل جيد واحد. هذا تقدم كبير لدراسة الأنواع المهددة قليلة المعرفة التي نادراً ما تُسجل أصواتها. يحذر المؤلفون من أن النجاح يعتمد على اختيارات واضحة حول ما يُحسب «ضربة» — مثلاً، ما إذا كان ينبغي تضمين الجوقات المتداخلة — وعلى تصميم أمثلة تدريب موجبة وسالبة بعناية. كما يؤكدون أن وسم الخبراء البشر ليس مثالياً، وهناك حاجة لمعايير أفضل لتقييم الكواشف. ومع ذلك، تُظهر هذه المنهجية أنه مع زيادة بيانات ذكية والتعلّم بالنقل، يمكن بناء أدوات استماع قوية للحفظ بتكلفة منخفضة ومشاركتها علناً، مما يساعد العلماء على فك شفرة الأصوات الخفية المخزنة بالفعل في أرشيفاتنا الصوتية العالمية.
الاستشهاد: Jancovich, B.A., Sanchez, V., Truong, G. et al. Automated detection of stereotyped animal sounds using data augmentation and transfer learning. Sci Rep 16, 13137 (2026). https://doi.org/10.1038/s41598-026-48308-6
الكلمات المفتاحية: المراقبة الصوتية السلبية, أغاني الحيتان الزرقاء, كاشف التعلم العميق, بيانات تدريب اصطناعية, حفظ الحياة البرية