Clear Sky Science · pl
MnMR-GenA: morfologiczny algorytm genetyczny do ataków jailbreak w językach o niskich zasobach
Dlaczego bezpieczniejsze AI we wszystkich językach ma znaczenie
W miarę jak potężne chatboty rozprzestrzeniają się na całym świecie, ludzie korzystają z nich w setkach języków, nie tylko po angielsku czy chińsku. Jednak wiele zabezpieczeń zapobiegających szkodliwym odpowiedziom jest dostrajanych na danych z języków dobrze zbadanych. W artykule pojawia się niepokojące pytanie: czy istnieją ukryte słabe punkty w rzadziej używanych językach, przez które szkodliwe promptu łatwiej prześlizgują się obok obron, a jeśli tak — jak badacze mogą je ujawnić, by uczynić systemy bezpieczniejszymi?
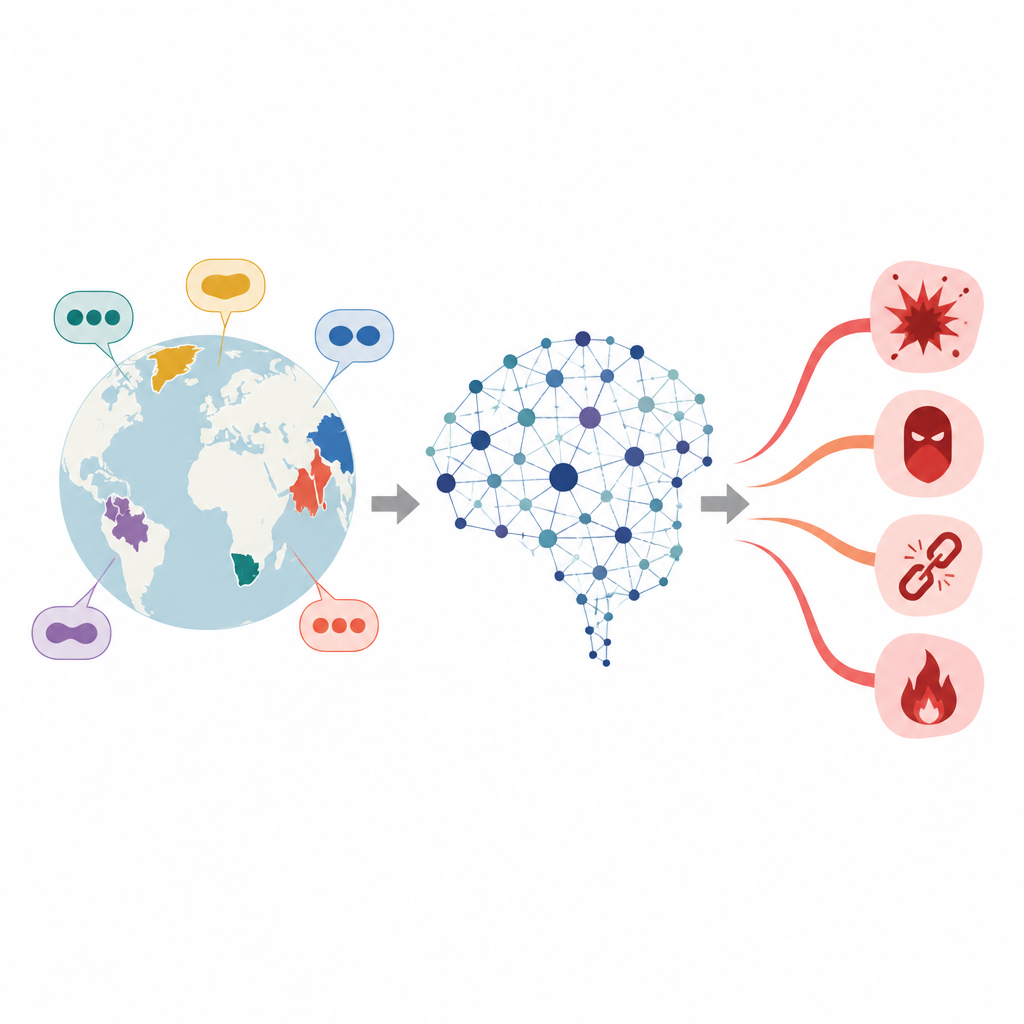
Ukryte pęknięcia w wielojęzycznym bezpieczeństwie AI
Duże modele językowe uczą się z rozległych zbiorów tekstów i potem są dostrajane tak, by unikać udzielania porad dotyczących przestępstw, nienawiści czy innych niebezpiecznych tematów. To dostrajanie jest jednak zazwyczaj najsilniejsze w językach o bogatych zasobach treningowych. Dla języków o niskich zasobach warstwa bezpieczeństwa jest znacznie cieńsza. Poprzednie badania wykazały, że proste przetłumaczenie szkodliwego promptu z angielskiego na taki język może zwiększyć prawdopodobieństwo, że model udzieli niebezpiecznej odpowiedzi. Autorzy koncentrują się na specjalnej grupie języków, zwanych aglutynacyjnymi, w których długie wyrazy budowane są przez łączenie wielu krótszych elementów — co znacznie zwiększa sposoby formułowania szkodliwych żądań.
Od prostego tłumaczenia do ewoluujących promptów atakujących
Większość istniejących ataków mieści się w trzech grupach. Niektóre opierają się na ręcznie pisanych szablonach, które każą modelowi „udawać” lub „ignorować zasady”, co jest pracochłonne w tworzeniu i łatwe do załatania przez firmy. Inne korzystają z bezpośredniego dostępu do wnętrza modelu, by delikatnie modyfikować wejścia, lecz często generują wtedy nonsensowne ciągi, które detektory mogą łatwo wykryć. Trzecia grupa traktuje model jako czarną skrzynkę i używa wyszukiwania lub ewolucji do przepisywania promptów, zwykle jednak na pojedynczym poziomie, np. całych zdań, co ogranicza kreatywność i często łamie sens. Ataki oparte na tłumaczeniu działają lepiej w językach o niskich zasobach, lecz nadal trzymają się struktury oryginalnego angielskiego promptu i nie wykorzystują w pełni elastycznego budowania słów w językach aglutynacyjnych.
Ewolucyjny silnik do podstępnych promptów
Aby wyjść poza te ograniczenia, autorzy zaprojektowali MnMR-GenA — ramy, które traktują każdy szkodliwy prompt jak żyjącą populację wariantów ewoluujących w czasie. Zaczyna się od znanych promptów jailbreak przetłumaczonych na języki o niskich zasobach, takie jak mongolski, turecki czy guarani, a następnie wykorzystuje algorytm genetyczny do ich rekombinacji i mutacji. Kluczowe jest to, że ewolucja zachodzi jednocześnie na trzech poziomach. Na poziomie słowa długie wyrazy są dzielone na rdzenie i przyrostki, które następnie są przestawiane zgodnie ze specyficznymi regułami języka, tworząc nowe, naturalnie wyglądające słowa. Na poziomie zdania segmenty są wymieniane między promptami, aby przetasować znaczenie przy zachowaniu gramatyki. Na poziomie akapitu bloki opisujące, kto mówi, co robi i w jakiej sytuacji, są zamieniane, tworząc bogate, przypominające opowieść ustawienia, które mogą ukrywać złośliwe intencje.
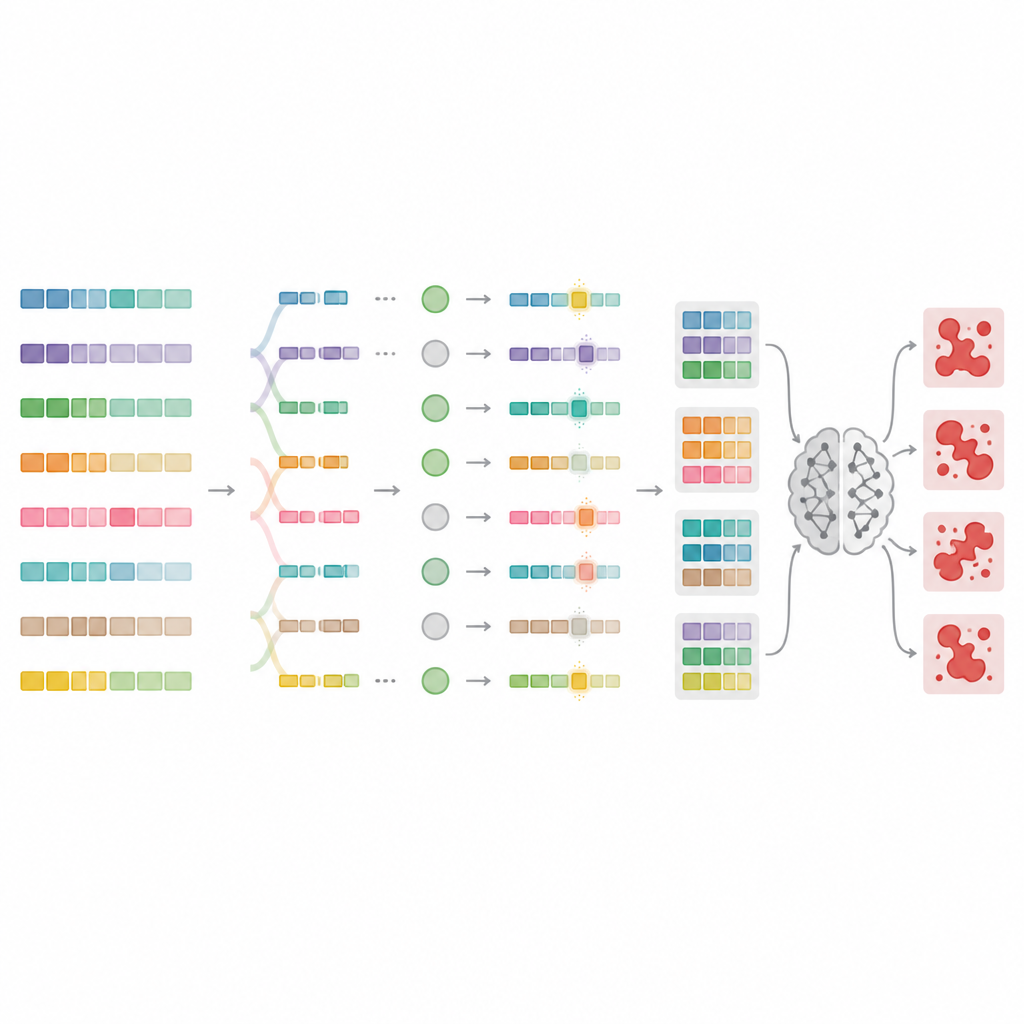
Ocena, które promptu rzeczywiście łamią zasady
Nie każdy przepisany prompt faktycznie oszuka model, więc MnMR-GenA potrzebuje sposobu mierzenia sukcesu. System zadaje pytania docelowemu modelowi i ocenia jednocześnie dwie rzeczy: na ile odpowiedź modelu podąża za szkodliwą intencją oraz czy w odpowiedzi pojawiają się oznaki odmowy, takie jak frazy przeproszeniowe. Te dwa sygnały są łączone w pojedynczy wynik, który kieruje ewolucją w stronę bardziej skutecznych promptów. Inteligentny schemat selekcji zachowuje najlepsze kandydatury, pozostawiając jednocześnie miejsce dla słabszych, które mogą zawierać użyteczne dziwactwa. Siła mutacji jest sama w sobie strojoną w czasie regułą w stylu uczenia ze wzmocnieniem, tak że wczesne generacje eksplorują wiele dzikich wariantów, podczas gdy późniejsze generacje dokonują ostrożniejszych poprawek wokół najbardziej obiecujących promptów.
Co eksperymenty ujawniają o słabościach modeli
Zespół testuje MnMR-GenA na dwóch modelach open source i jednym szeroko używanym modelu komercyjnym, korzystając z dwóch publicznych zbiorów niebezpiecznych pytań. W trzech językach o niskich zasobach ich metoda osiąga wskaźniki sukcesu jailbreak na poziomie około 80 procent, wyraźnie wyższe niż kilka silnych bazowych metod opierających się również na ewolucji. Dokonuje tego bez dużego zwiększenia liczby zapytań do modelu, co pokazuje, że przeszukiwanie jest zarówno efektywne, jak i potężne. Nawet gdy modele są opakowane dodatkowymi obronami wykrywającymi nienaturalny tekst lub dodającymi losowy szum do wejść, MnMR-GenA utrzymuje relatywnie wysoki wskaźnik sukcesu, ponieważ jego promptu przypominają zwykły język i nie polegają na kruchych sztuczkach powierzchniowych.
Co to oznacza dla tworzenia bezpieczniejszego AI
Dla laika przekaz jest jasny: obecne systemy AI mogą być znacznie łatwiejsze do wprowadzenia w błąd w językach niedostatecznie obsługiwanych niż po angielsku, a sprytne generatory promptów mogą systematycznie ujawniać te słabe punkty. MnMR-GenA jest przedstawiane jako narzędzie do testowania bezpieczeństwa, a nie do rzeczywistych nadużyć, jednak jego skuteczność podkreśla pilną potrzebę wzmacniania zabezpieczeń we wszystkich językach, zwracania szczególnej uwagi na złożone systemy budowy słów oraz opracowywania lepszych narzędzi detekcji, które nadążą za ewoluującymi strategiami ataku.
Cytowanie: Li, Y., Wang, G. & Wang, H. MnMR-GenA: a morphological recombination genetic algorithm for jailbreak attacks in low-resource language. Sci Rep 16, 16113 (2026). https://doi.org/10.1038/s41598-026-47434-5
Słowa kluczowe: duże modele językowe, ataki jailbreak, języki o niskich zasobach, bezpieczeństwo AI, algorytmy genetyczne