Clear Sky Science · zh
MnMR-GenA:一种用于低资源语言越狱攻击的形态重组遗传算法
为何所有语言的 AI 更安全都很重要
随着强大聊天机器人在全球范围内传播,人们在数百种语言中使用它们,而不仅仅是英语或中文。然而,许多用以阻止有害回答的安全检查是基于研究充分的语言的数据进行调优的。本文提出了一个令人担忧的问题:在使用较少的语言中是否存在隐藏的薄弱点,使有害提示更容易绕过防护?如果存在,研究人员如何揭示这些盲点以提升系统安全性?
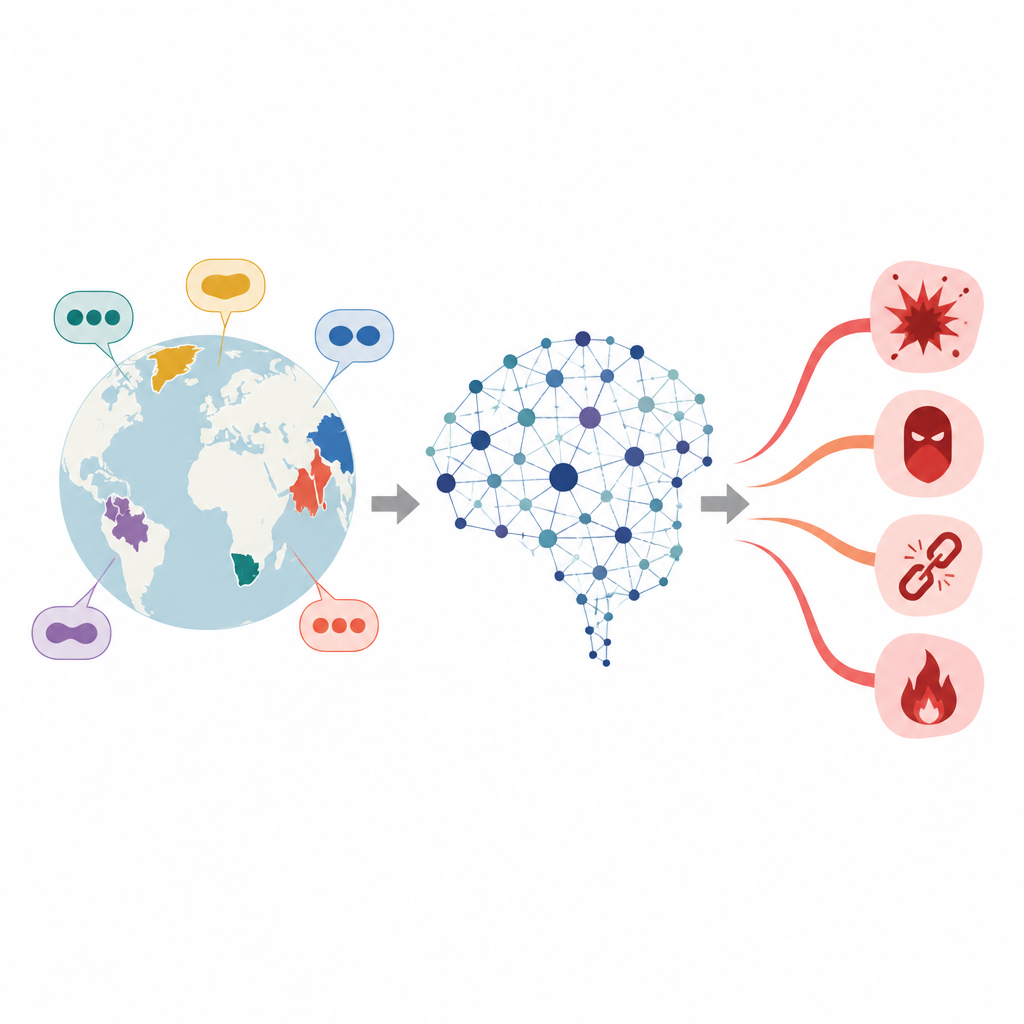
多语种 AI 安全中的隐蔽裂缝
大型语言模型从海量文本中学习,并在后期被调整以避免在犯罪、仇恨或其他危险主题上提供建议。然而,这类调优通常在训练数据丰富的高资源语言中最为有效。对于低资源语言,安全层要薄得多。既有研究表明,仅将有害的英语提示翻译成此类语言就能提高模型给出不安全回答的概率。作者将注意力集中在一类特殊语言——黏着语(agglutinative languages),这类语言通过串联多个较短的词素构成长词,从而大幅增加了有害请求可能的表述方式。
从简单翻译到进化式攻击提示
现有的大多数攻击可分为三类。一类依赖手写模板,指示模型“假装”或“忽略规则”,这类模板制作费时且易被公司修补。另一类利用对模型内部的直接访问来微调输入,但通常会产生可被检测器轻易识别的无意义字符串。第三类将模型视为黑箱,使用搜索或进化来重写提示,但通常只在单一层面上操作,例如对整句重写,这限制了创造力并常常破坏语义。基于翻译的攻击在低资源语言中表现更好,但仍保持英语原始提示的结构,未能充分利用黏着语灵活的词构造特性。
用于隐蔽提示的进化引擎
为突破这些限制,作者设计了 MnMR-GenA 框架,将每个有害提示视为一个不断演化的变体群体。它从已知的越狱提示入手,将其翻译为蒙古语、土耳其语和瓜拉尼语等低资源语言,然后使用遗传算法对其进行重组和变异。至关重要的是,这种演化同时在三个层面上发生。在词层面上,长词被拆分为词根和附加部分,然后根据特定语言规则重新排列以形成新且看起来自然的词。在句子层面上,片段在提示间交换以重塑意义,同时保持语法。在段落层面上,描述说话者身份、行为和情境的块被互换,创造出丰富的情节化设定,从而能够掩藏恶意意图。
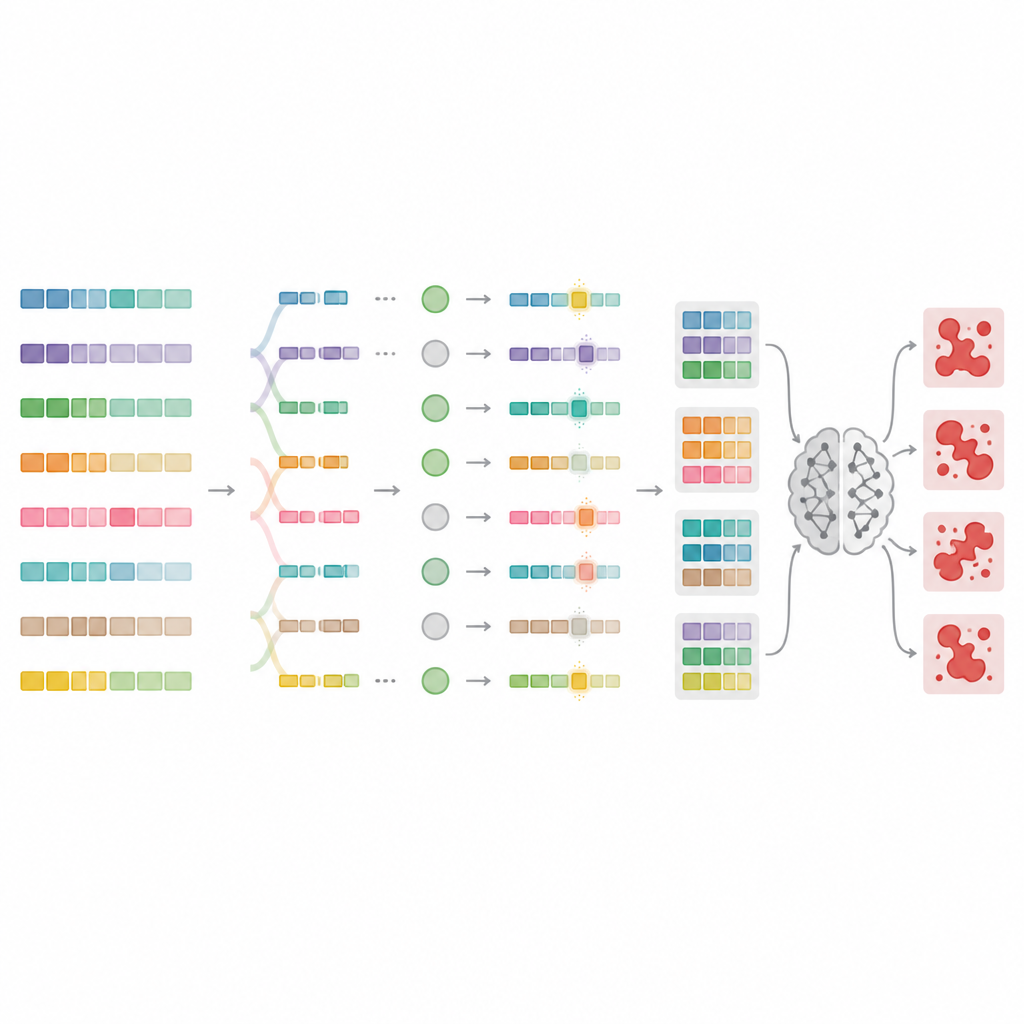
评估哪些提示真正突破了防线
并非每个重写后的提示都能欺骗模型,因此 MnMR-GenA 需要衡量成功的方式。系统查询目标模型并同时评估两项内容:模型的回答在多大程度上符合有害意图,以及回复中是否出现任何拒绝的迹象,例如道歉性短语。这两个信号被融合为一个分数,指导演化朝向更有效的提示。一个智能的选择机制保留表现最好的候选者,同时仍给表现较弱、但可能包含有用特性的个体留出空间。变异强度本身也随时间通过一种类似强化学习的规则进行调整,使得早期世代能够探索大量激进变体,而后期世代则在最有前景的提示周围进行更谨慎的微调。
实验揭示了模型的哪些弱点
团队在两个开源模型和一个广泛使用的商业模型上测试了 MnMR-GenA,使用了两个公开危险问题集合。在三种低资源语言中,他们的方法达到了约 80% 的越狱成功率,明显高于若干也依赖进化的强基线方法。该方法在查询模型次数上并未大幅增加,表明其搜索既高效又强大。即便在模型被包裹以增加检测不自然文本或向输入加入随机噪声等额外防护时,MnMR-GenA 仍保持相对较高的成功率,因为其提示更像普通语言,不依赖脆弱的表面技巧。
这对构建更安全 AI 的意义
对非专业读者来说,结论很清晰:当前 AI 系统在服务不足的语言中比在英语中更易被误导,而巧妙的提示生成器可以系统性地发现这些薄弱点。MnMR-GenA 被呈现为一种用于安全测试的工具,而非用于现实世界滥用,但它的成功凸显了迫切需要在各语言间加强防护、特别关注复杂的词构造体系,并开发能跟上演化攻击策略的更好检测工具。
引用: Li, Y., Wang, G. & Wang, H. MnMR-GenA: a morphological recombination genetic algorithm for jailbreak attacks in low-resource language. Sci Rep 16, 16113 (2026). https://doi.org/10.1038/s41598-026-47434-5
关键词: 大型语言模型, 越狱攻击, 低资源语言, 人工智能安全, 遗传算法