Clear Sky Science · pt
MnMR-GenA: um algoritmo genético de recombinação morfológica para ataques de jailbreak em idiomas com poucos recursos
Por que é importante segurança em IA para todas as línguas
À medida que chatbots poderosos se espalham pelo mundo, as pessoas os utilizam em centenas de idiomas, não apenas em inglês ou chinês. Ainda assim, muitas verificações de segurança que impedem respostas prejudiciais são ajustadas com dados de línguas bem estudadas. Este artigo faz uma pergunta inquietante: existem pontos fracos ocultos em línguas menos usadas onde prompts nocivos podem contornar defesas com mais facilidade e, em caso afirmativo, como os pesquisadores podem expor essas lacunas para tornar os sistemas mais seguros?
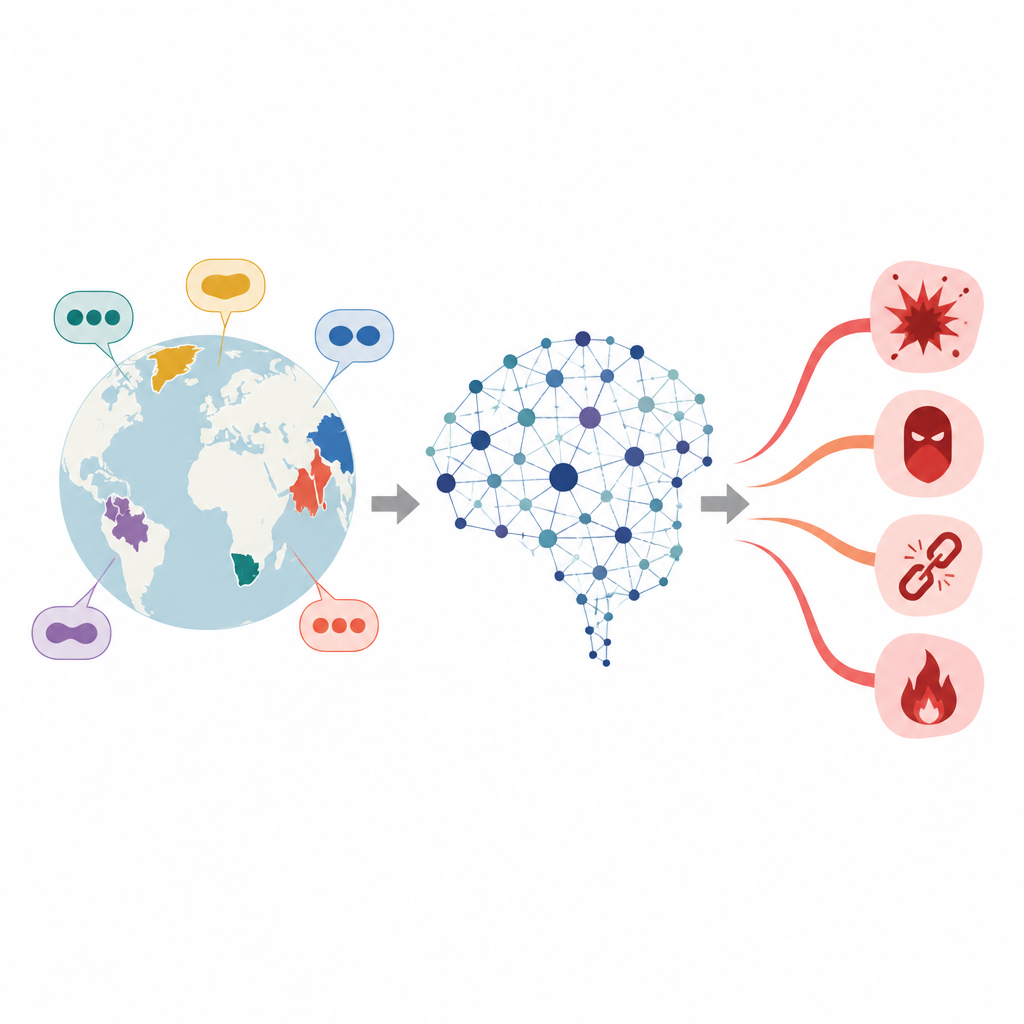
Fissuras ocultas na segurança multilíngue de IA
Grandes modelos de linguagem aprendem a partir de vastas coleções de texto e são posteriormente ajustados para evitar dar conselhos sobre crime, ódio ou outros temas perigosos. Esse ajuste, porém, costuma ser mais forte em idiomas com muitos recursos e dados de treinamento abundantes. Para idiomas de poucos recursos, a camada de segurança é muito mais tênue. Trabalhos anteriores mostraram que simplesmente traduzir um prompt nocivo do inglês para um desses idiomas pode aumentar a probabilidade de o modelo fornecer uma resposta insegura. Os autores focam em um grupo especial de línguas, chamadas aglutinantes, em que palavras longas são formadas ao concatenar muitas peças menores, o que amplia enormemente as formas como um pedido nocivo pode ser enunciado.
Da tradução simples a prompts de ataque evolutivos
A maior parte dos ataques existentes se divide em três grupos. Alguns dependem de templates escritos à mão que ordenam ao modelo “fingir” ou “ignorar regras”, os quais exigem tempo para criar e são fáceis de corrigir pelas empresas. Outros usam acesso direto a componentes internos do modelo para ajustar entradas, mas frequentemente geram sequências sem sentido que detectores conseguem sinalizar com facilidade. Um terceiro grupo trata o modelo como uma caixa preta e usa busca ou evolução para reescrever prompts, porém normalmente apenas em um nível — por exemplo, frases inteiras — o que limita a criatividade e muitas vezes quebra o sentido. Ataques baseados em tradução funcionam melhor em idiomas de poucos recursos, mas ainda preservam a estrutura original do prompt em inglês e não exploram completamente a flexibilidade de formação de palavras das línguas aglutinantes.
Um motor evolutivo para prompts furtivos
Para ir além desses limites, os autores projetam o MnMR-GenA, uma estrutura que trata cada prompt nocivo como uma população viva de variantes que evolui ao longo do tempo. Ela parte de prompts de jailbreak conhecidos traduzidos para idiomas de poucos recursos, como mongol, turco e guarani, e então usa um algoritmo genético para recombiná‑los e mutá‑los. Crucialmente, essa evolução ocorre em três níveis ao mesmo tempo. No nível da palavra, palavras longas são divididas em raízes e afixos, que são rearranjados segundo regras específicas da língua para formar novas palavras com aparência natural. No nível da frase, segmentos são trocados entre prompts para reordenar o significado mantendo a gramática. No nível do parágrafo, blocos que descrevem quem fala, o que está fazendo e em que situação são intercambiados, criando cenários ricos em estilo narrativo que podem ocultar intenção maliciosa.
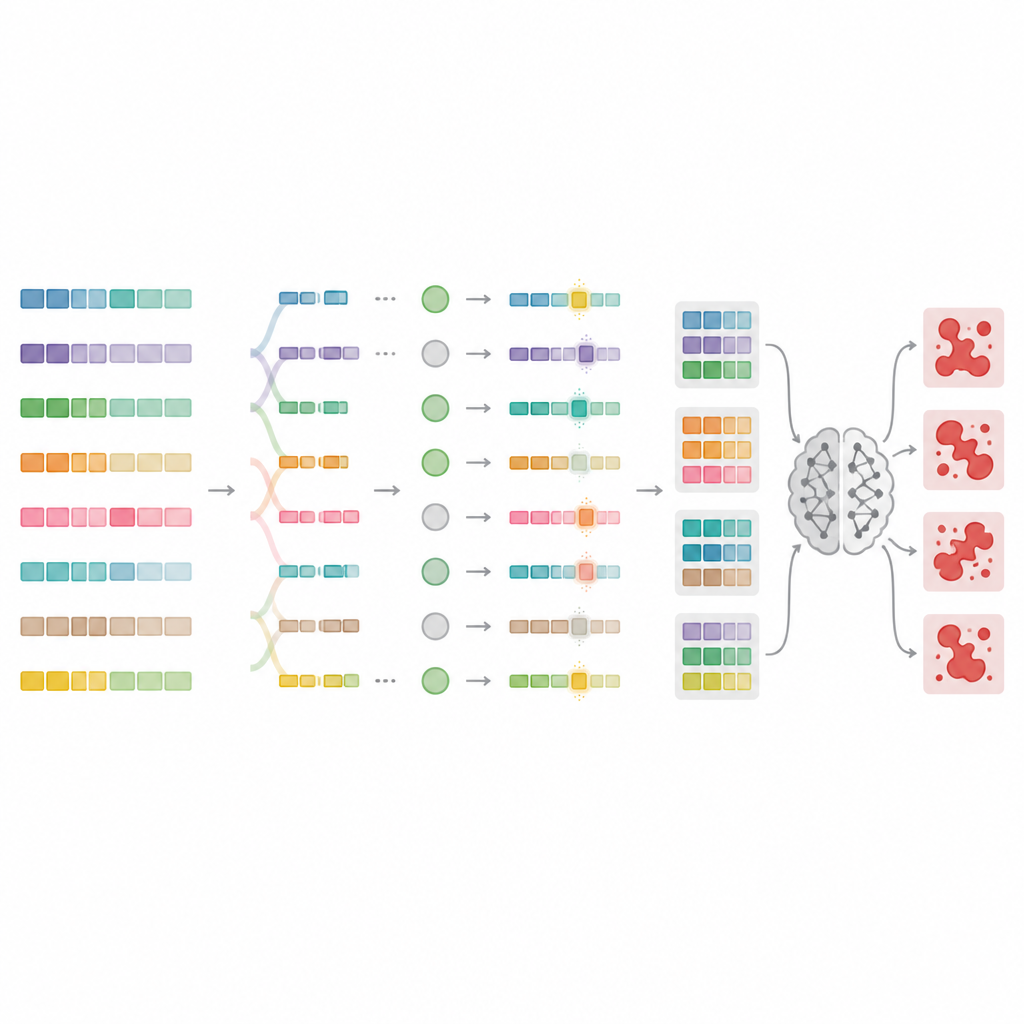
Avaliando quais prompts realmente violam as regras
Nem todo prompt reescrito engana de fato o modelo, então o MnMR-GenA precisa de um modo de medir o sucesso. O sistema consulta um modelo alvo e julga duas coisas ao mesmo tempo: o quão fiel a resposta do modelo segue a intenção nociva e se há qualquer sinal de recusa na resposta, como frases de desculpas. Esses dois sinais são combinados em uma única pontuação que guia a evolução rumo a prompts mais efetivos. Um esquema inteligente de seleção mantém os melhores candidatos enquanto ainda preserva espaço para versões mais fracas que podem conter peculiaridades úteis. A própria intensidade das mutações é ajustada ao longo do tempo por uma regra no estilo de reforço, de forma que as primeiras gerações exploram muitas variantes radicais, enquanto as gerações posteriores fazem alterações mais cuidadosas em torno dos prompts mais promissores.
O que os experimentos revelam sobre fraquezas dos modelos
A equipe testa o MnMR-GenA em dois modelos de código aberto e em um modelo comercial amplamente usado, empregando duas coleções públicas de perguntas perigosas. Em três idiomas de poucos recursos, seu método alcança taxas de sucesso de jailbreak em torno de 80%, claramente superiores a várias linhas de base fortes que também utilizam evolução. Isso ocorre sem um grande aumento no número de consultas ao modelo, mostrando que a busca é eficiente além de potente. Mesmo quando os modelos são protegidos por defesas extras que procuram texto não natural ou adicionam ruído aleatório às entradas, o MnMR-GenA mantém uma taxa de sucesso relativamente alta, porque seus prompts se assemelham a linguagem comum e não dependem de artifícios superficiais frágeis.
O que isso significa para construir IA mais segura
Para um público geral, a mensagem é clara: sistemas de IA atuais podem ser muito mais fáceis de enganar em línguas menos atendidas do que em inglês, e geradores de prompts inteligentes podem descobrir sistematicamente esses pontos fracos. O MnMR-GenA é apresentado como uma ferramenta para testes de segurança, não para uso indevido no mundo real, mas seu êxito ressalta a necessidade urgente de fortalecer defesas entre idiomas, prestar atenção especial a sistemas complexos de formação de palavras e desenvolver melhores ferramentas de detecção que acompanhem estratégias de ataque em evolução.
Citação: Li, Y., Wang, G. & Wang, H. MnMR-GenA: a morphological recombination genetic algorithm for jailbreak attacks in low-resource language. Sci Rep 16, 16113 (2026). https://doi.org/10.1038/s41598-026-47434-5
Palavras-chave: grandes modelos de linguagem, ataques de jailbreak, idiomas de poucos recursos, segurança em IA, algoritmos genéticos