Clear Sky Science · nl
Clustering-ensemblemethode die Gaussiaanse mengvorm en drie-weg beslissing integreert (GMM-3WD-CE)
Waarom het samenvoegen van veel zwakke gezichtspunten verborgen patronen kan onthullen
Van het opsporen van ziektekenmerken in medische gegevens tot het ordenen van miljoenen foto’s: computers moeten vaak soortgelijke items clusteren zonder voorafgaande labels — een taak die clustering wordt genoemd. Toch kan elke afzonderlijke clustering fragiel zijn: verander een parameter of de starttoestand en de groepen kunnen verschuiven. Dit artikel introduceert een nieuwe manier om vele zulke onvolmaakte clusterings te combineren tot een betrouwbaarder, onzekerheidsbewust resultaat, waardoor duidelijker wordt welke groeperingen we kunnen vertrouwen en welke twijfelachtig blijven.
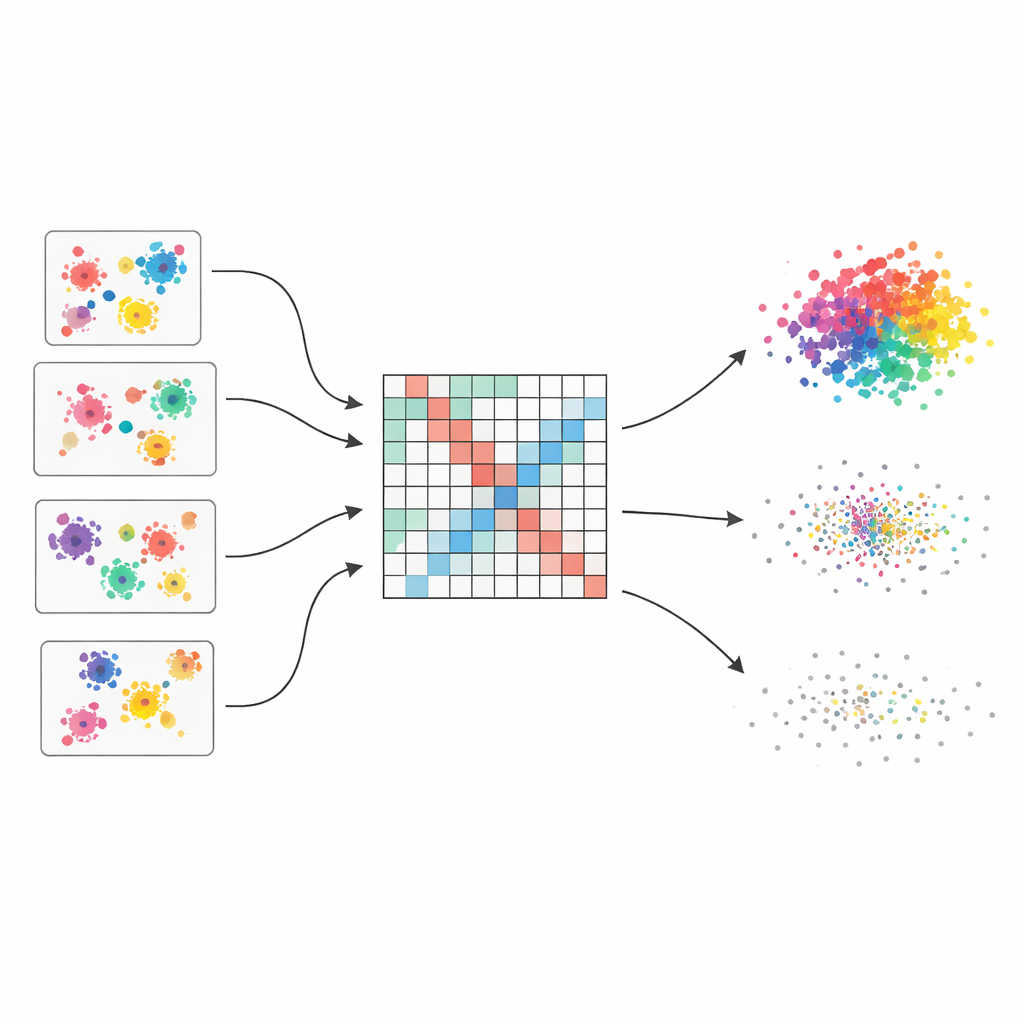
Veel meningen in plaats van één fragiele gok
De auteurs vertrekken vanuit het idee van een “clustering ensemble”, dat een beetje werkt als het raadplegen van meerdere experts en het vervolgens combineren van hun visies. Ze genereren vijftig verschillende clusterings van dezelfde dataset met vier populaire algoritmen, elk met licht verschillende instellingen. Omdat elke methode structuur op een andere manier ziet — sommige geven de voorkeur aan ronde clusters, andere kunnen vreemde vormen of verschillende dichtheden aan — vangt het ensemble een breed scala aan plausibele groeperingen. De kernuitdaging is vervolgens deze verspreide meningen om te zetten in een enkel, coherent beeld.
Verspreide stemmen omzetten in een vloeiend gelijkeniskaart
Om deze vele gezichtspunten te versmelten bouwt de methode eerst een grote tabel die bijhoudt hoe vaak elk paar datapunten in dezelfde cluster terechtkomt over alle runs. Deze tabel wordt niet naïef behandeld: elke basisclustering krijgt een kwaliteitscore op basis van drie bekende indexen die goed gescheiden en compacte groepen belonen en rommelige groepen bestraffen. Betere clusterings krijgen meer invloed in de eindtelling. Het resultaat is een “gewogen co-associatiematrix” die fungeert als een soft-focus kaart van wie geneigd is samen te horen, met sterke signalen waar het bewijs consistent is en zachtere tinten waar meningen verschillen.
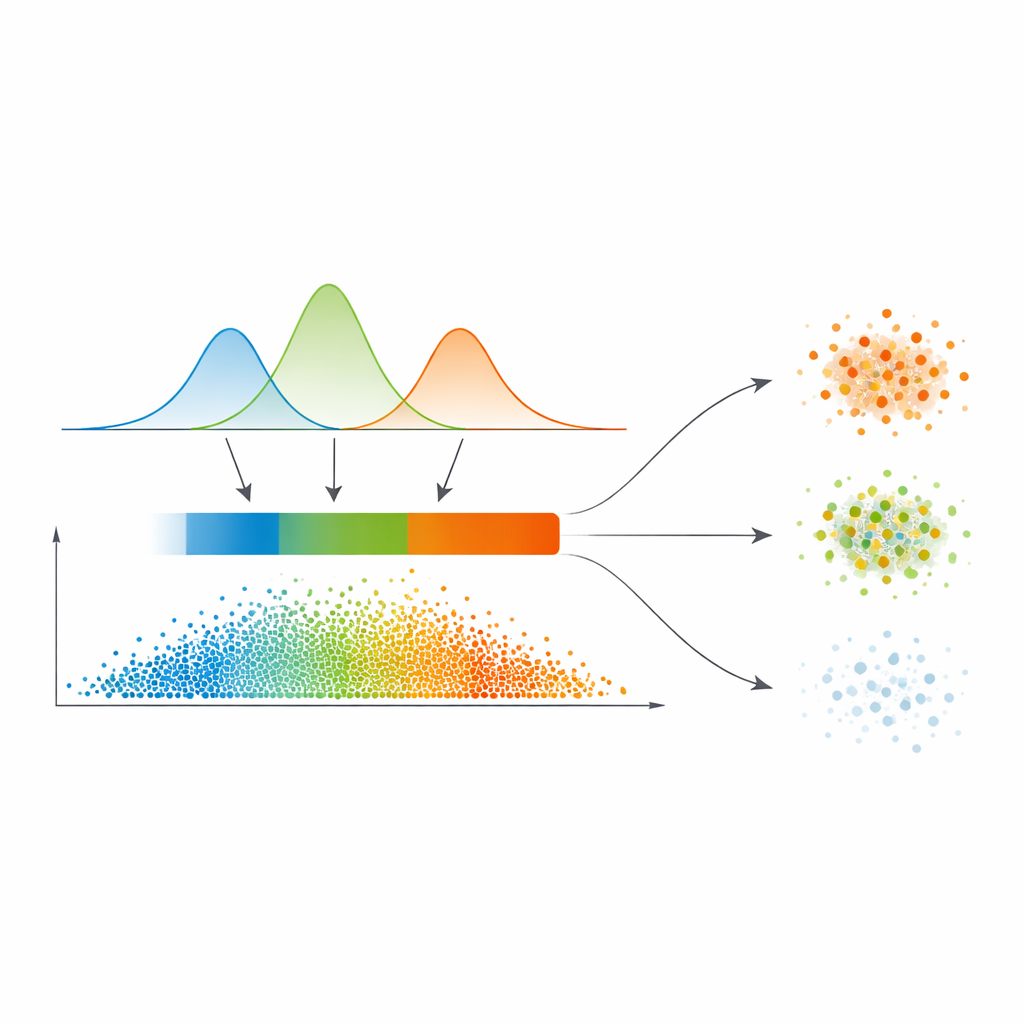
Van vloeiende waarschijnlijkheden naar drie betrouwbaarheidsgebieden
In plaats van direct harde lijnen te trekken uit deze gelijkeniskaart passen de auteurs een statistisch model toe, een Gaussiaanse mengvorm, op de verdeling van gelijkeniswaarden. In eenvoudige bewoordingen laten ze meerdere vloeiende krommen verklaren waar gelijkenis typisch laag, middel of hoog is. Dit model kiest automatisch hoeveel van zulke regimes nodig zijn, waarbij het schonere scheidingen prefereert. Voor elk datapunt worden de relaties met anderen omgezet in een kans om tot elke cluster te behoren, en de maximale van deze kansen wordt een eenvoudige maat voor vertrouwen. Een automatische drempelstap, geleend uit beeldverwerking, hakt de data vervolgens in drie zones: een hoogvertrouwens “kern”, een tussenliggende “grens” en een laagvertrouwens “triviaal of ruis” gebied.
Helder, vager en ruisachtig anders behandelen
Wat dit werk onderscheidt is hoe het deze drie gebieden behandelt. Punten in de kern worden direct toegewezen aan de cluster met de hoogste kans — dit zijn de makkelijke gevallen. Grenspunten, waar meningen botsen, putten kracht uit hun zekere buren via een verfijnd stemschema dat leunt op de gelijkeniskaart. Werkelijk twijfelachtige punten in het triviale gebied krijgen ofwel een voorlopige label of worden expliciet als ruis gemarkeerd, in plaats van te worden gedwongen in een cluster te worden geplaatst. Deze gelaagde strategie komt overeen met de natuurlijke manier waarop mensen onder onzekerheid redeneren: accepteer wat duidelijk is, stel uit wat ambigu is, en isoleer wat onbetrouwbaar lijkt.
Hoe goed het in de praktijk werkt
De auteurs testen hun aanpak op acht diverse datasets, variërend van klassieke kleine benchmarks tot het populaire MNIST-handgeschreven cijferset. Ze vergelijken met negen bestaande methoden, waaronder zowel traditionele ensembles als recentere, meer verfijnde technieken. In het algemeen levert de nieuwe methode de beste gemiddelde prestaties, met vooral sterke winst bij moeilijke problemen waar clusters overlappen of in hoge dimensies bestaan. Zorgvuldige statistische tests ondersteunen deze verbeteringen, en aanvullende experimenten tonen hoe elk onderdeel — de kwaliteitsweging, probabilistische modellering en de drie-weg-beslissing — bijdraagt aan de uiteindelijke nauwkeurigheid. De keerzijde is rekentijd: het modelleren van alle paargewijze relaties groeit kwadratisch met de datasetgrootte.
Wat dit betekent voor het groeperen van real-world data
Voor niet-specialisten is de belangrijkste boodschap dat het artikel een principiële manier biedt om niet alleen te zeggen “dit zijn de groepen”, maar ook “dit is hoe zeker we zijn over elke toewijzing.” Door vele clusteringpogingen te mengen, onzekerheid expliciet te modelleren en duidelijke gevallen te scheiden van vage en ruisachtige, produceert de methode betrouwbaardere groeperingen, met name in rommelige, realistische data. Hoewel het rekenkundig zwaarder is, biedt het een waardevol instrument wanneer betrouwbaarheid en interpretatie belangrijker zijn dan ruwe snelheid.
Bronvermelding: Ma, Y., Li, Z. Clustering ensemble method integrating Gaussian mixture model and three-way decision (GMM-3WD-CE). Sci Rep 16, 11740 (2026). https://doi.org/10.1038/s41598-026-47453-2
Trefwoorden: clustering ensemble, onbegeleid leren, onzekerheidsmodellering, Gaussiaanse mengvorm, data-mining