Clear Sky Science · sv
Automatiserad upptäckt av stereotypt djurljud med hjälp av dataaugmentation och transferinlärning
Lyssna på dolda röster i havet
Över världens hav spelar stora undervattensmikrofoner tyst in ljudlandskapet: krossande vågor, fartygsmotorer, sprickande is — och valars djupa sånger. Begravda i dessa arkiv finns ledtrådar om var hotade djur lever, hur många de är och hur de klarar sig i ett föränderligt klimat. Men det finns helt enkelt för mycket ljud för att människor ska kunna granska det för hand. Denna studie presenterar ett nytt sätt att träna en automatiserad ”lyssnare” som pålitligt kan plocka ut mycket stereotypa djurokall — till exempel vissa blåvalssånger — även när det bara finns en enda bra inspelning av det kallet.
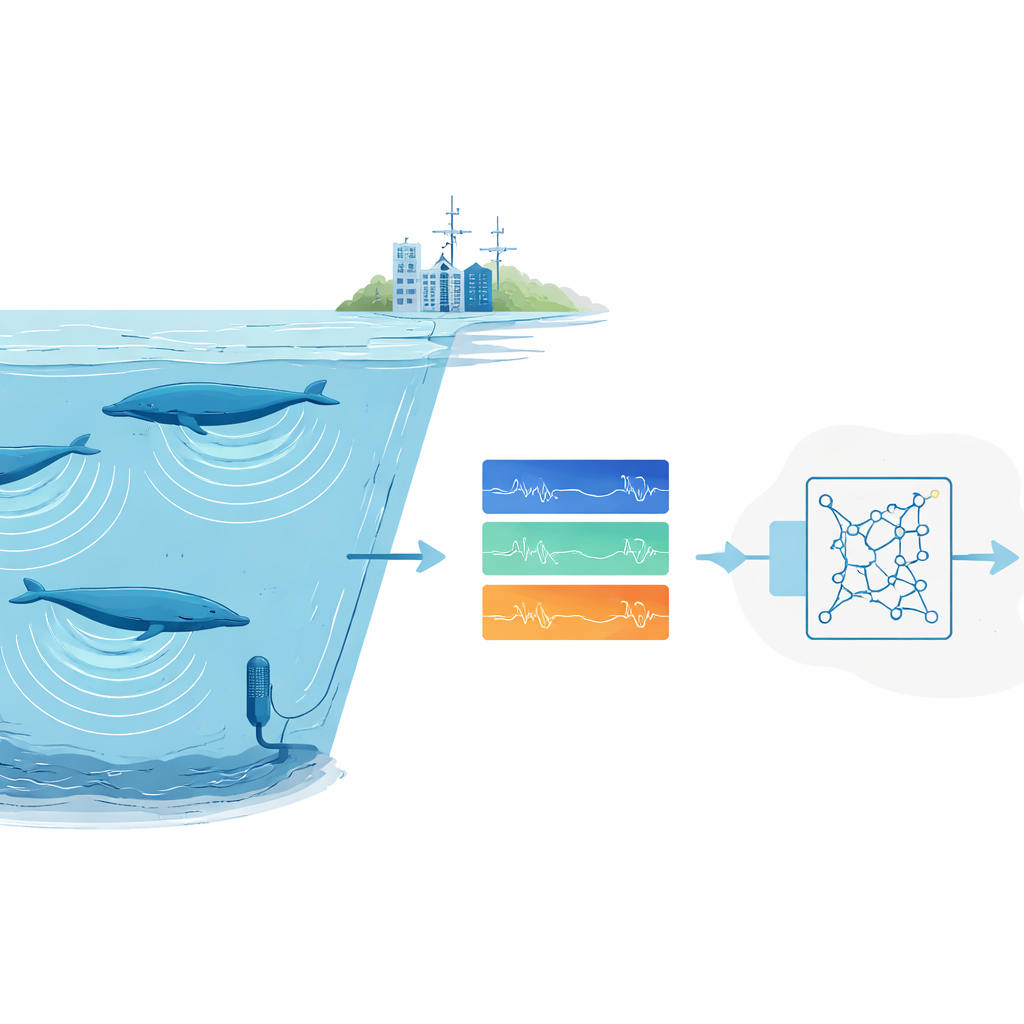
Varför det är så svårt att hitta djurljud
Forskare förlitar sig i allt högre grad på passiv akustisk övervakning: man lämnar ljudinspelare i naturen och söker senare igenom inspelningarna efter djurkall. För vanliga eller högljudda arter fungerar moderna djupinlärningssystem bra, men de kräver tusentals märkta exempel och kraftfulla datorer. Det är ett avgörande hinder för sällsynta eller svårfångade djur vars ljud bara spelats in ett fåtal gånger, och för forskargrupper utan tillgång till stora beräkningskluster. Utöver detta är havsinspelningar röriga. Bakgrundsljud från stormar, is och fartyg kan överrösta kallen, och mänskliga experter är ofta oense om vilka svaga markeringar i ett spektrogram som verkligen hör till en val.
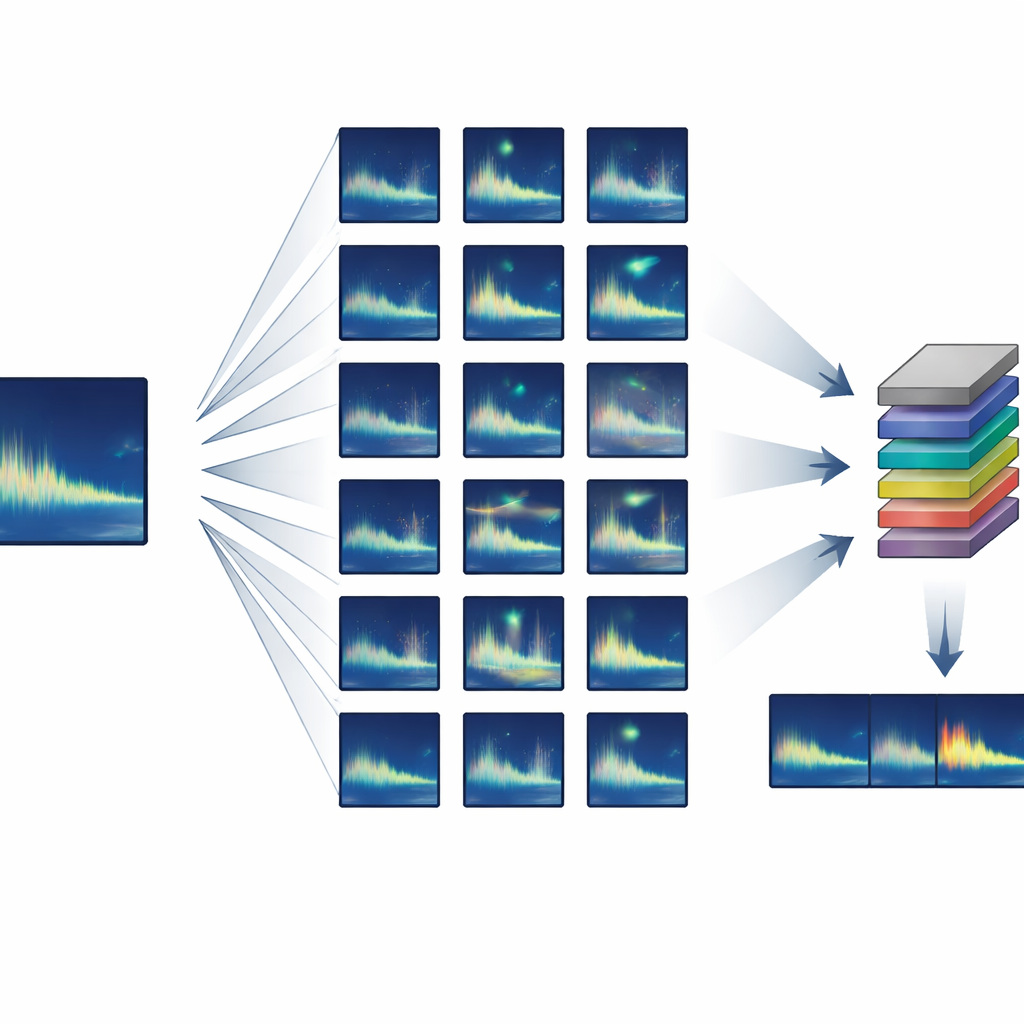
Bygga ett stort träningsset från nästan ingenting
Författarna fokuserade på djur som producerar mycket upprepbara, eller ”stereotypa”, kall — där varje individ låter nästan likadant. De utvecklade en semi-syntetisk träningspipeline som utgår från bara ett eller några rena exempel på ett målkall och sedan skapar tusentals realistiska varianter. Genom standard ljudbearbetning sträcker eller komprimerar systemet varje kall en aning i tiden, förskjuter dess tonhöjd för att efterlikna långsiktiga förändringar i sång, adderar mjuka distorsioner och eko, och blandar det med verkligt bakgrundsljud från havet. Avgörande är att alla dessa förändringar är förankrade i känd valbeteende och ljudspridning, så de syntetiska kallen fortfarande ser och låter ut som något en verklig val kan ha producerat.
Återanvända ett befintligt neuralt nätverk
I stället för att träna en detektor från grunden använde teamet transferinlärning: de började med ett neuralt nätverk ursprungligen utformat för att känna igen mänskligt tal och finjusterade det för valsånger. Detta nätverk behandlar ljud som en serie korta, överlappande spektrogramramar och innehåller rekurrenta lager som kan följa mönster över tid, vilket gör att det klarar av kall i olika längder. Träningen genomfördes på konsumenthårdvara — en vanlig laptop med ett beskedligt grafikkort — och tog cirka fem timmar. När det väl var tränat kunde systemet skanna fyra timmars havsljud på ungefär en och en halv minut, inklusive all för- och efterbearbetning.
Utvärdera detektorn
Metoden utvärderades på två mycket olika lågfrekventa kall från hotade blåvalar: det enkla, fallande ”Z-kallet” hos antarktiska blåvalar och den mer komplexa, flerdelade sången hos Chagos dvärgblåvalar i Indiska oceanen. I båda fallen tränades detektorn helt på semi-syntetisk data. För en modell byggdes träningssetet från endast ett enda verkligt exempel på Chagos-sången. För att rättvist bedöma prestanda förlitade sig författarna inte blint på befintliga annoteringsloggar, vilka visade sig innehålla många missade kall. I stället granskade en erfaren analytiker manuellt tusentals oenigheter mellan detektorn och loggarna. Efter denna prövning hittade den bästa Chagos-modellen korrekt 99,4 % av målkallen med 91,2 % precision, medan den antarktiska modellen hittade 87 % med 65 % precision under inkluderande scorning som räknade både tydliga kall och täta körer.
Vad resultaten betyder för bevarandearbete
För en icke-specialist innebär dessa siffror att detektorn kan skanna enorma arkiv och pålitligt markera nästan alla förekomster av en viss valsång, med relativt få falska larm, även när den tränats från en enda bra inspelning. Det är ett viktigt steg för att studera dåligt kända, hotade arter vars ljud sällan fångas. Författarna varnar för att framgång beror på tydliga val om vad som räknas som en ”träff” — till exempel om överlappande körer ska inkluderas — och på att noga utforma både positiva och negativa träningsexempel. De betonar också att även experttolkningar är ofullkomliga och att bättre standarder för att utvärdera detektorer fortfarande behövs. Ändå visar denna ram att med smart dataaugmentation och transferinlärning kan kraftfulla lyssningsverktyg för bevarande byggas billigt och delas öppet, vilket hjälper forskare att låsa upp de dolda röster som redan finns lagrade i våra globala akustiska arkiv.
Citering: Jancovich, B.A., Sanchez, V., Truong, G. et al. Automated detection of stereotyped animal sounds using data augmentation and transfer learning. Sci Rep 16, 13137 (2026). https://doi.org/10.1038/s41598-026-48308-6
Nyckelord: passiv akustisk övervakning, blåvalssånger, djupinlärningsdetektor, syntetisk träningsdata, viltvård