Clear Sky Science · de
Clustering-Ensemble-Methode, die Gaußsches Mischmodell und Three-Way-Decision kombiniert (GMM-3WD-CE)
Warum das Zusammenführen vieler schwacher Ansichten verborgene Muster offenbaren kann
Ob beim Aufspüren von Krankheitsmustern in medizinischen Daten oder beim Organisieren von Millionen Fotos – Computer müssen häufig ähnliche Objekte ohne vorliegende Labels gruppieren, eine Aufgabe namens Clustering. Einzelne Clustering-Versuche sind jedoch anfällig: Ändert man eine Einstellung oder die Startkonfiguration, können sich die Gruppen verschieben. Dieses Papier stellt eine neue Methode vor, um viele solche unvollkommenen Clusterings zu einem verlässlicheren, unsicherheitsbewussten Ergebnis zu vereinen und so deutlicher zu zeigen, welchen Gruppenzuordnungen man vertrauen kann und welche fraglich bleiben.
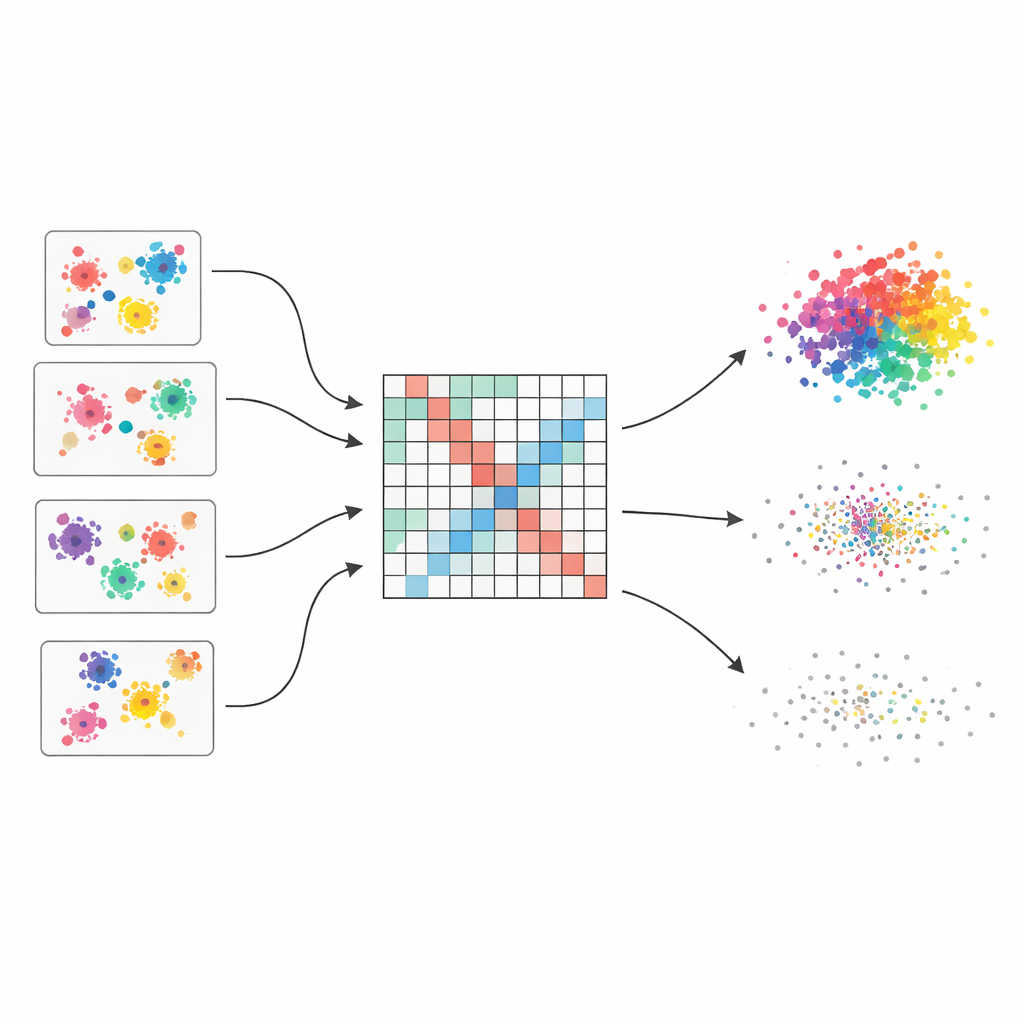
Viele Meinungen statt einer fragilen Vermutung
Die Autoren beginnen mit der Idee eines „Clustering-Ensembles“, das ähnlich funktioniert wie das Einholen mehrerer Expertisen und deren Kombination. Sie erzeugen fünfzig verschiedene Clusterings desselben Datensatzes mit vier populären Algorithmen, jeweils mit leicht variierenden Parametern. Da jede Methode Struktur unterschiedlich wahrnimmt – einige bevorzugen runde Gruppen, andere gehen mit ungewöhnlichen Formen oder variierenden Dichten besser um – erfasst das Ensemble ein breites Spektrum plausibler Gruppierungen. Die zentrale Herausforderung besteht dann darin, diese verstreuten Meinungen zu einem kohärenten Gesamtbild zu verschmelzen.
Aus verstreuten Stimmen ein glättes Ähnlichkeitsbild machen
Um die vielen Ansichten zu fusionieren, baut die Methode zunächst eine große Tabelle auf, die dokumentiert, wie oft jedes Paar von Datenpunkten in den gleichen Cluster kommt. Diese Tabelle wird nicht naiv behandelt: Jede Basis-Clusterung erhält eine Qualitätsbewertung anhand dreier bekannter Indizes, die gut separierte und kompakte Gruppen belohnen und unordentliche Strukturen bestrafen. Bessere Clusterings erhalten so stärkeren Einfluss auf das Endergebnis. Das Resultat ist eine „gewichtete Co-Association-Matrix“, die wie eine weichgezeichnete Karte wirkt, in der sich stabile Zusammengehörigkeiten klar abzeichnen und in Bereichen mit widersprüchlichen Meinungen die Signale schwächer sind.
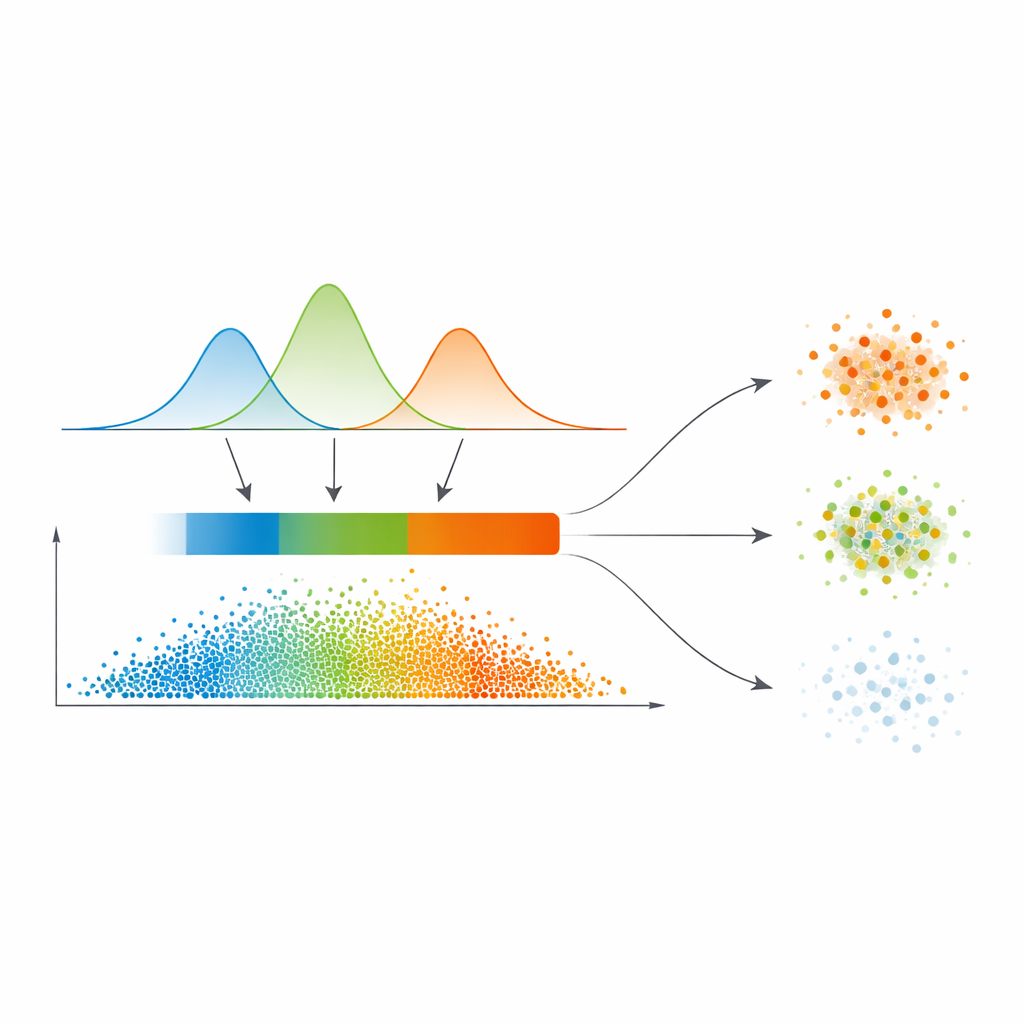
Von glatten Wahrscheinlichkeiten zu drei Vertrauensbereichen
Anstatt aus dieser Ähnlichkeitskarte direkt harte Grenzen zu ziehen, passen die Autoren ein statistisches Modell – ein Gaußsches Mischmodell – an die Verteilung der Ähnlichkeitswerte an. Einfach gesagt lassen sie mehrere glatte Kurven erklären, wo Ähnlichkeit typischerweise niedrig, mittel oder hoch ist. Das Modell wählt dabei automatisch, wie viele solche Regionen nötig sind, und bevorzugt sauberere Trennungen. Für jeden Datenpunkt werden seine Beziehungen zu anderen in Wahrscheinlichkeiten für die Zugehörigkeit zu den Clustern umgerechnet; das Maximum dieser Wahrscheinlichkeiten dient als einfacher Vertrauensmaßstab. Ein automatisch bestimmter Schwellenwert, entlehnt aus der Bildverarbeitung, unterteilt die Daten dann in drei Zonen: einen hochvertrauenswürdigen „Kern“, eine intermediäre „Grenzregion“ und eine gering vertrauenswürdige „triviale oder rauschbehaftete“ Region.
Klare, unscharfe und verrauschte Punkte unterschiedlich behandeln
Was diese Arbeit besonders macht, ist der unterschiedliche Umgang mit diesen drei Regionen. Punkte im Kern werden direkt dem Cluster mit der höchsten Wahrscheinlichkeit zugewiesen – das sind die einfachen Fälle. Grenzpunkte, bei denen die Meinungen auseinandergehen, ziehen zusätzliche Information von ihren sicheren Nachbarn mithilfe eines verfeinerten Abstimmungsverfahrens, das auf der Ähnlichkeitskarte beruht. Wirklich zweifelhafte Punkte in der trivialen Region erhalten entweder eine vorläufige Kennzeichnung oder werden explizit als Rauschen markiert, anstatt gewaltsam in einen Cluster gedrängt zu werden. Diese gestufte Strategie entspricht der natürlichen menschlichen Herangehensweise an Unsicherheit: Akzeptiere, was klar ist, verschiebe, was mehrdeutig ist, und isoliere, was unzuverlässig erscheint.
Wie gut es in der Praxis funktioniert
Die Autoren testen ihren Ansatz an acht unterschiedlichen Datensätzen, von klassischen kleinen Benchmarks bis hin zu den populären MNIST-Handschriftziffern. Sie vergleichen gegen neun bestehende Methoden, darunter traditionelle Ensembles und neuere, ausgefeiltere Verfahren. Insgesamt liefert die neue Methode die beste durchschnittliche Leistung, mit besonders starken Verbesserungen bei schwierigen Problemen, bei denen Cluster überlappen oder in hohen Dimensionen liegen. Sorgfältige statistische Tests untermauern diese Verbesserungen, und zusätzliche Experimente zeigen, wie jeder Bestandteil – die Qualitätsgewichtung, die probabilistische Modellierung und der Three-Way-Decision-Schritt – zur Endgenauigkeit beiträgt. Der Kompromiss besteht in der Rechenzeit: Das Modellieren aller paarweisen Beziehungen wächst quadratisch mit der Datensatzgröße.
Was das für reales Datenclustering bedeutet
Für Nicht-Spezialisten lautet die Kernbotschaft, dass das Papier eine prinzipientreue Methode anbietet, um nicht nur zu sagen „das sind die Gruppen“, sondern auch „so sicher sind wir bei jeder Zuordnung“. Durch das Verschmelzen vieler Clustering-Versuche, das explizite Modellieren von Unsicherheit und die Trennung klarer Fälle von unscharfen und verrauschten, liefert die Methode vertrauenswürdigere Gruppierungen, besonders bei unordentlichen, realen Daten. Zwar erfordert sie mehr Rechenaufwand, bietet jedoch ein wertvolles Werkzeug, wenn Verlässlichkeit und Interpretierbarkeit wichtiger sind als rohe Geschwindigkeit.
Zitation: Ma, Y., Li, Z. Clustering ensemble method integrating Gaussian mixture model and three-way decision (GMM-3WD-CE). Sci Rep 16, 11740 (2026). https://doi.org/10.1038/s41598-026-47453-2
Schlüsselwörter: Clustering-Ensemble, unüberwachtes Lernen, Unsicherheitsmodellierung, Gaußsches Mischmodell, Data Mining