Clear Sky Science · en
Clustering ensemble method integrating Gaussian mixture model and three-way decision (GMM-3WD-CE)
Why blending many weak views can reveal hidden patterns
From spotting disease signatures in medical data to organising millions of photos, computers often need to group similar things together without any prior labels—a task called clustering. Yet any single clustering attempt can be fragile: change a setting or shuffle the starting point and the groups may shift. This paper introduces a new way to combine many such imperfect clusterings into a more reliable, uncertainty-aware result, offering a clearer picture of which groupings we can trust and which remain doubtful.
Many opinions instead of one fragile guess
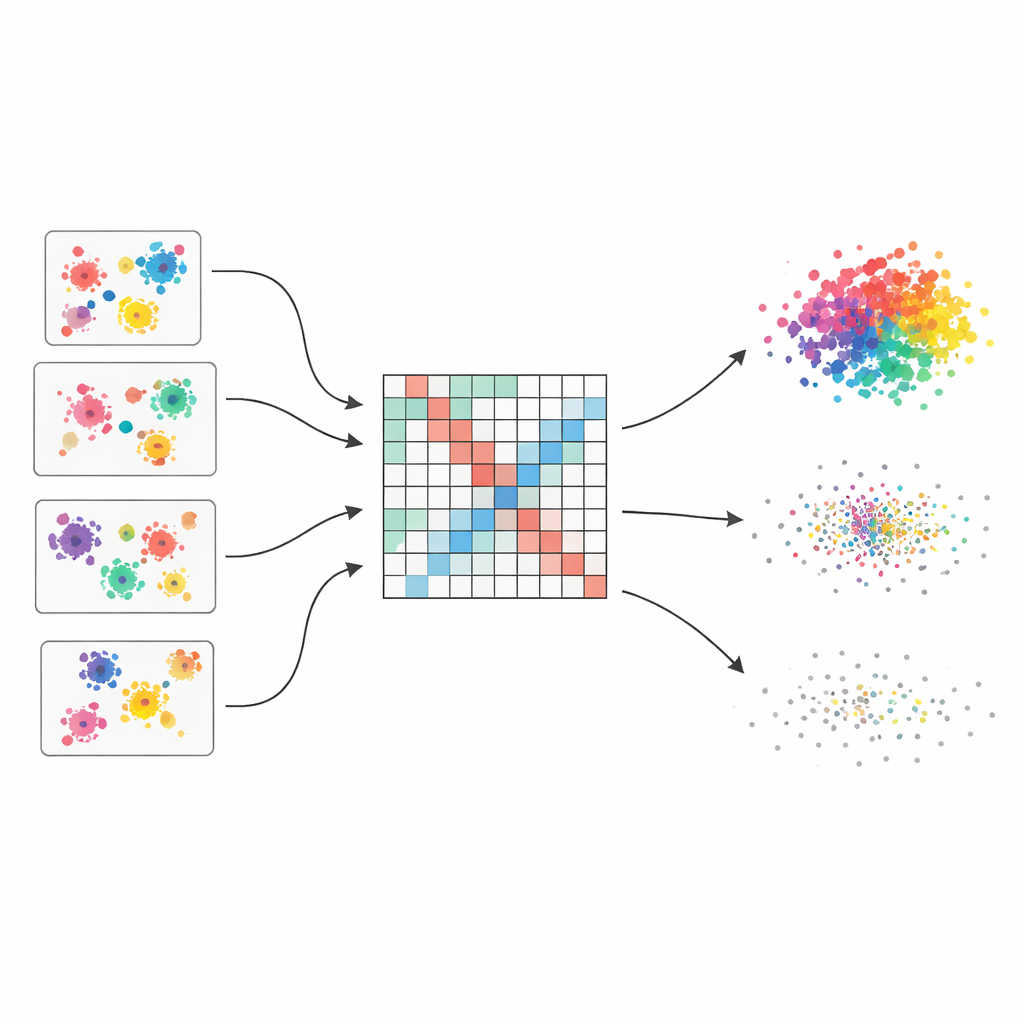
The authors start from the idea of a “clustering ensemble,” which works a bit like asking multiple experts for their views and then combining them. They generate fifty different clusterings of the same dataset using four popular algorithms, each with slightly varied settings. Because each method sees structure in a different way—some favour round clusters, others handle odd shapes or mixed densities—the ensemble captures a wide range of plausible groupings. The core challenge is then to merge these scattered opinions into a single, coherent picture.
Turning scattered votes into a smooth picture of similarity
To fuse these many views, the method first builds a large table that records how often each pair of data points ends up in the same cluster across all runs. This table is not treated naively: each base clustering is given a quality score based on three well-known indices that reward well-separated and compact groups and penalise messy ones. Better clusterings get more say in the final tally. The result is a “weighted co-association matrix” that acts like a soft-focus map of who tends to belong together, with strong signals where evidence is consistent and softer shades where opinions differ.
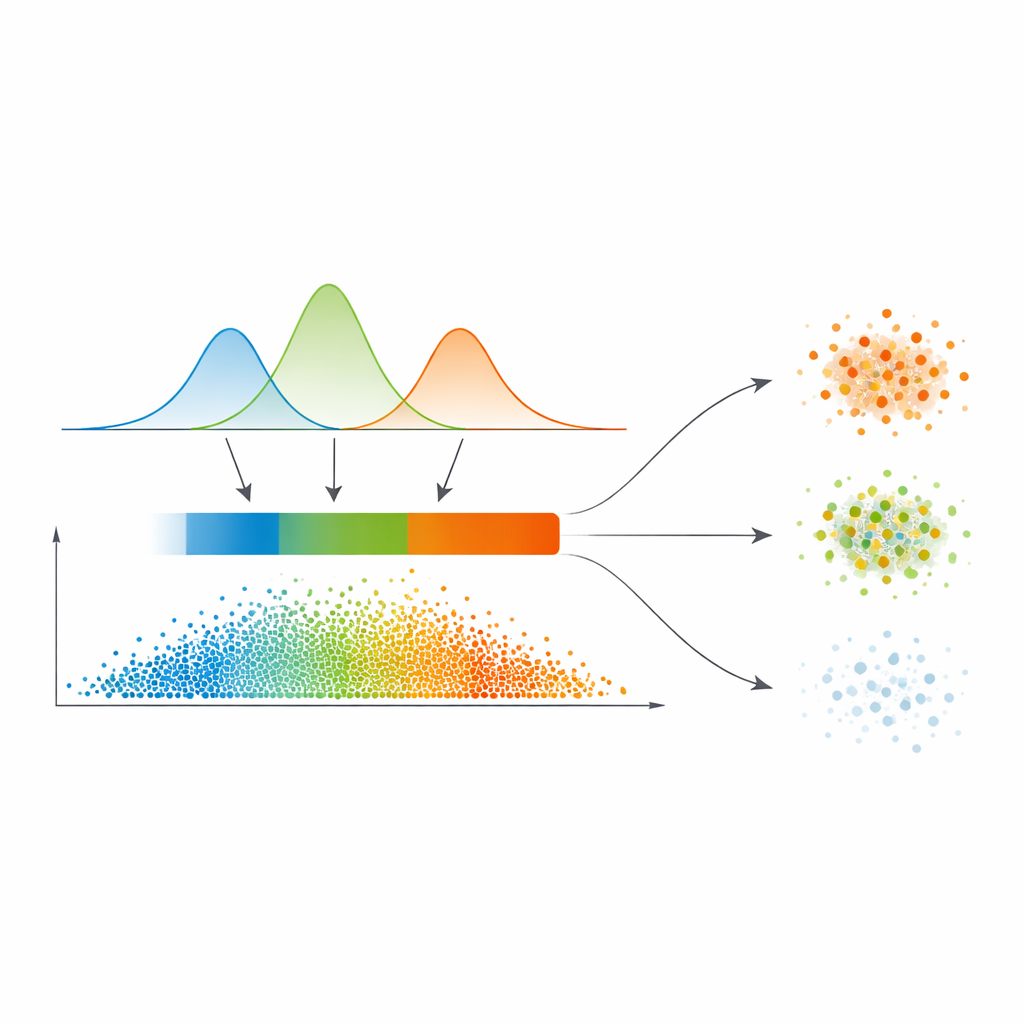
From smooth probabilities to three confidence regions
Instead of drawing hard lines directly from this similarity map, the authors fit a statistical model called a Gaussian mixture to the distribution of similarity values. In plain terms, they let several smooth curves explain where similarity is typically low, medium, or high. This model automatically chooses how many such regimes are needed, favouring cleaner separations. For each data point, its relationships to others are converted into a probability of belonging to each cluster, and the maximum of these probabilities becomes a simple measure of confidence. An automatic thresholding step, borrowed from image processing, then carves the data into three zones: a high-confidence “core,” an intermediate “boundary,” and a low-confidence “trivial or noisy” region.
Treating clear, fuzzy, and noisy points differently
What sets this work apart is how it treats these three regions. Points in the core are assigned directly to the cluster with the highest probability—these are the easy cases. Boundary points, where opinions clash, borrow strength from their confident neighbours via a refined voting scheme that leans on the similarity map. Truly doubtful points in the trivial region are either given a tentative label or explicitly marked as noise, rather than being forced into a cluster. This tiered strategy matches the natural way humans reason under uncertainty: accept what is clear, defer what is ambiguous, and isolate what appears unreliable.
How well it works in practice
The authors test their approach on eight diverse datasets, ranging from classic small benchmarks to the popular MNIST handwritten digits. They compare against nine existing methods, including both traditional ensembles and more recent, sophisticated techniques. Overall, the new method delivers the best average performance, with especially strong gains on hard problems where clusters overlap or live in high dimensions. Careful statistical tests back up these improvements, and additional experiments show how each component—the quality weighting, probabilistic modelling, and three-way decision step—contributes to the final accuracy. The trade-off is computation time: modelling all pairwise relationships grows quadratically with dataset size.
What this means for real-world data grouping
For non-specialists, the main message is that the paper offers a principled way to say not just “these are the groups,” but also “here is how sure we are about each assignment.” By blending many clustering attempts, modelling uncertainty explicitly, and separating clear cases from fuzzy and noisy ones, the method produces more trustworthy groupings, particularly in messy, real-world data. Although it is more computationally demanding, it provides a valuable tool when reliability and interpretability matter more than raw speed.
Citation: Ma, Y., Li, Z. Clustering ensemble method integrating Gaussian mixture model and three-way decision (GMM-3WD-CE). Sci Rep 16, 11740 (2026). https://doi.org/10.1038/s41598-026-47453-2
Keywords: clustering ensemble, unsupervised learning, uncertainty modeling, Gaussian mixture model, data mining