Clear Sky Science · zh
集成高斯混合模型与三态决策的聚类集成方法 (GMM-3WD-CE)
为何汇聚众多弱视角能揭示隐含模式
从在医疗数据中发现疾病特征到组织数百万张照片,计算机常常需要在没有任何标签的情况下将相似对象分组——这就是聚类任务。然而,任何一次单独的聚类尝试都可能很脆弱:改变参数或打乱初始点,群组可能就会发生变化。本文提出了一种将多次不完美的聚类结果合并为更可靠、能表达不确定性的方案,从而更清楚地表明哪些分组可以信赖、哪些仍存在疑问。
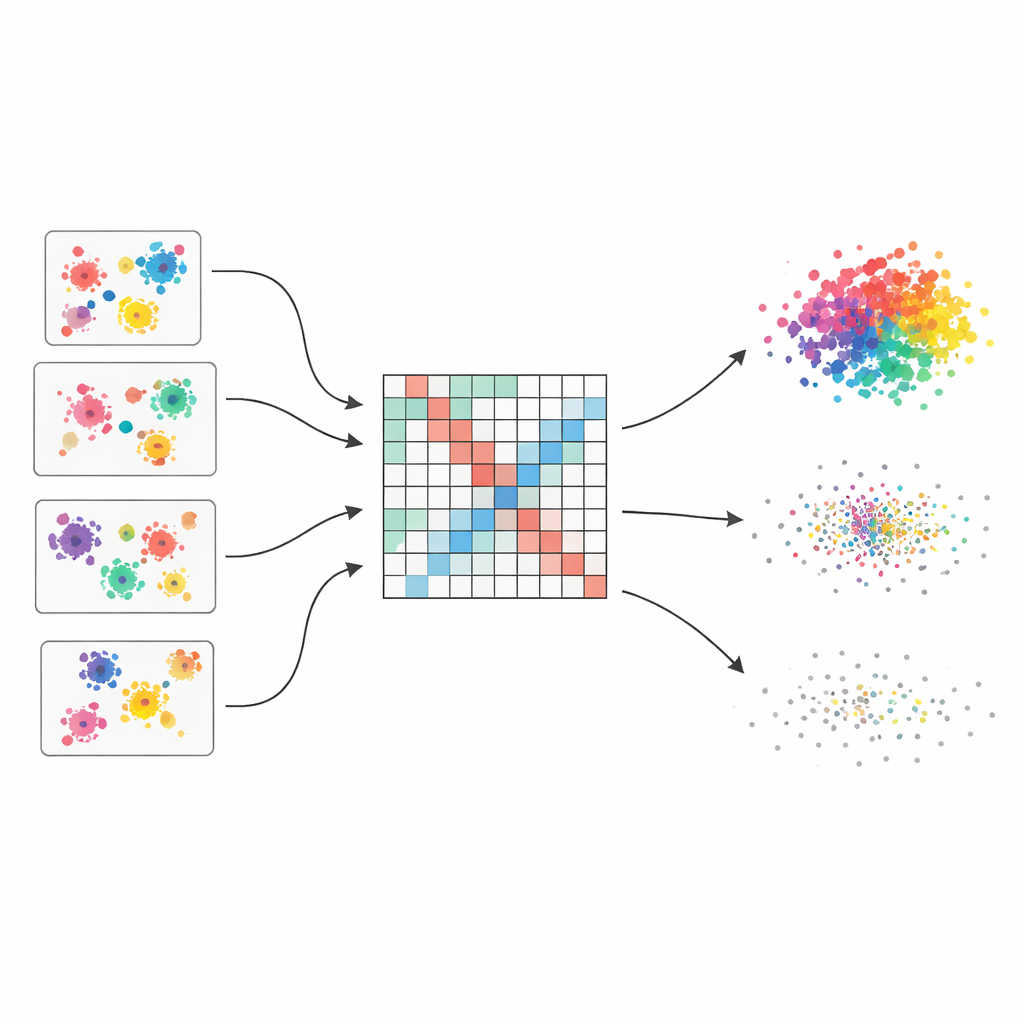
多重意见胜过单一脆弱猜测
作者从“聚类集成”的思想出发,这有点像向多位专家征询意见并加以整合。他们使用四种常用算法并略微调整参数,针对同一数据集生成五十种不同的聚类。由于每种方法以不同方式感知结构——有的偏好圆形簇,有的能处理奇形簇或密度混合——集成捕获了多种可行的分组方案。核心挑战则是将这些分散的意见合并为单一且连贯的图景。
把分散投票变成平滑的相似性图
为融合这些视角,方法首先构建一个大表格,记录每对数据点在所有运行中出现在同一簇的频率。该表并非被简单对待:每个基础聚类会根据三个著名指标得到一个质量得分,这些指标奖励分离良好且紧凑的簇,同时惩罚混乱的结果。更好的聚类在最终计票中拥有更大话语权。结果是一个“加权共同归属矩阵”,它像一幅软聚焦的地图,显示哪些点倾向于属于同一簇:证据一致之处信号强烈,意见分歧处则更为模糊。
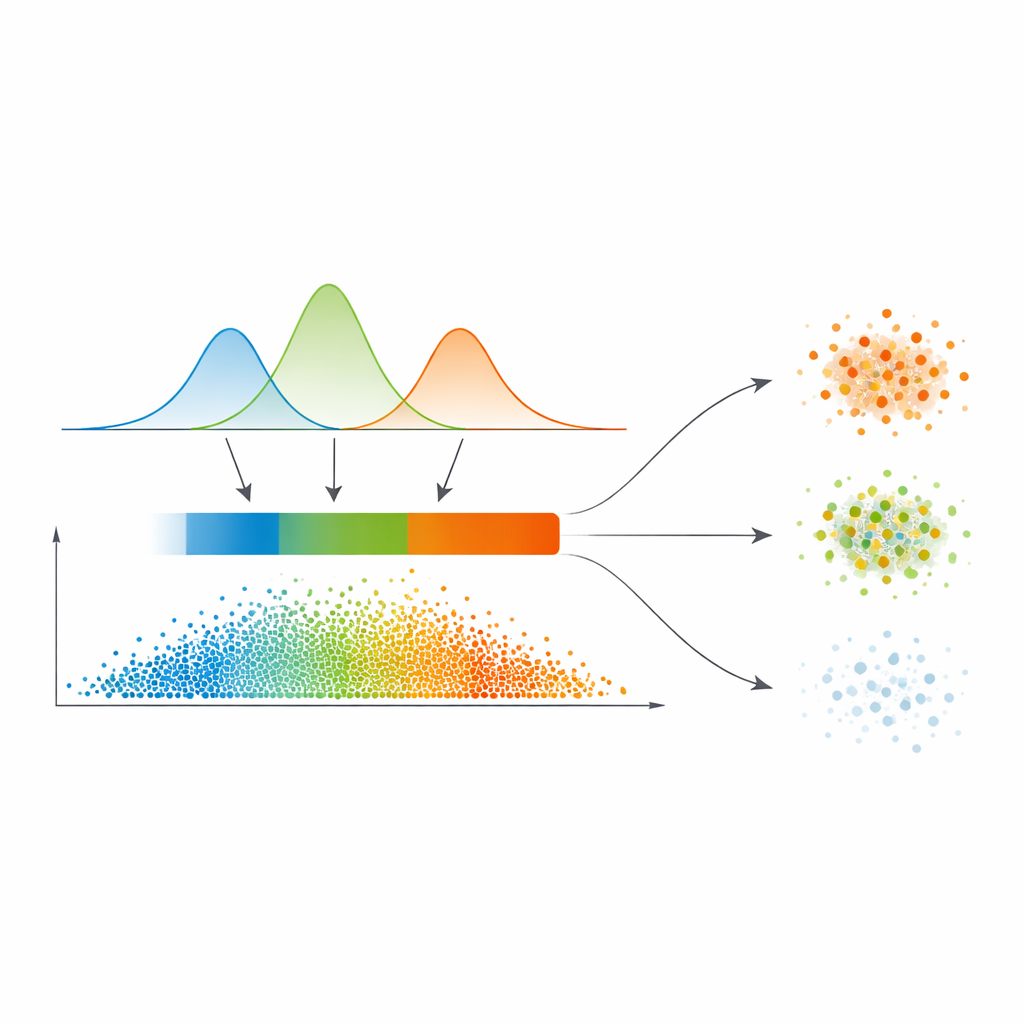
从平滑概率到三类置信区域
作者没有直接从该相似性图划出硬边界,而是对相似值的分布拟合了一个称为高斯混合的统计模型。通俗来说,他们用几条平滑曲线来解释相似性通常处于低、中或高的区间。该模型会自动选择需要多少个这样的成分,偏好更清晰的分离。对于每个数据点,其与其他点的关系被转化为属于各簇的概率,而这些概率的最大值成为一个简单的置信度度量。随后借用自图像处理的自动阈值步骤,将数据划分为三类区域:高置信度的“核心”、中间的“边界”和低置信度的“琐碎或噪声”区域。
针对清晰、模糊与噪声点的差异化处理
这项工作与众不同之处在于对这三类区域采取不同处理。核心区的点被直接分配到具有最高概率的簇——这是容易判断的样本。边界点处于意见冲突之中,通过依赖相似性地图的精细投票机制向其周围的高置信邻居借力。真正可疑的琐碎区域的点则要么被赋予一个暂定标签,要么被明确标记为噪声,而不会被强行刷入某个簇。这种分层策略契合人类在不确定性下的自然推理:接受清晰的结论,推迟处理有歧义的事,孤立看起来不可靠的样本。
实践中的表现如何
作者在八个多样化数据集上测试了他们的方法,涵盖经典的小型基准到流行的手写数字数据集 MNIST。他们与九种现有方法进行比较,包括传统集成方法和近期更复杂的技术。总体而言,新方法在平均表现上领先,尤其在簇彼此重叠或处于高维空间的困难问题上取得明显提升。严谨的统计检验支持这些改进,额外实验也展示了各个组件——质量加权、概率建模和三态决策步骤——对最终准确率的贡献。代价是计算时间:对所有成对关系建模随数据集规模呈二次增长。
对实际数据分组意味着什么
对非专业读者而言,主要结论是本文提供了一种有原则的方法,不仅告诉你“这些是分组”,还表明“我们对每个分配有多大把握”。通过汇聚多次聚类尝试、明确建模不确定性并将清晰样本与模糊和噪声样本区分开来,该方法在杂乱的真实数据中生成更值得信赖的分组。尽管它的计算开销更大,但在可靠性和可解释性比原始速度更重要的场景中,这是一个有价值的工具。
引用: Ma, Y., Li, Z. Clustering ensemble method integrating Gaussian mixture model and three-way decision (GMM-3WD-CE). Sci Rep 16, 11740 (2026). https://doi.org/10.1038/s41598-026-47453-2
关键词: 聚类集成, 无监督学习, 不确定性建模, 高斯混合模型, 数据挖掘