Clear Sky Science · pl
Metoda zespołu klasteryzacji integrująca model mieszaniny Gaussa i trójdzielną decyzję (GMM-3WD-CE)
Dlaczego łączenie wielu słabych perspektyw może ujawnić ukryte wzorce
Od wykrywania sygnatur chorób w danych medycznych po porządkowanie milionów zdjęć, komputery często muszą grupować podobne obiekty bez wcześniejszych etykiet — zadanie zwane klasteryzacją. Jednak pojedyncze podejście do klasteryzacji może być kruche: zmiana ustawienia lub punktu startowego może przesunąć grupy. Artykuł przedstawia nowy sposób łączenia wielu takich niedoskonałych klasteryzacji w bardziej wiarygodny, świadomy niepewności wynik, oferując jaśniejszy obraz tego, którym podziałom można zaufać, a które pozostają wątpliwe.
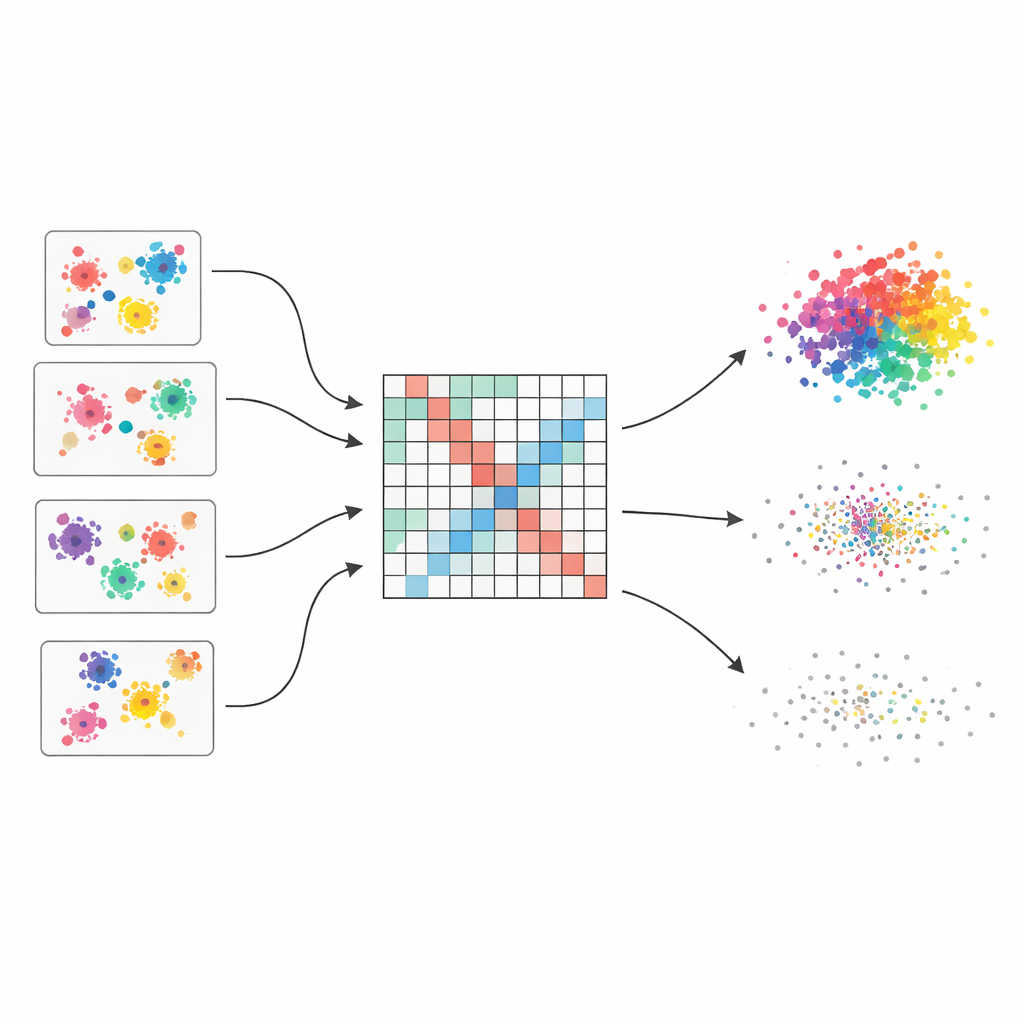
Wiele opinii zamiast jednej kruchej hipotezy
Autorzy wychodzą od koncepcji „zespołu klasteryzacji”, która działa trochę jak pytanie wielu ekspertów o ich zdanie, a następnie połączenie odpowiedzi. Generują pięćdziesiąt różnych klasteryzacji tego samego zbioru danych, używając czterech popularnych algorytmów, każdy z nieznacznie zmienionymi ustawieniami. Ponieważ każda metoda dostrzega strukturę w inny sposób — jedne preferują okrągłe klastry, inne radzą sobie z nieregularnymi kształtami lub zróżnicowaną gęstością — zespół obejmuje szeroki zakres możliwych podziałów. Kluczowym wyzwaniem jest więc scalić te rozproszone opinie w spójny obraz.
Przekształcanie rozproszonych głosów w gładki obraz podobieństwa
Aby zespolić te liczne spojrzenia, metoda najpierw buduje dużą tabelę rejestrującą, jak często każda para punktów danych trafia do tego samego klastra we wszystkich uruchomieniach. Tabeli tej nie traktuje się naiwnie: każdej bazowej klasteryzacji przypisywana jest ocena jakości oparta na trzech znanych indeksach, które premiują dobrze rozdzielone i zwarte grupy oraz penalizują chaotyczne podziały. Lepsze klasteryzacje mają większy wpływ na końcowy wynik. Efektem jest „ważona macierz współasocjacji”, która działa jak mapka w miękkim fokusie pokazująca, kto ma tendencję do bycia razem — z wyraźnymi sygnałami tam, gdzie dowody są spójne, i delikatniejszymi odcieniami tam, gdzie opinie się różnią.
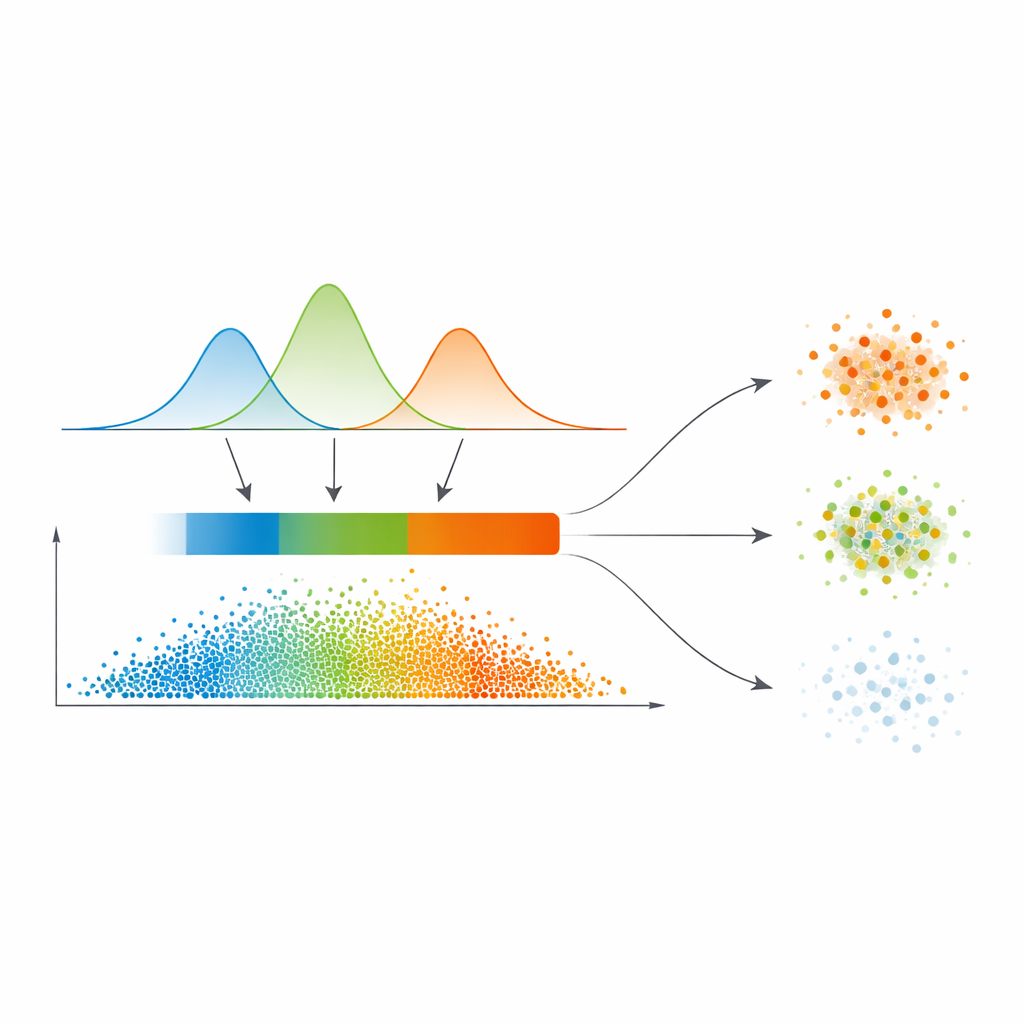
Z gładkich prawdopodobieństw do trzech stref zaufania
Zamiast wyciągać ostre granice bezpośrednio z tej mapy podobieństwa, autorzy dopasowują model statystyczny zwany mieszaniną Gaussa do rozkładu wartości podobieństwa. Mówiąc prościej, pozwalają kilku gładkim krzywym wyjaśnić, gdzie podobieństwo jest zwykle niskie, średnie lub wysokie. Model automatycznie wybiera, ile takich reżimów jest potrzebnych, preferując czyściejsze separacje. Dla każdego punktu dane o jego relacjach z innymi przekształcane są w prawdopodobieństwo przynależności do każdego klastra, a maksimum tych prawdopodobieństw staje się prostą miarą pewności. Automatyczny krok progowania, zapożyczony z przetwarzania obrazów, dzieli następnie dane na trzy strefy: wysokiego zaufania „rdzeń”, pośrednią „granice” oraz niskiego zaufania „strefę trywialną lub szumową”.
Różne traktowanie punktów wyraźnych, nieostrych i szumowych
Co wyróżnia tę pracę, to sposób traktowania tych trzech stref. Punkty w rdzeniu są przypisywane bezpośrednio do klastra o najwyższym prawdopodobieństwie — to proste przypadki. Punkty brzegowe, gdzie opinie się ścierają, czerpią siłę od swoich pewnych sąsiadów za pomocą udoskonalonego schematu głosowania opartego na mapie podobieństwa. Naprawdę wątpliwe punkty w strefie trywialnej otrzymują albo tymczasową etykietę, albo są wyraźnie oznaczane jako szum, zamiast być na siłę wtłaczane do klastra. Taka wielopoziomowa strategia odpowiada naturalnemu sposobowi ludzkiego rozumowania w obliczu niepewności: zaakceptuj to, co jasne, odłóż na później to, co niejednoznaczne, i izoluj to, co wydaje się niewiarygodne.
Jak to działa w praktyce
Autorzy testują swoje podejście na ośmiu zróżnicowanych zbiorach danych, od klasycznych małych benchmarków po popularne cyfry ręcznie pisane MNIST. Porównują je z dziewięcioma istniejącymi metodami, obejmującymi zarówno tradycyjne zespoły, jak i nowsze, zaawansowane techniki. Ogólnie nowa metoda osiąga najlepszą średnią wydajność, z szczególnie silnymi zyskami w trudnych problemach, gdzie klastry się pokrywają lub występują w wysokich wymiarach. Dokładne testy statystyczne potwierdzają te ulepszenia, a dodatkowe eksperymenty pokazują, jak każdy komponent — ważenie jakości, modelowanie probabilistyczne i krok trójdzielnej decyzji — przyczynia się do końcowej dokładności. Kosztem jest czas obliczeń: modelowanie wszystkich relacji parami rośnie kwadratowo wraz z wielkością zbioru danych.
Co to oznacza dla grupowania danych w praktyce
Dla niespecjalistów główny wniosek jest taki, że artykuł proponuje zasadniczy sposób, by powiedzieć nie tylko „to są grupy”, ale także „oto, jak bardzo jesteśmy pewni każdego przypisania”. Poprzez łączenie wielu prób klasteryzacji, jawne modelowanie niepewności i rozdzielenie przypadków jasnych od nieostrych i szumowych, metoda daje bardziej godne zaufania podziały, szczególnie w chaotycznych, rzeczywistych danych. Choć wymaga większych zasobów obliczeniowych, stanowi cenne narzędzie, gdy wiarygodność i interpretowalność są ważniejsze niż surowa szybkość.
Cytowanie: Ma, Y., Li, Z. Clustering ensemble method integrating Gaussian mixture model and three-way decision (GMM-3WD-CE). Sci Rep 16, 11740 (2026). https://doi.org/10.1038/s41598-026-47453-2
Słowa kluczowe: zespół klasteryzacji, uczenie bez nadzoru, modelowanie niepewności, model mieszaniny Gaussa, eksploracja danych