Clear Sky Science · it
Metodo di ensemble di clustering che integra modello di miscela gaussiana e decisione a tre vie (GMM-3WD-CE)
Perché combinare molte visioni deboli può rivelare schemi nascosti
Dalla individuazione di segnature di malattie nei dati medici all’organizzazione di milioni di foto, i computer spesso devono raggruppare elementi simili senza etichette pregresse — un compito chiamato clustering. Tuttavia ogni singolo tentativo di clustering può essere fragile: cambiando un parametro o l’inizializzazione i gruppi possono spostarsi. Questo articolo introduce un nuovo modo di combinare molte di queste partizioni imperfette in un risultato più affidabile e consapevole dell’incertezza, offrendo un quadro più chiaro di quali raggruppamenti possiamo fidarci e quali restano dubbi.
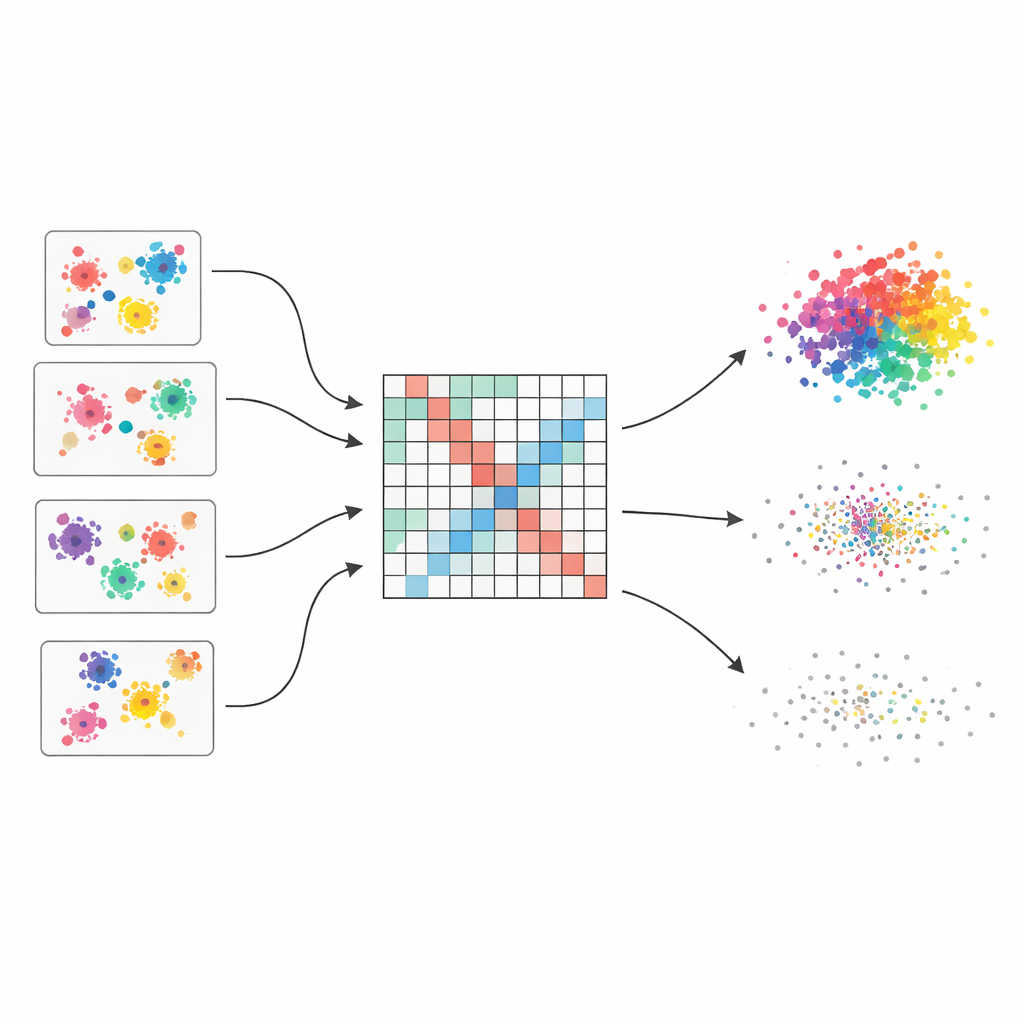
Molte opinioni invece di una singola ipotesi fragile
Gli autori partono dall’idea di un “ensemble di clustering”, che funziona un po’ come chiedere a più esperti il loro parere e poi combinarli. Generano cinquanta diverse partizioni dello stesso dataset usando quattro algoritmi popolari, ciascuno con impostazioni leggermente variate. Poiché ogni metodo coglie la struttura in modo diverso — alcuni favoriscono gruppi tondeggianti, altri gestiscono forme irregolari o densità miste — l’ensemble cattura un ampio ventaglio di raggruppamenti plausibili. La sfida centrale è quindi fondere queste opinioni sparse in un’unica immagine coerente.
Trasformare voti sparsi in una mappa continua di similarità
Per fondere queste molteplici visioni, il metodo costruisce prima una grande tabella che registra quanto spesso ogni coppia di punti dati finisce nello stesso cluster attraverso tutte le esecuzioni. Questa tabella non viene trattata ingenuamente: a ogni partizione base viene assegnato un punteggio di qualità basato su tre indici noti che premiano gruppi ben separati e compatti e penalizzano quelli disordinati. Le migliori partizioni hanno quindi più peso nel conteggio finale. Il risultato è una “matrice di co-associazione pesata” che agisce come una mappa a fuoco morbido di chi tende ad appartenere insieme, con segnali forti dove le evidenze sono coerenti e sfumature più deboli dove le opinioni divergono.
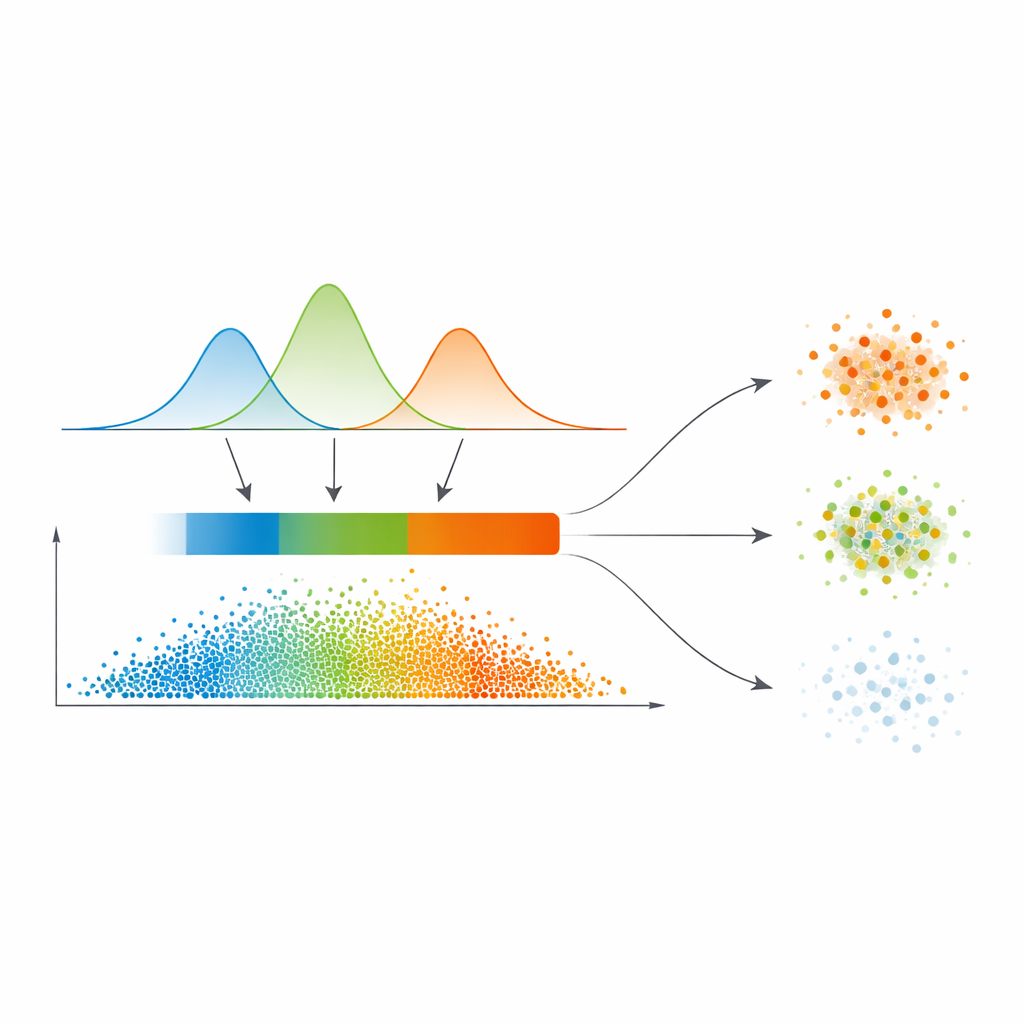
Dalle probabilità continue a tre regioni di confidenza
Invece di tracciare linee nette direttamente da questa mappa di similarità, gli autori adattano un modello statistico chiamato miscela gaussiana alla distribuzione dei valori di similarità. In termini semplici, lasciano che diverse curve morbide spieghino dove la similarità è tipicamente bassa, media o alta. Il modello sceglie automaticamente quante di queste modalità sono necessarie, privilegiando separazioni più nette. Per ogni punto dati, le sue relazioni con gli altri vengono convertite in una probabilità di appartenenza a ciascun cluster, e il massimo di queste probabilità diventa una misura semplice di fiducia. Un passaggio di sogliatura automatica, tratto dall’elaborazione delle immagini, quindi suddivide i dati in tre zone: un “nucleo” ad alta confidenza, una “frontiera” intermedia e una regione a bassa confidenza considerata ‘triviale o rumorosa’.
Trattare diversamente punti chiari, sfumati e rumorosi
Ciò che distingue questo lavoro è il modo in cui vengono gestite queste tre regioni. I punti nel nucleo vengono assegnati direttamente al cluster con la probabilità più alta — questi sono i casi facili. I punti di frontiera, dove le opinioni si scontrano, prendono forza dai vicini più sicuri tramite uno schema di voto raffinato che si appoggia alla mappa di similarità. I punti realmente dubbi nella regione banale vengono o etichettati in modo provvisorio o marcati esplicitamente come rumore, invece di essere forzati in un cluster. Questa strategia a più livelli rispecchia il modo naturale in cui gli esseri umani ragionano sotto incertezza: accettare ciò che è chiaro, rinviare ciò che è ambiguo e isolare ciò che sembra inaffidabile.
Quanto funziona nella pratica
Gli autori testano il loro approccio su otto dataset diversi, che vanno da classici benchmark di piccole dimensioni al popolare MNIST di cifre scritte a mano. Confrontano con nove metodi esistenti, includendo sia ensemble tradizionali sia tecniche più recenti e sofisticate. Complessivamente, il nuovo metodo offre la migliore prestazione media, con guadagni particolarmente marcati su problemi difficili dove i cluster si sovrappongono o vivono in spazi ad alta dimensione. Test statistici accurati supportano questi miglioramenti, e ulteriori esperimenti mostrano come ciascun componente — il peso di qualità, la modellazione probabilistica e il passo di decisione a tre vie — contribuisca all’accuratezza finale. Il compromesso è il tempo di calcolo: modellare tutte le relazioni a coppie cresce quadraticamente con la dimensione del dataset.
Cosa significa per il raggruppamento dei dati nel mondo reale
Per i non specialisti, il messaggio principale è che l’articolo propone un modo principled per dire non solo “questi sono i gruppi”, ma anche “ecco quanto siamo sicuri di ciascuna assegnazione”. Combinando molteplici tentativi di clustering, modellando esplicitamente l’incertezza e separando i casi chiari da quelli sfumati e rumorosi, il metodo produce raggruppamenti più affidabili, specialmente su dati reali, disordinati. Pur essendo più esigente dal punto di vista computazionale, fornisce uno strumento prezioso quando l’affidabilità e l’interpretabilità contano più della pura velocità.
Citazione: Ma, Y., Li, Z. Clustering ensemble method integrating Gaussian mixture model and three-way decision (GMM-3WD-CE). Sci Rep 16, 11740 (2026). https://doi.org/10.1038/s41598-026-47453-2
Parole chiave: ensemble di clustering, apprendimento non supervisionato, modellazione dell'incertezza, modello di miscela gaussiana, data mining