Clear Sky Science · pt
Método de conjunto de clusterização integrando modelo de mistura Gaussiana e decisão ternária (GMM-3WD-CE)
Por que combinar muitas visões fracas pode revelar padrões ocultos
De identificar assinaturas de doenças em dados médicos a organizar milhões de fotos, computadores frequentemente precisam agrupar itens semelhantes sem rótulos prévios — uma tarefa chamada clusterização. Porém, qualquer tentativa isolada de clusterização pode ser frágil: mude um parâmetro ou o ponto de partida e os grupos podem mudar. Este artigo introduz uma nova forma de combinar várias clusterizações imperfeitas em um resultado mais confiável e consciente da incerteza, oferecendo uma visão mais clara de quais agrupamentos podemos confiar e quais permanecem duvidosos.
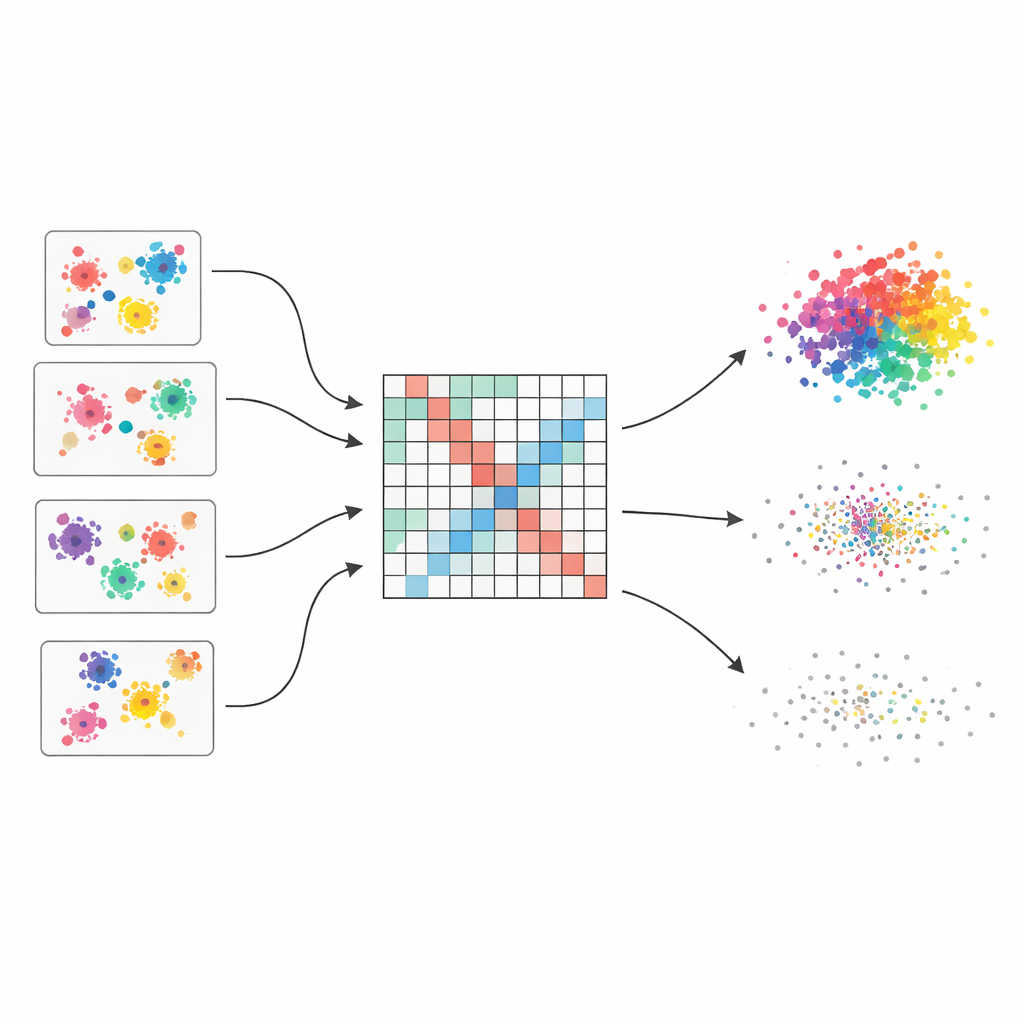
Muitas opiniões em vez de um palpite frágil
Os autores partem da ideia de um “conjunto de clusterizações”, que funciona um pouco como pedir a opinião de vários especialistas e então combiná-las. Eles geram cinquenta clusterizações diferentes do mesmo conjunto de dados usando quatro algoritmos populares, cada um com configurações levemente variadas. Como cada método enxerga a estrutura de maneira distinta — alguns privilegiam grupos arredondados, outros lidam melhor com formas irregulares ou densidades mistas — o conjunto captura uma ampla gama de agrupamentos plausíveis. O desafio central é então fundir essas opiniões dispersas em uma única imagem coerente.
Transformando votos dispersos em um quadro suave de similaridade
Para fundir essas várias visões, o método primeiro constrói uma grande tabela que registra quão frequentemente cada par de pontos de dados termina no mesmo cluster ao longo de todas as execuções. Essa tabela não é tratada de forma ingênua: cada clusterização base recebe uma pontuação de qualidade baseada em três índices bem conhecidos que recompensam grupos bem separados e compactos e penalizam agrupamentos confusos. Clusterizações melhores têm mais peso na contagem final. O resultado é uma “matriz de co-associação ponderada” que atua como um mapa em foco suave de quem tende a pertencer junto, com sinais fortes onde a evidência é consistente e tons mais suaves onde as opiniões divergem.
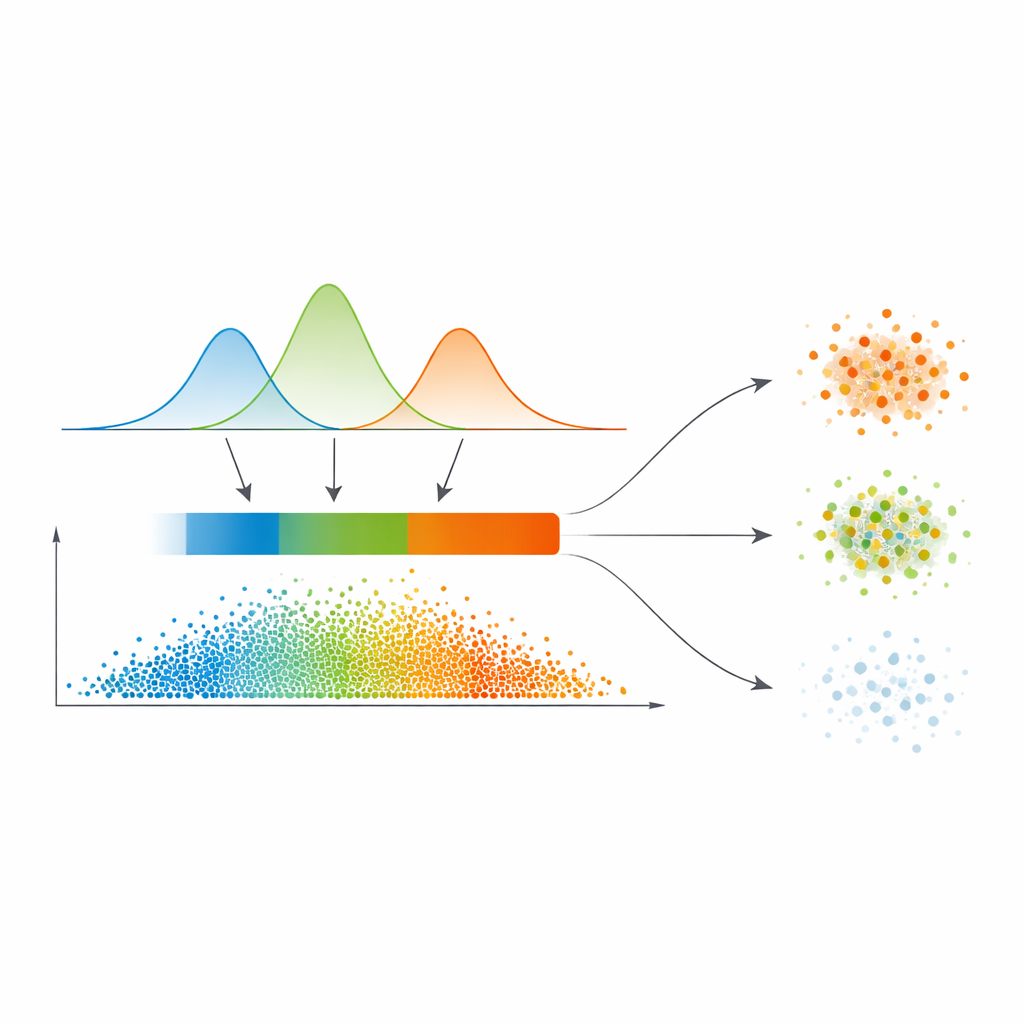
De probabilidades suaves a três regiões de confiança
Em vez de traçar linhas rígidas diretamente a partir desse mapa de similaridade, os autores ajustam um modelo estatístico chamado mistura Gaussiana à distribuição dos valores de similaridade. Em termos simples, eles deixam várias curvas suaves explicarem onde a similaridade costuma ser baixa, média ou alta. Esse modelo escolhe automaticamente quantos desses regimes são necessários, favorecendo separações mais limpas. Para cada ponto de dado, suas relações com os demais são convertidas em probabilidade de pertencer a cada cluster, e o máximo dessas probabilidades torna-se uma medida simples de confiança. Um passo automático de limiarização, emprestado do processamento de imagens, então divide os dados em três zonas: um “núcleo” de alta confiança, uma “fronteira” intermediária e uma região de baixa confiança considerada trivial ou ruidosa.
Tratar pontos claros, ambíguos e ruidosos de forma diferente
O que diferencia este trabalho é a forma como ele trata essas três regiões. Pontos no núcleo são atribuídos diretamente ao cluster com maior probabilidade — são os casos fáceis. Pontos da fronteira, onde as opiniões divergem, tomam emprestado o sinal de seus vizinhos confiantes por meio de um esquema refinado de votação que se apoia no mapa de similaridade. Pontos realmente duvidosos na região trivial recebem ou um rótulo provisório ou são explicitamente marcados como ruído, em vez de serem forçados a entrar em um cluster. Essa estratégia em camadas corresponde à forma natural como humanos raciocinam sob incerteza: aceitar o que é claro, adiar o que é ambíguo e isolar o que parece pouco confiável.
Como funciona na prática
Os autores testam sua abordagem em oito conjuntos de dados diversos, variando de benchmarks clássicos menores ao popular MNIST de dígitos manuscritos. Eles comparam com nove métodos existentes, incluindo tanto conjuntos tradicionais quanto técnicas mais recentes e sofisticadas. No geral, o novo método apresenta a melhor performance média, com ganhos especialmente fortes em problemas difíceis onde os clusters se sobrepõem ou vivem em altas dimensões. Testes estatísticos cuidadosos corroboram essas melhorias, e experimentos adicionais mostram como cada componente — a ponderação por qualidade, a modelagem probabilística e a etapa de decisão ternária — contribui para a acurácia final. O custo é o tempo de computação: modelar todas as relações pareadas cresce quadraticamente com o tamanho do conjunto de dados.
O que isso significa para agrupamento de dados no mundo real
Para não especialistas, a mensagem principal é que o artigo oferece uma maneira fundamentada de dizer não apenas “estes são os grupos”, mas também “assim estamos certos sobre cada atribuição”. Ao combinar muitas tentativas de clusterização, modelar explicitamente a incerteza e separar casos claros dos ambíguos e ruidosos, o método produz agrupamentos mais confiáveis, particularmente em dados reais e confusos. Embora seja mais exigente computacionalmente, ele fornece uma ferramenta valiosa quando confiabilidade e interpretabilidade importam mais do que velocidade pura.
Citação: Ma, Y., Li, Z. Clustering ensemble method integrating Gaussian mixture model and three-way decision (GMM-3WD-CE). Sci Rep 16, 11740 (2026). https://doi.org/10.1038/s41598-026-47453-2
Palavras-chave: conjunto de clusterização, aprendizado não supervisionado, modelagem de incerteza, modelo de mistura Gaussiana, mineração de dados