Clear Sky Science · ru
Метод ансамбля кластеризации, объединяющий модель гауссовой смеси и трехстороннее решение (GMM-3WD-CE)
Почему объединение множества слабых мнений может выявить скрытые закономерности
От поиска признаков заболеваний в медицинских данных до организации миллионов фотографий — компьютерам часто нужно группировать похожие объекты без каких‑либо заранее заданных меток. Эта задача называется кластеризацией. Однако одиночная попытка кластеризации может быть хрупкой: измените параметр или начальную инициализацию, и группы могут сильно измениться. В статье предлагается новый способ объединения множества таких несовершенных кластеризаций в более надёжный результат с учётом неопределённости, что даёт яснее представление о том, какие разбиения заслуживают доверия, а какие остаются спорными.
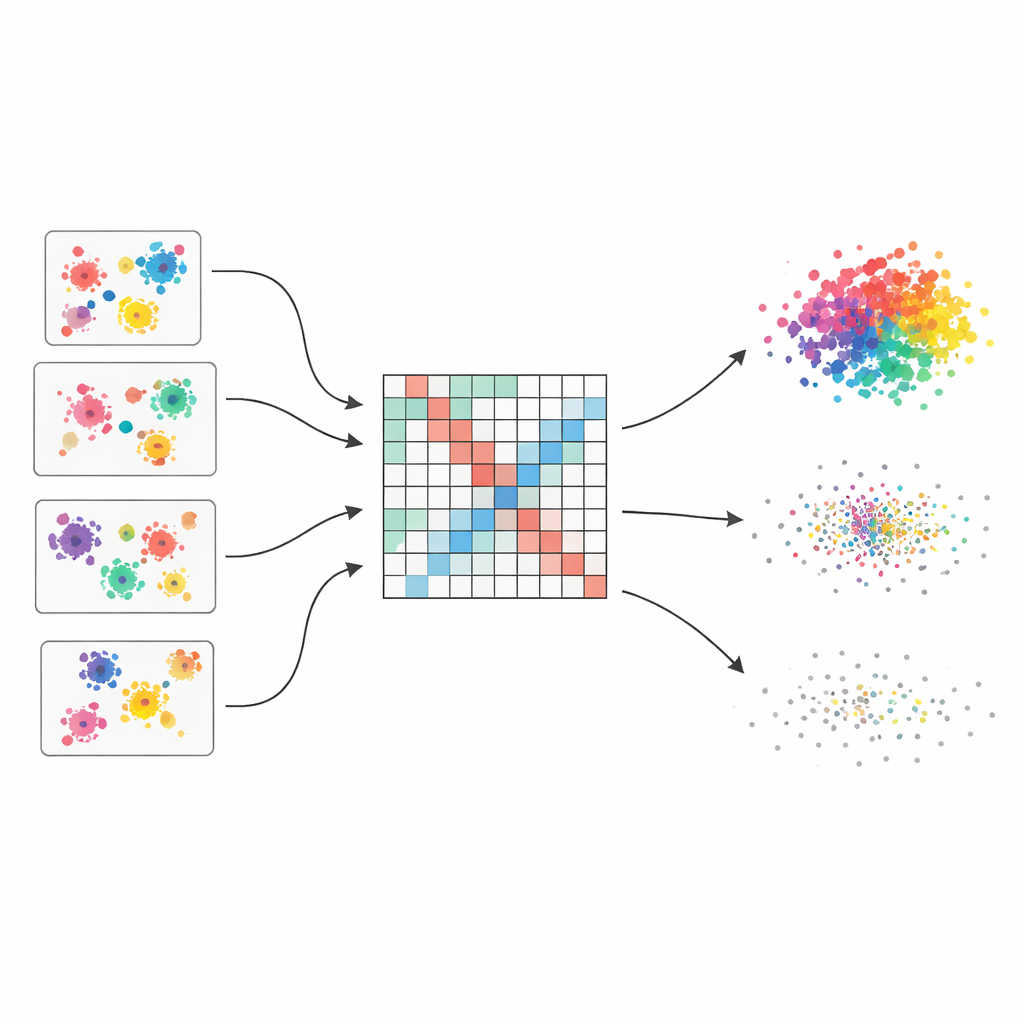
Множество мнений вместо одного хрупкого предположения
Авторы исходят из идеи «ансамбля кластеризаций», который работает чуть похоже на опрос нескольких экспертов с последующим объединением их мнений. Они генерируют пятьдесят разных разбиений одного и того же набора данных, используя четыре популярных алгоритма с небольшими вариациями настроек. Поскольку каждый метод «видит» структуру по‑своему — одни предпочитают круглые кластеры, другие справляются со странными формами или смешанной плотностью — ансамбль охватывает широкий спектр правдоподобных разбиений. Основная задача затем заключается в том, чтобы слить эти разрозненные мнения в единое, согласованное представление.
Преобразование разрозненных голосов в плавную карту сходства
Чтобы объединить множество представлений, метод сначала строит большую таблицу, фиксирующую, как часто каждая пара объектов оказывается в одном кластере во всех запусках. Эту таблицу не используют наивно: каждой базовой кластеризации присваивается оценка качества на основе трёх известных индексов, которые поощряют хорошо разъединённые и компактные группы и штрафуют за нечеткость. Лучшие разбиения имеют больший вес в итоговом подсчёте. В результате получается «взвешенная матрица соассоциаций», действующая как карта в мягком фокусе — с сильными сигналами там, где доказательства согласуются, и более размытыми зонами там, где мнения расходятся.
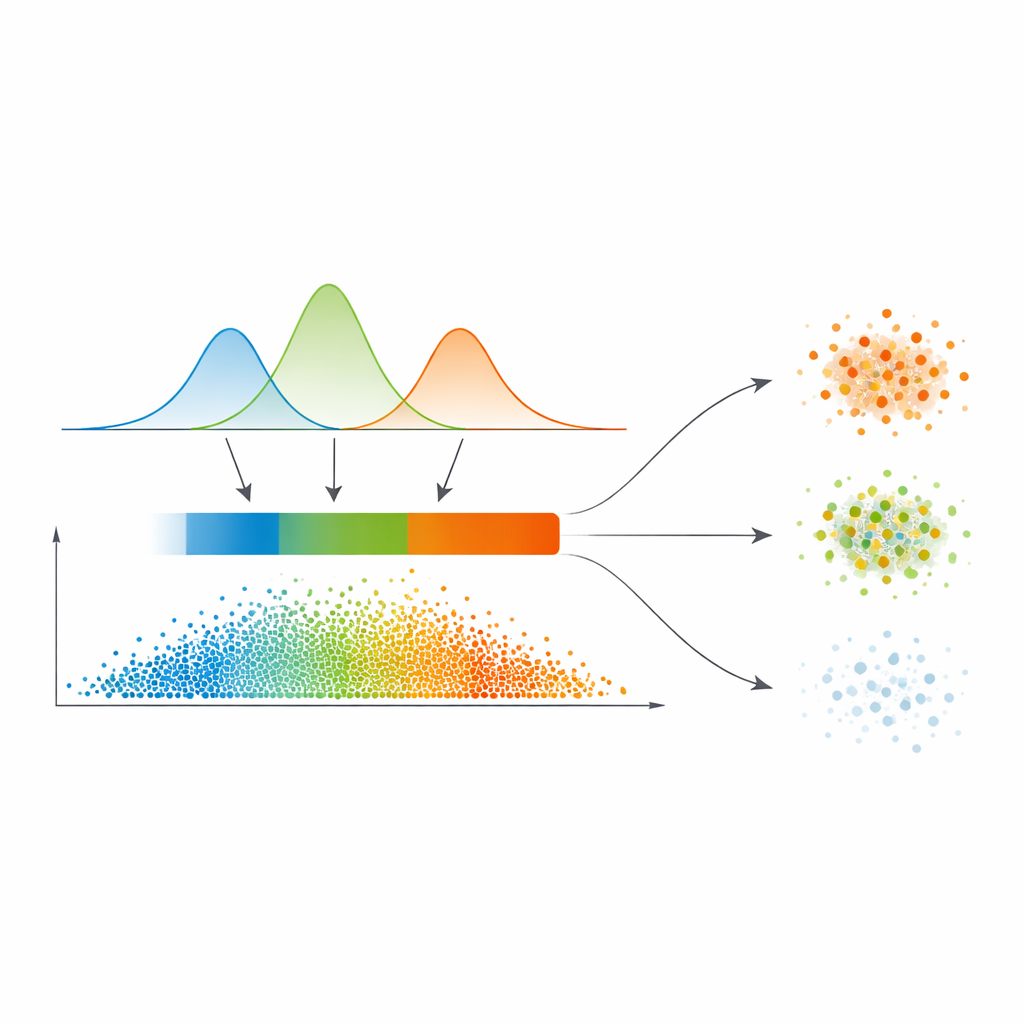
От плавных вероятностей к трём областям доверия
Вместо того чтобы напрямую проводить жёсткие границы по этой карте сходства, авторы подгоняют статистическую модель, называемую гауссовой смесью, к распределению значений сходства. Проще говоря, несколько гладких компонент описывают, где сходство обычно низкое, среднее или высокое. Модель автоматически выбирает необходимое число режимов, отдавая предпочтение более чистым разделениям. Для каждого объекта его связи с другими преобразуются в вероятность принадлежности к каждому кластеру, а максимум этих вероятностей становится простым мерилом уверенности. Автоматический шаг пороговой обработки, заимствованный из обработки изображений, затем делит данные на три зоны: высокоуверенную «ядро», промежуточную «границу» и низкоуверенную «тривиальную или шумовую» область.
Разный подход к очевидным, неясным и шумным точкам
Что отличает эту работу, так это способ обращения с этими тремя областями. Точки в ядре назначаются напрямую в кластер с наивысшей вероятностью — это простые случаи. Границы, где мнения расходятся, получают поддержку от уверенных соседей через уточнённую схему голосования, опирающуюся на карту сходства. По‑настоящему сомнительные точки в тривиальной области либо получают предварительную метку, либо явно помечаются как шум, вместо того чтобы их принудительно помещали в кластер. Такая многоуровневая стратегия соответствует естественному человеческому подходу к неуверенности: принимать очевидное, откладывать спорное и изолировать ненадёжное.
Насколько хорошо это работает на практике
Авторы проверяют подход на восьми разнообразных наборах данных — от классических небольших бенчмарков до популярного набора рукописных цифр MNIST. Они сравнивают метод с девятью существующими подходами, включая как традиционные ансамбли, так и более современные сложные техники. В целом новый метод показывает лучшую среднюю производительность, с особенно заметным преимуществом на сложных задачах, где кластеры перекрываются или находятся в высоких размерностях. Тщательные статистические тесты подтверждают эти улучшения, а дополнительные эксперименты показывают вклад каждого компонента — взвешивания качества, вероятностного моделирования и шага трёхстороннего решения — в итоговую точность. Цена за это — время вычислений: моделирование всех парных отношений растёт квадратично с размером набора данных.
Что это значит для группировки реальных данных
Для неспециалистов главный вывод в том, что статья предлагает принципиальный способ не просто назвать «вот группы», но и сказать «насколько мы уверены в каждом назначении». Объединяя множество попыток кластеризации, явно моделируя неопределённость и отделяя очевидные случаи от неясных и шумных, метод даёт более надёжные разбиения, особенно на запутанных, реальных данных. Хотя он более требователен по вычислительным ресурсам, он представляет собой ценный инструмент, когда надёжность и интерпретируемость важнее чистой скорости.
Цитирование: Ma, Y., Li, Z. Clustering ensemble method integrating Gaussian mixture model and three-way decision (GMM-3WD-CE). Sci Rep 16, 11740 (2026). https://doi.org/10.1038/s41598-026-47453-2
Ключевые слова: ансамбль кластеризаций, обучение без учителя, моделирование неопределенности, модель гауссовой смеси, data mining