Clear Sky Science · nl
MnMR-GenA: een morfologisch recombinatie-genetisch algoritme voor jailbreak-aanvallen in weinig-ondersteunde talen
Waarom veiliger AI in alle talen ertoe doet
Nu krachtige chatbots zich over de hele wereld verspreiden, gebruiken mensen ze in honderden talen, niet alleen in het Engels of Chinees. Veel veiligheidscontroles die schadelijke antwoorden stoppen, zijn echter afgestemd op data uit goed bestudeerde talen. Dit artikel stelt een alarmerende vraag: bestaan er verborgen zwakke plekken in minder gebruikte talen waar schadelijke prompts gemakkelijker langs de verdediging glippen, en zo ja, hoe kunnen onderzoekers die blinde vlekken blootleggen om systemen veiliger te maken?
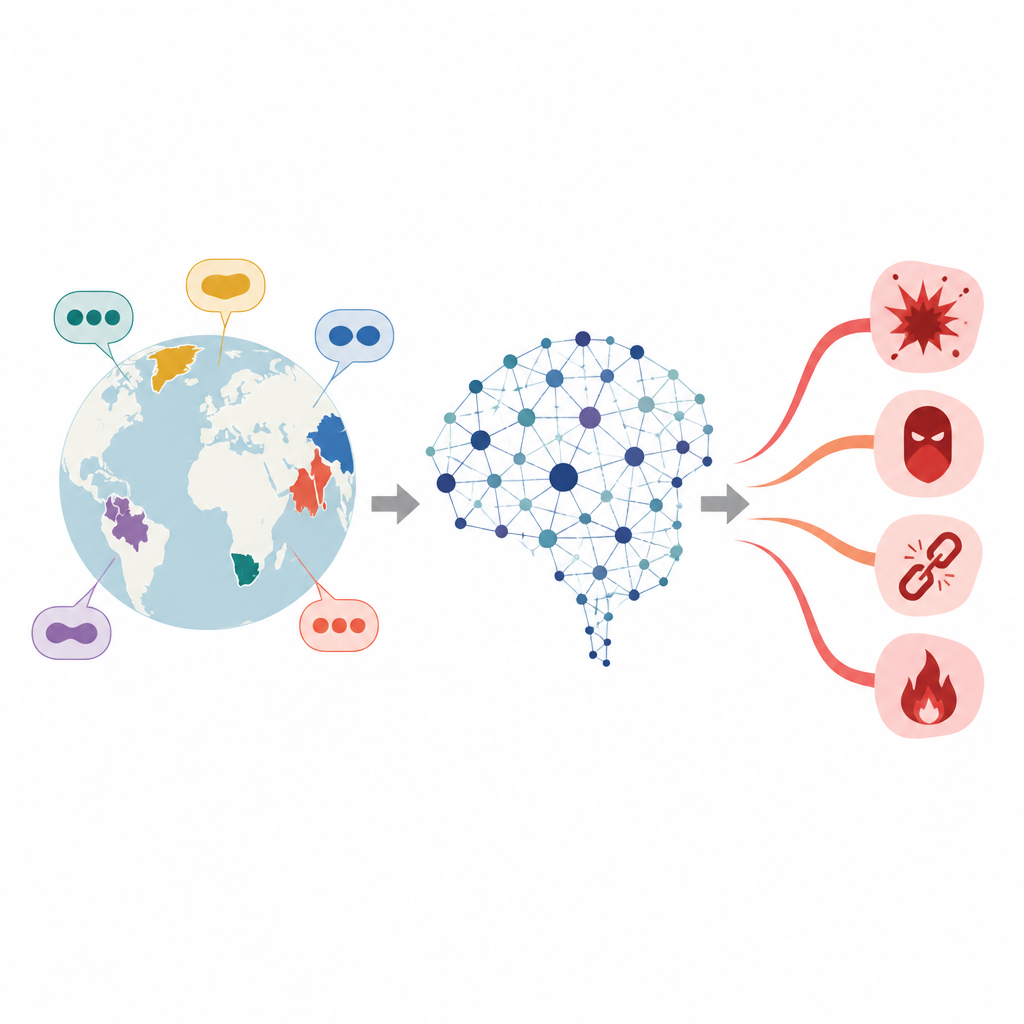
Verborgen scheuren in meertalige AI-veiligheid
Grote taalmodellen leren van enorme tekstenverzamelingen en worden daarna bijgestuurd zodat ze geen advies geven over misdrijven, haat of andere gevaarlijke onderwerpen. Die bijsturing is doorgaans echter het sterkst in hoog resource-talen met rijke trainingsdata. Voor weinig-ondersteunde talen is de veiligheidslaag veel dunner. Eerdere studies toonden aan dat het simpelweg vertalen van een schadelijke Engelse prompt naar zo’n taal de kans kan vergroten dat het model een onveilig antwoord geeft. De auteurs richten zich op een speciale groep talen, zogenaamde agglutinerende talen, waarin lange woorden worden opgebouwd door veel kortere stukjes aan elkaar te plakken, wat het aantal manieren waarop een schadelijk verzoek geformuleerd kan worden sterk vergroot.
Van eenvoudige vertaling naar evoluerende aanvalsprompts
De meeste bestaande aanvallen vallen in drie groepen. Sommige vertrouwen op handgeschreven sjablonen die het model laten “doen alsof” of “regels negeren”, die tijdrovend zijn om te maken en gemakkelijk door bedrijven te verhelpen. Andere gebruiken directe toegang tot modelinterne componenten om inputs te beïnvloeden, maar die produceren vaak onzinnige tekenreeksen die detectoren eenvoudig kunnen signaleren. Een derde groep behandelt het model als een black box en gebruikt zoek- of evolutiemethoden om prompts te herschrijven, maar meestal slechts op één niveau, bijvoorbeeld volledige zinnen, wat de creativiteit beperkt en vaak de betekenis verbreekt. Op vertaling gebaseerde aanvallen werken beter in weinig-ondersteunde talen, maar blijven toch vastzitten aan de oorspronkelijke structuur van de Engelse prompt en benutten de flexibele woordopbouw van agglutinerende talen niet volledig.
Een evolutionaire motor voor slinkse prompts
Om deze beperkingen te overstijgen, ontwerpen de auteurs MnMR-GenA, een raamwerk dat elke schadelijke prompt behandelt als een levende populatie varianten die in de loop van de tijd evolueert. Het begint met bekende jailbreak-prompts vertaald naar weinig-ondersteunde talen zoals Mongools, Turks en Guaraní, en gebruikt vervolgens een genetisch algoritme om ze te recombineren en te muteren. Cruciaal is dat deze evolutie op drie niveaus tegelijk plaatsvindt. Op woordniveau worden lange woorden opgesplitst in wortels en aangehechte stukjes, die vervolgens volgens taalspecifieke regels worden herschikt om nieuwe maar natuurlijk ogende woorden te vormen. Op zinsniveau worden segmenten tussen prompts verwisseld om de betekenis te herschudden terwijl de grammatica behouden blijft. Op paragraafniveau worden blokken die beschrijven wie spreekt, wat zij doen en in welke situatie dit plaatsvindt uitgewisseld, waardoor rijke verhalende opzetten ontstaan die kwaadwillige intentie kunnen verbergen.
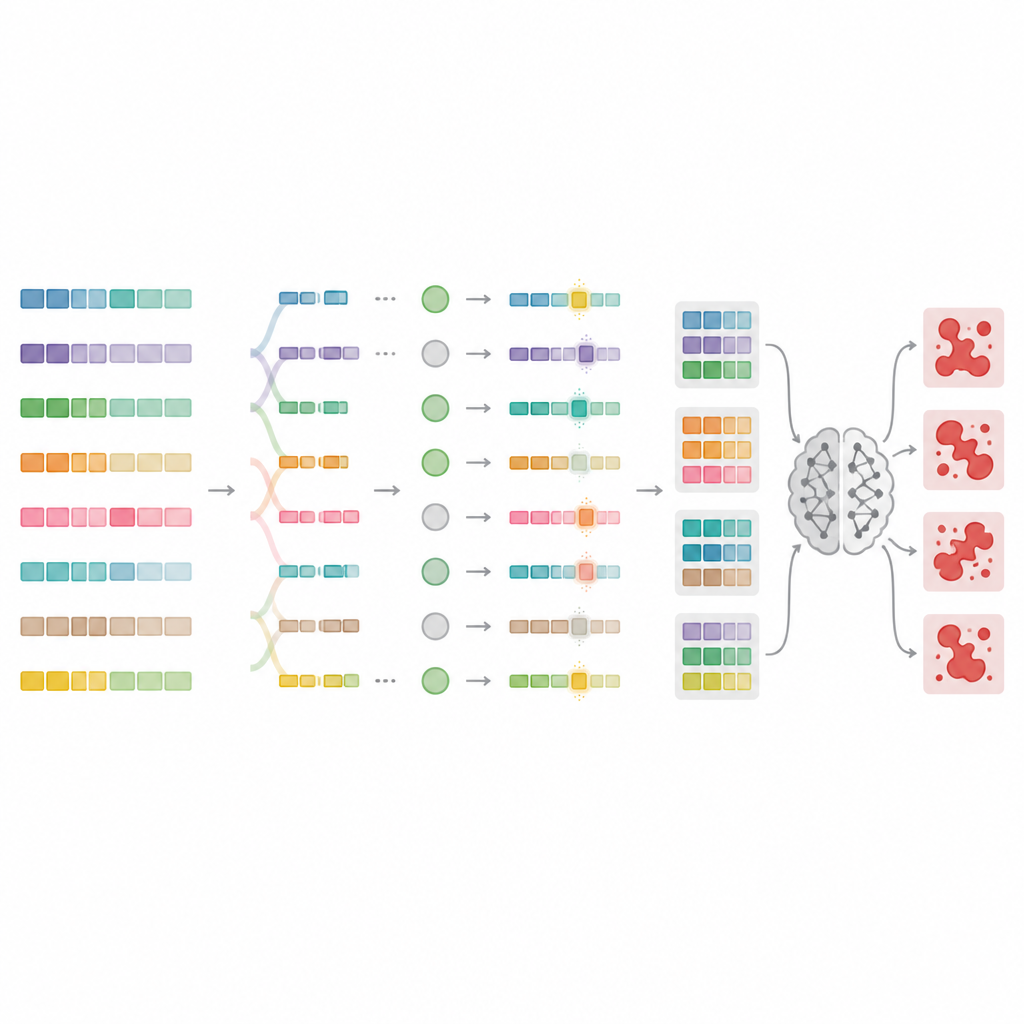
Scoren welke prompts echt de regels breken
Niet elke herschreven prompt misleidt het model, dus MnMR-GenA heeft een manier nodig om succes te meten. Het systeem bevraagt een doelmodel en beoordeelt twee zaken tegelijk: hoe nauw het antwoord van het model de schadelijke intentie volgt, en of er enige aanwijzing van weigering in de reactie verschijnt, zoals verontschuldigende frases. Deze twee signalen worden samengevoegd tot een enkele score die de evolutie richting effectievere prompts stuurt. Een slimme selectiestrategie houdt de beste kandidaten vast terwijl er nog ruimte blijft voor zwakkere exemplaren die nuttige eigenaardigheden kunnen bevatten. De mutatiesterkte zelf wordt in de loop van de tijd bijgesteld met een reinforcement-achtig regelmechanisme, zodat vroege generaties veel wilde varianten verkennen, terwijl latere generaties zorgvuldiger tweaks aanbrengen rond de veelbelovende prompts.
Wat de experimenten onthullen over modelzwakheden
Het team test MnMR-GenA op twee open-source modellen en een veelgebruikt commercieel model, met twee openbare verzamelingen gevaarlijke vragen. Over drie weinig-ondersteunde talen behaalt hun methode jailbreak-succespercentages rond de 80 procent, duidelijk hoger dan verschillende sterke baselines die ook op evolutie vertrouwen. Dit gebeurt zonder een grote toename van het aantal queries naar het model, wat laat zien dat de zoekmethode zowel efficiënt als krachtig is. Zelfs wanneer de modellen extra verdedigingslagen hebben die zoeken naar onnatuurlijke tekst of willekeurige ruis aan inputs toevoegen, behoudt MnMR-GenA een relatief hoog slagingspercentage, omdat de prompts op gewone taal lijken en niet afhankelijk zijn van broze oppervlakte-trucs.
Wat dit betekent voor het bouwen van veiligere AI
Voor een leek is de boodschap duidelijk: huidige AI-systemen zijn in onderbediende talen veel gemakkelijker te misleiden dan in het Engels, en slimme promptgeneratoren kunnen die zwakke plekken systematisch blootleggen. MnMR-GenA wordt gepresenteerd als een hulpmiddel voor veiligheidstesten, niet voor misbruik in de echte wereld, maar het succes benadrukt de dringende behoefte om verdedigingen over talen heen te versterken, speciale aandacht te geven aan complexe woordopbouwsystemen en betere detectietools te ontwikkelen die gelijke tred kunnen houden met evoluerende aanvalstrategieën.
Bronvermelding: Li, Y., Wang, G. & Wang, H. MnMR-GenA: a morphological recombination genetic algorithm for jailbreak attacks in low-resource language. Sci Rep 16, 16113 (2026). https://doi.org/10.1038/s41598-026-47434-5
Trefwoorden: grote taalmodellen, jailbreak-aanvallen, weinig-ondersteunde talen, AI-veiligheid, genetische algoritmen