Clear Sky Science · de
MnMR-GenA: ein morphologisches Rekombinations‑Genetikalgorithmus für Jailbreak‑Angriffe in ressourcenarmen Sprachen
Warum sicherere KI in allen Sprachen wichtig ist
Mit der weltweiten Verbreitung leistungsfähiger Chatbots nutzen Menschen sie in Hunderten von Sprachen, nicht nur in Englisch oder Chinesisch. Viele Sicherheitsprüfungen, die schädliche Antworten verhindern, sind jedoch auf Daten aus gut erforschten Sprachen abgestimmt. Dieses Paper stellt eine beunruhigende Frage: Gibt es in weniger verbreiteten Sprachen verborgene Schwachstellen, durch die schädliche Prompts leichter an Abwehrmechanismen vorbeigeschleust werden können, und wenn ja, wie können Forschende diese Blindstellen offenlegen, um Systeme sicherer zu machen?
Verborgene Risse in der multilingualen KI‑Sicherheit
Große Sprachmodelle lernen aus gewaltigen Textsammlungen und werden anschließend so angepasst, dass sie keine Anleitungen zu Verbrechen, Hass oder anderen gefährlichen Themen geben. Diese Feinabstimmung ist jedoch meist in ressourcenreichen Sprachen mit reichhaltigen Trainingsdaten am stärksten. Für ressourcenarme Sprachen ist die Sicherheitsschicht deutlich dünner. Frühere Arbeiten zeigten, dass bereits die bloße Übersetzung eines schädlichen englischen Prompts in eine solche Sprache die Wahrscheinlichkeit erhöht, dass das Modell eine unsichere Antwort liefert. Die Autorinnen und Autoren konzentrieren sich auf eine spezielle Gruppe von Sprachen, die agglutinierende Sprachen genannt werden, in denen lange Wörter durch Aneinanderreihung vieler kürzerer Morpheme gebildet werden — das vergrößert die Vielfalt, in der eine schädliche Anfrage formuliert werden kann.
Von einfacher Übersetzung zu sich entwickelnden Angriffs‑Prompts
Die meisten bestehenden Angriffe fallen in drei Gruppen. Einige basieren auf handgeschriebenen Vorlagen, die das Modell auffordern zu „so tun als ob“ oder „Regeln zu ignorieren“ — sie sind zeitaufwändig zu erstellen und leicht von Anbietern zu patchen. Andere nutzen direkten Zugang zu Modellinterna, um Eingaben zu manipulieren, erzeugen dabei aber oft unsinnige Zeichenfolgen, die Detektoren leicht erkennen. Eine dritte Gruppe behandelt das Modell als Blackbox und verwendet Suche oder Evolution, um Prompts umzuschreiben, meist jedoch nur auf einer Ebene, etwa ganze Sätze, was die Kreativität einschränkt und häufig den Sinn zerstört. Übersetzungsbasierte Angriffe funktionieren in ressourcenarmen Sprachen besser, bleiben aber oft an der ursprünglichen Struktur des englischen Prompts hängen und nutzen nicht vollständig die flexible Wortbildung agglutinierender Sprachen.
Eine evolutionäre Engine für heimtückische Prompts
Um diese Grenzen zu überwinden, entwerfen die Autorinnen und Autoren MnMR‑GenA, ein Framework, das jeden schädlichen Prompt als lebende Population von Varianten behandelt, die sich über die Zeit entwickelt. Es beginnt mit bekannten Jailbreak‑Prompts, die in ressourcenarme Sprachen wie Mongolisch, Türkisch und Guaraní übersetzt wurden, und verwendet dann einen genetischen Algorithmus, um sie zu rekombinieren und zu mutieren. Entscheidend ist, dass diese Evolution gleichzeitig auf drei Ebenen stattfindet. Auf Wortebene werden lange Wörter in Wurzeln und anhängende Stücke zerlegt, die gemäß sprachspezifischer Regeln neu angeordnet werden, um neue, aber natürlich wirkende Wörter zu bilden. Auf Satzebene werden Segmente zwischen Prompts ausgetauscht, um die Bedeutung umzustrukturieren, ohne die Grammatik zu verletzen. Auf Absatzebene werden Blöcke, die beschreiben, wer spricht, was getan wird und in welcher Situation, ersetzt — so entstehen reichhaltige, erzähllike Setups, die böswillige Absichten verbergen können.
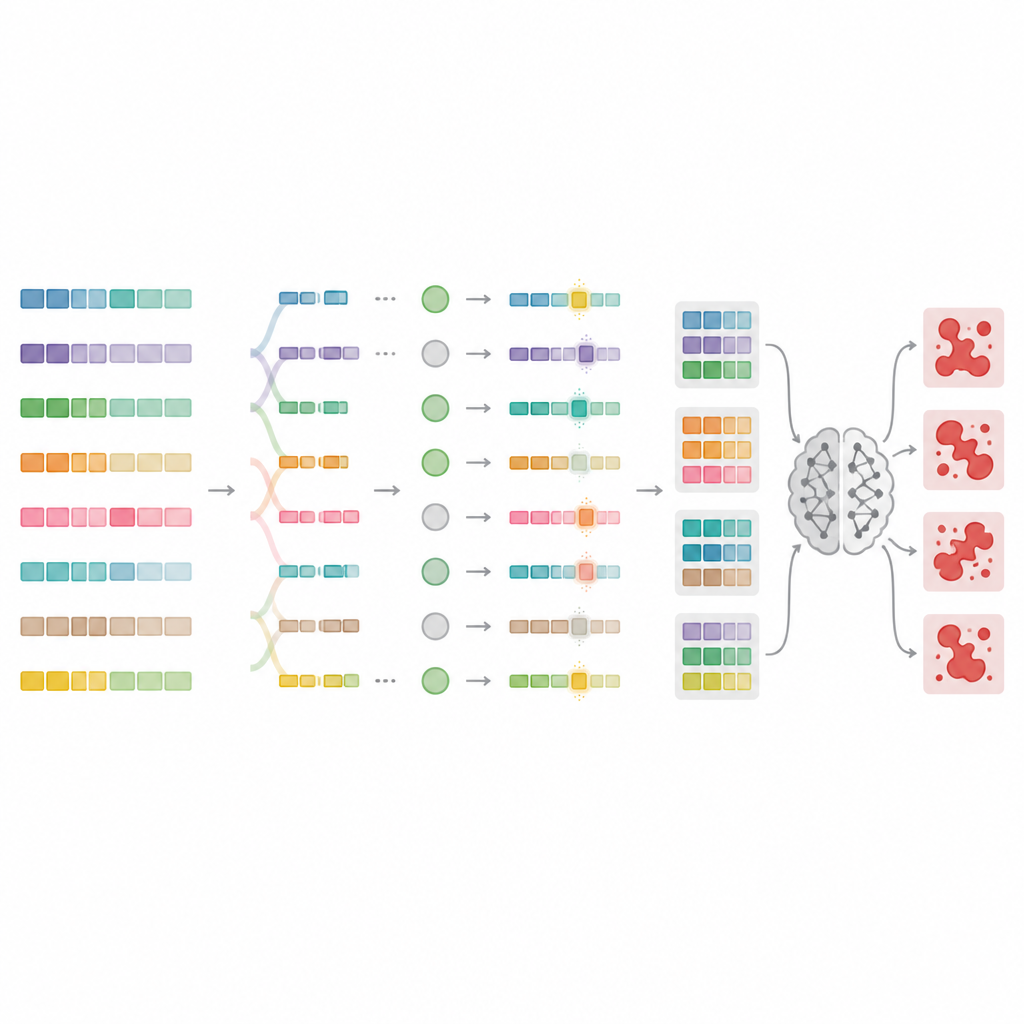
Bewertung: Welche Prompts durchbrechen wirklich die Regeln
Nicht jeder umgeschriebene Prompt täuscht das Modell tatsächlich, daher benötigt MnMR‑GenA eine Erfolgsmessung. Das System befragt ein Zielmodell und beurteilt zwei Dinge gleichzeitig: wie eng die Antwort des Modells der schädlichen Absicht folgt und ob im Reply Anzeichen einer Weigerung auftauchen, etwa entschuldigende Formulierungen. Diese beiden Signale werden zu einer einzigen Punktzahl verschmolzen, die die Evolution in Richtung effektiverer Prompts leitet. Ein intelligentes Selektionsschema behält die besten Kandidaten bei, lässt aber Raum für schwächere, die nützliche Eigenheiten enthalten könnten. Die Mutationsstärke selbst wird über die Zeit mit einer verstärkungsähnlichen Regel abgestimmt, sodass frühe Generationen viele wilde Varianten erkunden, während spätere Generationen feinere Anpassungen um vielversprechende Prompts vornehmen.
Was die Experimente über Modell‑Schwachstellen offenbaren
Das Team testet MnMR‑GenA an zwei Open‑Source‑Modellen und einem weit verbreiteten kommerziellen Modell und verwendet zwei öffentliche Sammlungen gefährlicher Fragen. In drei ressourcenarmen Sprachen erreicht ihre Methode Jailbreak‑Erfolgsraten von etwa 80 Prozent, deutlich höher als mehrere starke Baselines, die ebenfalls auf Evolution setzen. Dies gelingt ohne großen Anstieg der Anzahl der Anfragen an das Modell, was zeigt, dass die Suche sowohl effizient als auch wirksam ist. Selbst wenn die Modelle mit zusätzlichen Abwehrmechanismen versehen sind, die nach unnatürlichem Text suchen oder Eingaben zufällig verrauschen, behält MnMR‑GenA eine relativ hohe Erfolgsrate, weil seine Prompts gewöhnlicher Sprache ähneln und nicht auf brüchige Oberflächentricks angewiesen sind.
Was das für den Aufbau sichererer KI bedeutet
Für Laien ist die Botschaft klar: Aktuelle KI‑Systeme lassen sich in unterversorgten Sprachen deutlich leichter in die Irre führen als auf Englisch, und clevere Prompt‑Generatoren können systematisch diese Schwachstellen aufdecken. MnMR‑GenA wird als Werkzeug für Sicherheitstests vorgestellt und nicht für den Missbrauch in der realen Welt, doch sein Erfolg unterstreicht die dringende Notwendigkeit, Abwehrmaßnahmen über Sprachen hinweg zu stärken, besonderen Wert auf komplexe Wortbildungssysteme zu legen und bessere Erkennungswerkzeuge zu entwickeln, die mit sich entwickelnden Angriffsstrategien Schritt halten können.
Zitation: Li, Y., Wang, G. & Wang, H. MnMR-GenA: a morphological recombination genetic algorithm for jailbreak attacks in low-resource language. Sci Rep 16, 16113 (2026). https://doi.org/10.1038/s41598-026-47434-5
Schlüsselwörter: große Sprachmodelle, Jailbreak‑Angriffe, ressourcenarme Sprachen, KI‑Sicherheit, Genetische Algorithmen