Clear Sky Science · es
Método de ensamblado de clustering que integra modelo de mezcla gaussiana y decisión ternaria (GMM-3WD-CE)
Por qué combinar muchas visiones débiles puede revelar patrones ocultos
Desde detectar firmas de enfermedades en datos médicos hasta organizar millones de fotos, los ordenadores a menudo necesitan agrupar elementos similares sin etiquetas previas: una tarea llamada clustering. Sin embargo, cualquier intento individual de clustering puede ser frágil: cambiar un parámetro o alterar el punto de partida puede desplazar los grupos. Este artículo presenta una forma nueva de combinar muchas de esas particiones imperfectas en un resultado más fiable y con conciencia de la incertidumbre, ofreciendo una imagen más clara de qué agrupaciones podemos confiar y cuáles siguen siendo dudosas.
Muchas opiniones en lugar de una conjetura frágil
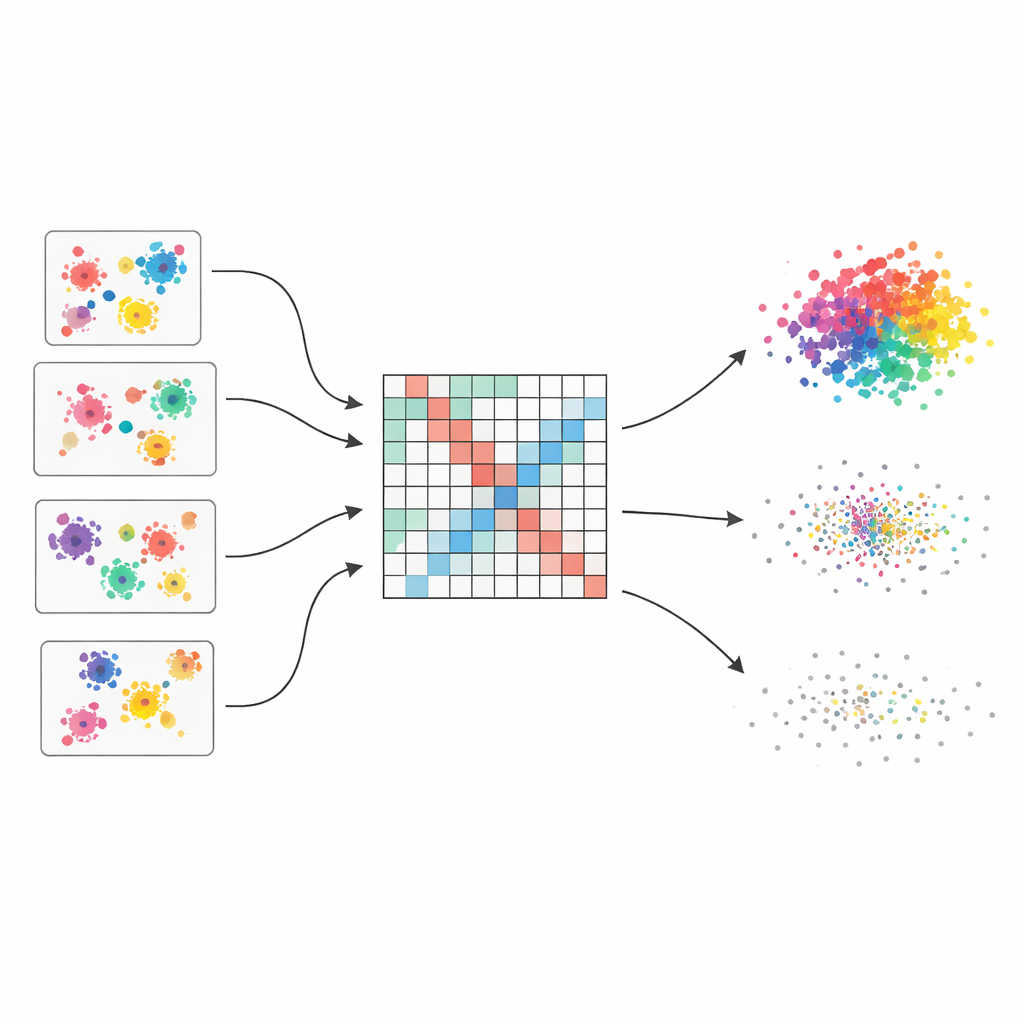
Los autores parten de la idea de un «ensamblado de clustering», que funciona un poco como pedir la opinión de varios expertos y luego combinarlas. Generan cincuenta particiones diferentes del mismo conjunto de datos usando cuatro algoritmos populares, cada uno con parámetros ligeramente variados. Dado que cada método percibe la estructura de forma distinta—algunos favorecen clusters redondeados, otros manejan formas extrañas o densidades mixtas—el ensamblado captura una amplia gama de agrupaciones plausibles. El reto central es entonces fusionar estas opiniones dispersas en una imagen única y coherente.
Convertir votos dispersos en un mapa suave de similitud
Para fusionar estas múltiples visiones, el método construye primero una gran tabla que registra con qué frecuencia cada par de puntos de datos acaba en el mismo cluster a lo largo de todas las ejecuciones. Esta tabla no se trata de forma ingenua: cada partición base recibe una puntuación de calidad basada en tres índices bien conocidos que premian grupos bien separados y compactos y penalizan los desordenados. Las particiones mejores tienen más peso en el recuento final. El resultado es una «matriz de co-asociación ponderada» que actúa como un mapa en suave foco de quién tiende a pertenecer junto, con señales fuertes donde la evidencia es consistente y matices más suaves donde difieren las opiniones.
De probabilidades suaves a tres regiones de confianza
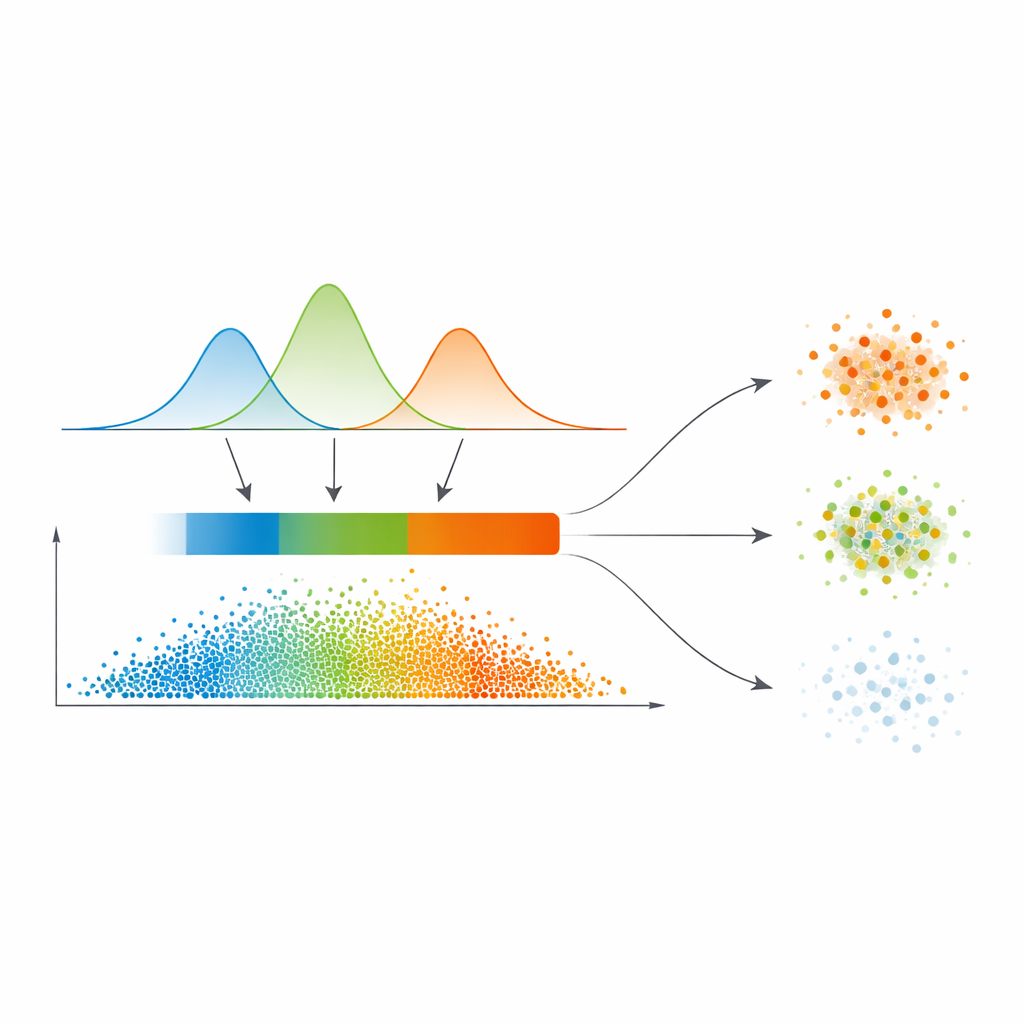
En lugar de trazar líneas duras directamente a partir de este mapa de similitud, los autores ajustan un modelo estadístico llamado mezcla gaussiana a la distribución de valores de similitud. En términos sencillos, permiten que varias curvas suaves expliquen dónde la similitud suele ser baja, media o alta. Este modelo elige automáticamente cuántos de esos regímenes son necesarios, favoreciendo separaciones más claras. Para cada punto de datos, sus relaciones con los demás se convierten en una probabilidad de pertenecer a cada cluster, y el máximo de estas probabilidades se usa como una medida simple de confianza. Un paso de umbralización automática, tomado de procesamiento de imágenes, talla entonces los datos en tres zonas: un «núcleo» de alta confianza, una «frontera» intermedia y una región de baja confianza «trivial o ruidosa».
Tratar puntos claros, difusos y ruidosos de forma distinta
Lo que distingue este trabajo es cómo trata estas tres regiones. Los puntos en el núcleo se asignan directamente al cluster con mayor probabilidad: son los casos sencillos. Los puntos de la frontera, donde las opiniones chocan, toman fuerza de sus vecinos confiables mediante un esquema de votación refinado que se apoya en el mapa de similitud. Los puntos verdaderamente dudosos en la región trivial reciben o bien una etiqueta tentativa o bien se marcan explícitamente como ruido, en lugar de forzarlos a pertenecer a un cluster. Esta estrategia por niveles coincide con la forma natural en que los humanos razonan bajo incertidumbre: aceptar lo claro, postergar lo ambiguo e aislar lo que parece poco fiable.
Qué tan bien funciona en la práctica
Los autores prueban su enfoque en ocho conjuntos de datos diversos, que van desde benchmarks clásicos pequeños hasta el popular MNIST de dígitos manuscritos. Comparan con nueve métodos existentes, incluidos ensamblados tradicionales y técnicas más recientes y sofisticadas. En conjunto, el nuevo método ofrece el mejor rendimiento medio, con ganancias especialmente fuertes en problemas difíciles donde los clusters se solapan o viven en altas dimensiones. Pruebas estadísticas cuidadosas respaldan estas mejoras, y experimentos adicionales muestran cómo cada componente—la ponderación por calidad, el modelado probabilístico y el paso de decisión ternaria—contribuye a la precisión final. El coste es el tiempo de cómputo: modelar todas las relaciones por pares crece cuadráticamente con el tamaño del conjunto de datos.
Qué significa esto para la agrupación de datos en el mundo real
Para no especialistas, el mensaje principal es que el artículo ofrece una manera fundada de decir no solo «estos son los grupos», sino también «aquí está cuán seguros estamos de cada asignación». Al combinar muchos intentos de clustering, modelar la incertidumbre explícitamente y separar los casos claros de los difusos y ruidosos, el método produce agrupaciones más confiables, especialmente en datos reales y desordenados. Aunque exige más recursos computacionales, proporciona una herramienta valiosa cuando la fiabilidad y la interpretabilidad importan más que la velocidad bruta.
Cita: Ma, Y., Li, Z. Clustering ensemble method integrating Gaussian mixture model and three-way decision (GMM-3WD-CE). Sci Rep 16, 11740 (2026). https://doi.org/10.1038/s41598-026-47453-2
Palabras clave: ensamblado de clustering, aprendizaje no supervisado, modelado de incertidumbre, modelo de mezcla gaussiana, minería de datos