Clear Sky Science · fr
Méthode d’ensemble de clustering intégrant un modèle de mélange gaussien et une décision en trois volets (GMM-3WD-CE)
Pourquoi mélanger de nombreuses vues faibles peut révéler des structures cachées
Qu’il s’agisse de repérer des signatures de maladie dans des données médicales ou d’organiser des millions de photos, les ordinateurs doivent souvent regrouper des éléments similaires sans étiquettes préalables — une tâche appelée clustering. Pourtant, une seule tentative de clustering peut être fragile : changer un paramètre ou la condition initiale et les groupes peuvent varier. Cet article présente une nouvelle façon de combiner de nombreux clusterings imparfaits en un résultat plus fiable et conscient de l’incertitude, offrant une vision plus claire des groupements auxquels on peut se fier et de ceux qui restent douteux.
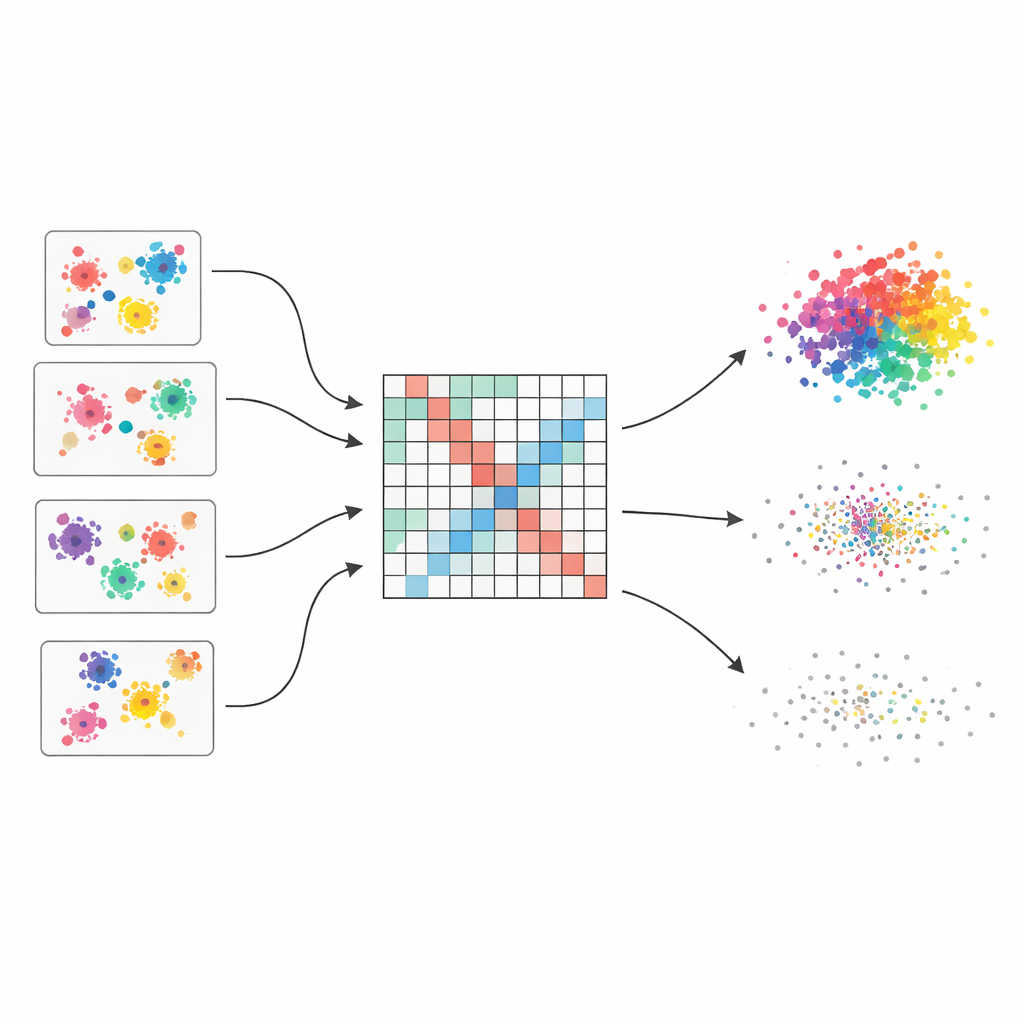
De nombreuses opinions plutôt qu’une estimation fragile
Les auteurs partent de l’idée d’un « ensemble de clusterings », qui fonctionne un peu comme consulter plusieurs experts puis combiner leurs avis. Ils génèrent cinquante clusterings différents du même jeu de données en utilisant quatre algorithmes populaires, chacun avec des réglages légèrement variés. Comme chaque méthode perçoit la structure différemment — certaines privilégient les clusters ronds, d’autres gèrent mieux les formes inhabituelles ou les densités mixtes — l’ensemble capture un large éventail de groupements plausibles. Le défi central est alors de fusionner ces opinions dispersées en une image unique et cohérente.
Transformer des votes épars en une carte lissée de similarité
Pour fusionner ces vues multiples, la méthode construit d’abord une grande table qui enregistre la fréquence à laquelle chaque paire de points de données se retrouve dans le même cluster au fil des exécutions. Cette table n’est pas traitée naïvement : chaque clustering de base reçoit un score de qualité basé sur trois indices bien connus qui récompensent des groupes bien séparés et compacts et pénalisent les configurations désordonnées. Les meilleurs clusterings ont donc plus de poids dans le décompte final. Le résultat est une « matrice de co-association pondérée » qui agit comme une carte à mise au point douce indiquant qui a tendance à appartenir ensemble, avec des signaux forts là où les preuves sont cohérentes et des nuances plus floues là où les avis divergent.
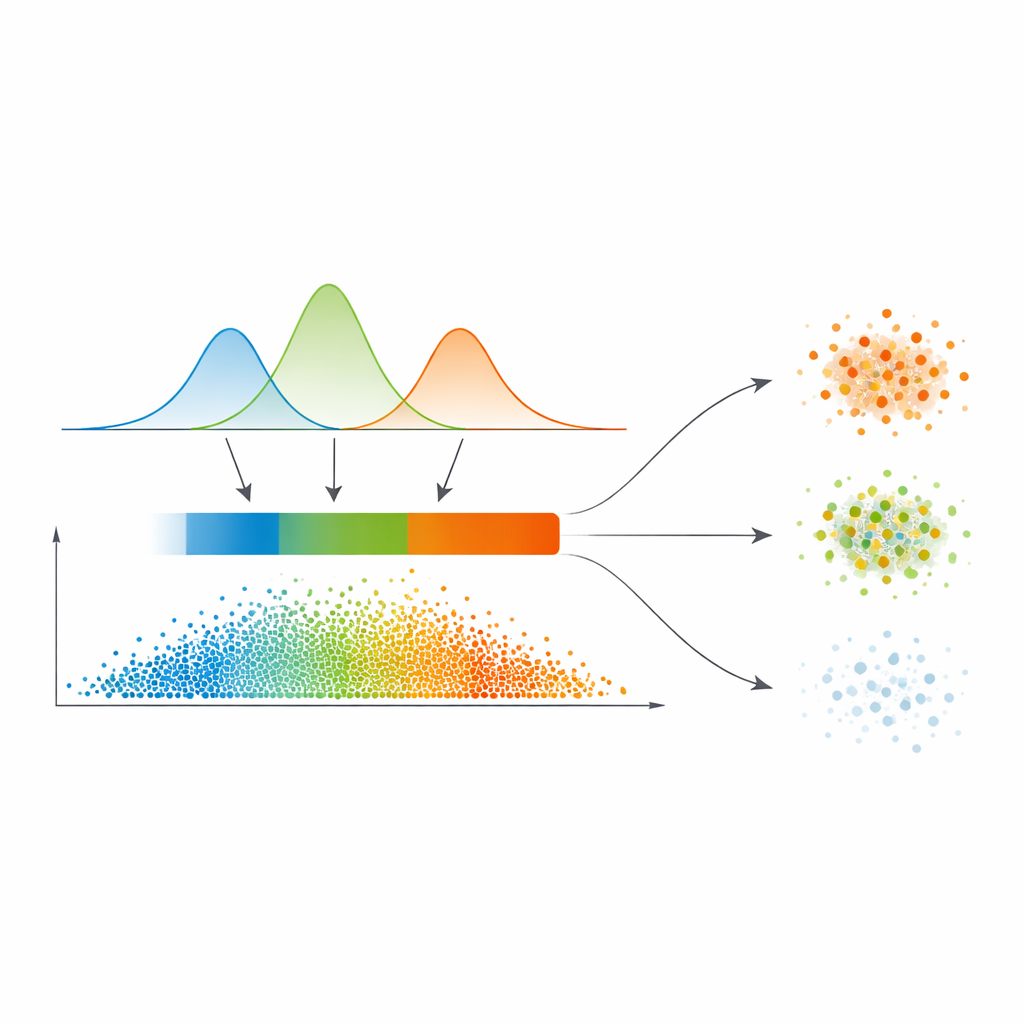
Des probabilités lissées à trois zones de confiance
Plutôt que de tracer des frontières nettes directement à partir de cette carte de similarité, les auteurs ajustent un modèle statistique appelé mélange gaussien à la distribution des valeurs de similarité. En termes simples, ils laissent plusieurs courbes lisses expliquer où la similarité est typiquement faible, moyenne ou élevée. Ce modèle choisit automatiquement combien de régimes sont nécessaires, privilégiant des séparations plus propres. Pour chaque point de données, ses relations avec les autres sont converties en une probabilité d’appartenance à chaque cluster, et le maximum de ces probabilités devient une mesure simple de confiance. Une étape automatique de seuillage, empruntée au traitement d’image, découpe ensuite les données en trois zones : un « cœur » de haute confiance, une « frontière » intermédiaire et une région à faible confiance « triviale ou bruyante ».
Traiter différemment les points clairs, flous et bruyants
Ce qui distingue ce travail, c’est la manière dont il traite ces trois zones. Les points du cœur sont affectés directement au cluster dont la probabilité est la plus élevée — ce sont les cas faciles. Les points de la frontière, où les avis s’affrontent, empruntent de la robustesse à leurs voisins confiants via un schéma de vote affiné qui s’appuie sur la carte de similarité. Les points vraiment douteux de la région triviale reçoivent soit une étiquette provisoire, soit sont explicitement marqués comme bruit, plutôt que d’être forcés dans un cluster. Cette stratégie à niveaux correspond à la façon naturelle dont les humains raisonnent en présence d’incertitude : accepter ce qui est clair, différer ce qui est ambigu et isoler ce qui semble peu fiable.
Quelle efficacité en pratique
Les auteurs testent leur approche sur huit jeux de données divers, allant de petits benchmarks classiques aux célèbres chiffres manuscrits MNIST. Ils comparent leur méthode à neuf méthodes existantes, incluant à la fois des ensembles traditionnels et des techniques plus récentes et sophistiquées. Globalement, la nouvelle méthode offre la meilleure performance moyenne, avec des gains particulièrement marqués sur des problèmes difficiles où les clusters se chevauchent ou évoluent en haute dimension. Des tests statistiques rigoureux confirment ces améliorations, et des expériences supplémentaires montrent comment chaque composant — la pondération par qualité, la modélisation probabiliste et l’étape de décision en trois volets — contribue à la précision finale. Le compromis est le temps de calcul : la modélisation de toutes les relations par paires croît quadratiquement avec la taille du jeu de données.
Ce que cela signifie pour le regroupement de données réelles
Pour les non-spécialistes, le message principal est que l’article propose une façon raisonnée de dire non seulement « voici les groupes », mais aussi « voici notre degré de certitude pour chaque affectation ». En mélangeant de nombreuses tentatives de clustering, en modélisant explicitement l’incertitude et en séparant les cas clairs des cas flous et bruyants, la méthode produit des groupements plus dignes de confiance, en particulier sur des données réelles et désordonnées. Bien qu’elle soit plus gourmande en calcul, elle constitue un outil précieux lorsque la fiabilité et l’interprétabilité comptent plus que la simple rapidité.
Citation: Ma, Y., Li, Z. Clustering ensemble method integrating Gaussian mixture model and three-way decision (GMM-3WD-CE). Sci Rep 16, 11740 (2026). https://doi.org/10.1038/s41598-026-47453-2
Mots-clés: ensemble de clustering, apprentissage non supervisé, modélisation de l'incertitude, modèle de mélange gaussien, fouille de données