Clear Sky Science · sv
Klustringsensemblemetod som integrerar Gaussisk blandningsmodell och trevägsbeslut (GMM-3WD-CE)
Varför sammanslagning av många svaga vyer kan avslöja dolda mönster
Från att upptäcka sjukdomssignaturer i medicinska data till att organisera miljontals bilder behöver datorer ofta gruppera liknande objekt utan förhandsmärkningar — en uppgift som kallas klustring. Men varje enskilt klustringsförsök kan vara sårbart: ändra en inställning eller startpunkt och grupperna kan skifta. Denna artikel presenterar ett nytt sätt att kombinera många sådana ofullkomliga klustringar till ett mer pålitligt, osäkerhetsmedvetet resultat, vilket ger en tydligare bild av vilka grupptillhörigheter vi kan lita på och vilka som förblir tveksamma.
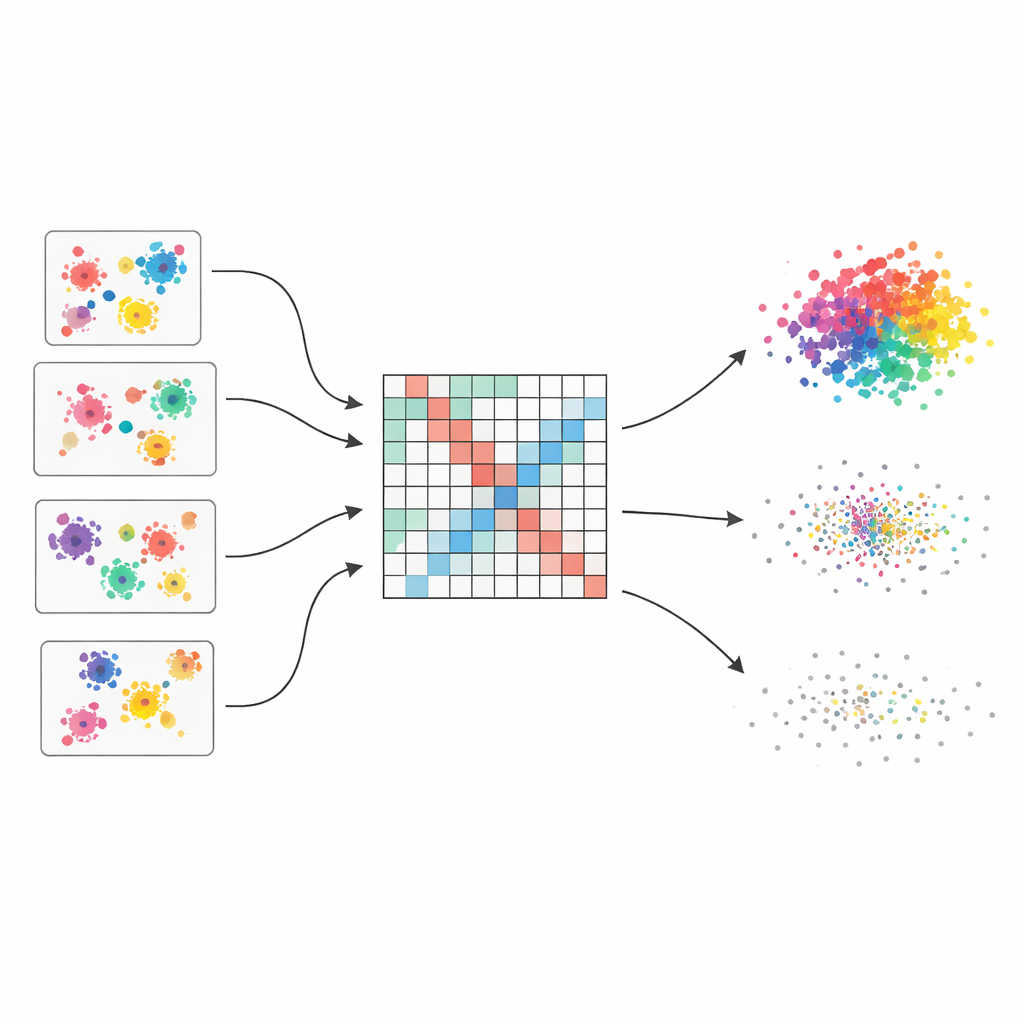
Många åsikter istället för en skör gissning
Författarna utgår från idén om en ”klustringsensemble”, som fungerar ungefär som att fråga flera experter och sedan kombinera deras åsikter. De genererar femtio olika klustringar av samma datamängd med hjälp av fyra populära algoritmer, var och en med lätt varierade inställningar. Eftersom varje metod ser struktur på sitt sätt — vissa föredrar runda kluster, andra hanterar udda former eller blandad täthet — fångar ensemblen ett brett spektrum av plausibla grupperingarna. Den grundläggande utmaningen är sedan att slå ihop dessa spridda åsikter till en enda, sammanhängande bild.
Från spridda röster till en mjuk likhetsbild
För att förena dessa många vyer bygger metoden först en stor tabell som registrerar hur ofta varje par datapunkter hamnar i samma kluster över alla körningar. Denna tabell behandlas inte naivt: varje bas-klustring tilldelas en kvalitetspoäng baserad på tre välkända index som belönar väl åtskilda och kompakta grupper och straffar röriga sådana. Bättre klustringar får större inflytande i den slutliga räkningen. Resultatet är en ”viktad co-associationsmatris” som fungerar som en mjukfokuserad karta över vem som tenderar att höra ihop, med starka signaler där bevisen är konsekventa och mjukare nyanser där åsikterna skiljer sig.
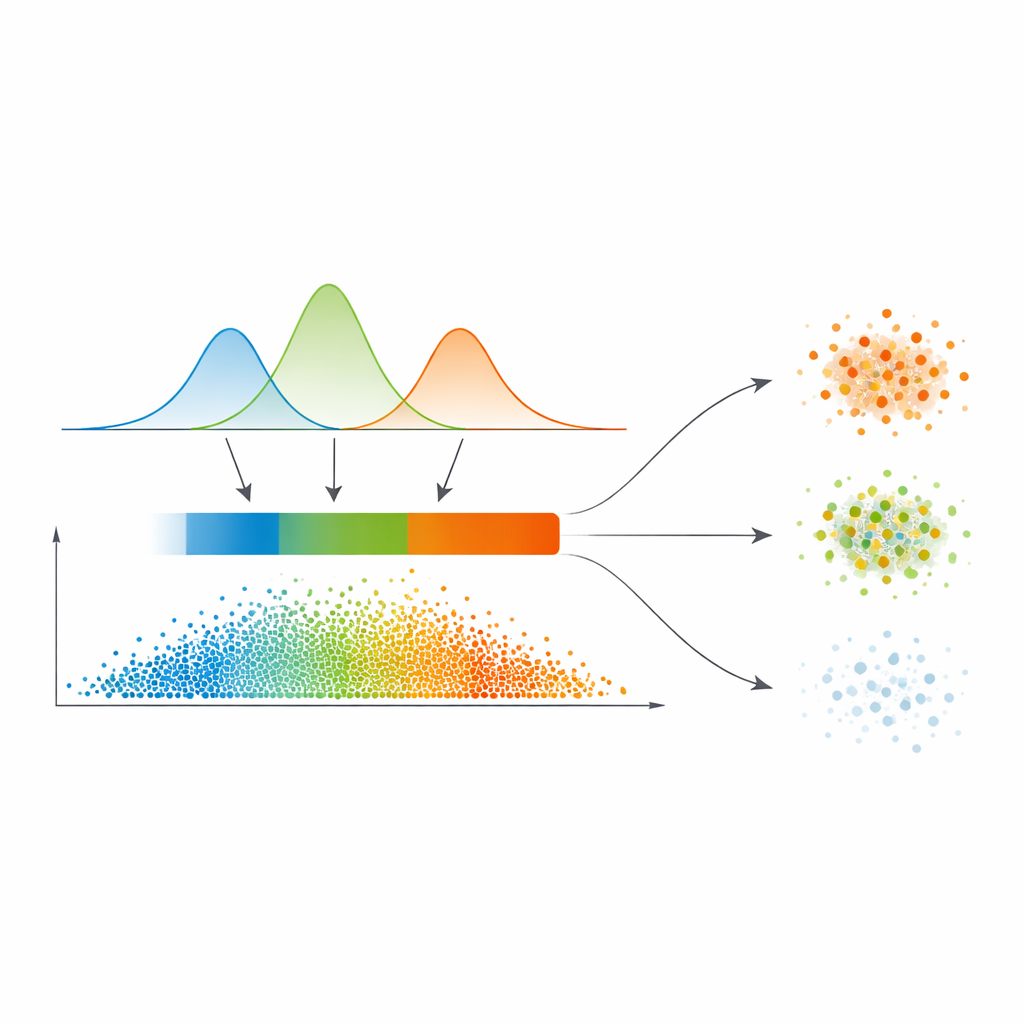
Från mjuka sannolikheter till tre konfidensregioner
I stället för att dra hårda gränser direkt från denna likhetskarta passar författarna en statistisk modell kallad Gaussisk blandningsmodell på fördelningen av likhetsvärdena. Enkelt uttryckt låter de flera mjuka kurvor förklara var likheten typiskt är låg, medel eller hög. Denna modell väljer automatiskt hur många sådana regime som behövs, med en preferens för renare separationer. För varje datapunkt omvandlas dess relationer till andra till en sannolikhet att tillhöra varje kluster, och maximala av dessa sannolikheter blir ett enkelt mått på förtroende. Ett automatiskt trösklingssteg, hämtat från bildbehandling, skär sedan upp datamängden i tre zoner: en högkonfidens ”kärna”, en mellanliggande ”gräns” och en lågkonfidens ”trivial eller brusig” region.
Att behandla tydliga, dimmiga och brusiga punkter olika
Det som skiljer detta arbete åt är hur man behandlar dessa tre regioner. Punkter i kärnan tilldelas direkt det kluster som har högst sannolikhet — detta är de enkla fallen. Gränspunkter, där åsikterna krockar, lånar styrka från sina säkra grannar via ett förfinat röstningsschema som stödjer sig på likhetskartan. Verkligen tveksamma punkter i den triviala regionen får antingen en preliminär etikett eller markeras uttryckligen som brus, istället för att tvingas in i ett kluster. Denna flerstegsstrategi speglar det naturliga sättet människor resonerar under osäkerhet: acceptera det som är klart, uppskjut det som är tvetydigt och isolera det som verkar opålitligt.
Hur väl det fungerar i praktiken
Författarna testar sitt tillvägagångssätt på åtta olika datamängder, från klassiska små benchmark-dataset till populära MNIST för handskrivna siffror. De jämför med nio befintliga metoder, inklusive både traditionella ensemblar och nyare, mer sofistikerade tekniker. Sammantaget ger den nya metoden bästa genomsnittliga prestanda, med särskilt starka förbättringar på svåra problem där kluster överlappar eller lever i högre dimensioner. Noggranna statistiska tester stöder dessa förbättringar, och ytterligare experiment visar hur varje komponent — kvalitetsviktningen, den probabilistiska modelleringen och trevägsbeslutssteget — bidrar till slutlig noggrannhet. Nackdelen är beräkningstid: att modellera alla parvisa relationer växer kvadratiskt med datamängdens storlek.
Vad detta betyder för gruppering av verkliga data
För icke-specialister är huvudbudskapet att artikeln erbjuder ett principfast sätt att säga inte bara ”detta är grupperna”, utan också ”så här säkra är vi om varje tilldelning”. Genom att blanda många klustringsförsök, modellera osäkerhet explicit och skilja klara fall från dimmiga och brusiga, producerar metoden mer pålitliga grupperingarna, särskilt i röriga, verkliga data. Även om den är mer beräkningskrävande ger den ett värdefullt verktyg när tillförlitlighet och tolkbarhet är viktigare än ren hastighet.
Citering: Ma, Y., Li, Z. Clustering ensemble method integrating Gaussian mixture model and three-way decision (GMM-3WD-CE). Sci Rep 16, 11740 (2026). https://doi.org/10.1038/s41598-026-47453-2
Nyckelord: klustringsensemble, osuperviserad inlärning, osäkerhetsmodellering, Gaussisk blandningsmodell, datautvinning