Clear Sky Science · fr
MnMR-GenA : un algorithme génétique de recombinaison morphologique pour des attaques de jailbreak en langue peu dotée
Pourquoi une IA plus sûre dans toutes les langues compte
À mesure que des chatbots puissants se répandent dans le monde, on les utilise dans des centaines de langues, pas seulement en anglais ou en chinois. Pourtant, de nombreux contrôles de sécurité qui empêchent des réponses nuisibles sont réglés sur des données provenant de langues bien étudiées. Cet article pose une question inquiétante : existe-t-il des points faibles cachés dans les langues moins utilisées où des invites dangereuses peuvent plus facilement contourner les défenses, et, si oui, comment les chercheurs peuvent-ils les mettre au jour pour rendre les systèmes plus sûrs ?
Fissures cachées dans la sécurité multilingue de l’IA
Les grands modèles de langue apprennent à partir de vastes collections de textes et sont ensuite ajustés pour éviter de donner des conseils sur le crime, la haine ou d’autres sujets dangereux. Cet ajustement, toutefois, est généralement le plus poussé dans les langues riches en ressources et en données d’entraînement. Pour les langues peu dotées, la couche de sécurité est beaucoup plus mince. Des travaux antérieurs ont montré que la simple traduction d’une invite nuisible depuis l’anglais vers une de ces langues peut augmenter la probabilité que le modèle fournisse une réponse dangereuse. Les auteurs se concentrent sur un groupe particulier de langues, dites agglutinantes, où de longs mots se forment en enchaînant de nombreux éléments plus courts, ce qui multiplie considérablement les manières de formuler une demande nuisible.
De la traduction simple aux invites d’attaque évolutives
La plupart des attaques existantes se répartissent en trois catégories. Certaines reposent sur des modèles écrits à la main qui demandent au modèle de « faire semblant » ou « d’ignorer les règles », lesquels sont longs à concevoir et faciles à patcher pour les entreprises. D’autres utilisent un accès direct aux internals du modèle pour influer sur les entrées, mais produisent souvent des suites de caractères incohérentes que les détecteurs repèrent aisément. Une troisième catégorie considère le modèle comme une boîte noire et utilise la recherche ou l’évolution pour réécrire les invites, mais généralement à un seul niveau, comme des phrases entières, ce qui limite la créativité et casse souvent le sens. Les attaques basées sur la traduction fonctionnent mieux dans les langues peu dotées, mais elles conservent la structure originale de l’invite anglaise et n’exploitent pas pleinement la flexibilité de formation des mots des langues agglutinantes.
Un moteur évolutif pour des invites furtives
Pour dépasser ces limites, les auteurs conçoivent MnMR-GenA, un cadre qui traite chaque invite nuisible comme une population vivante de variantes qui évolue au fil du temps. Il part d’invites de jailbreak connues traduites en langues peu dotées comme le mongol, le turc et le guarani, puis utilise un algorithme génétique pour les recombiner et les muter. Crucialement, cette évolution se déroule sur trois niveaux à la fois. Au niveau du mot, les mots longs sont segmentés en racines et affixes, qui sont ensuite réarrangés selon des règles propres à la langue pour former de nouveaux mots d’apparence naturelle. Au niveau de la phrase, des segments sont échangés entre invites pour remélanger le sens tout en préservant la grammaire. Au niveau du paragraphe, des blocs décrivant qui parle, ce qu’il fait et dans quelle situation sont interchangés, créant des scénarios narratifs riches qui peuvent dissimuler une intention malveillante.
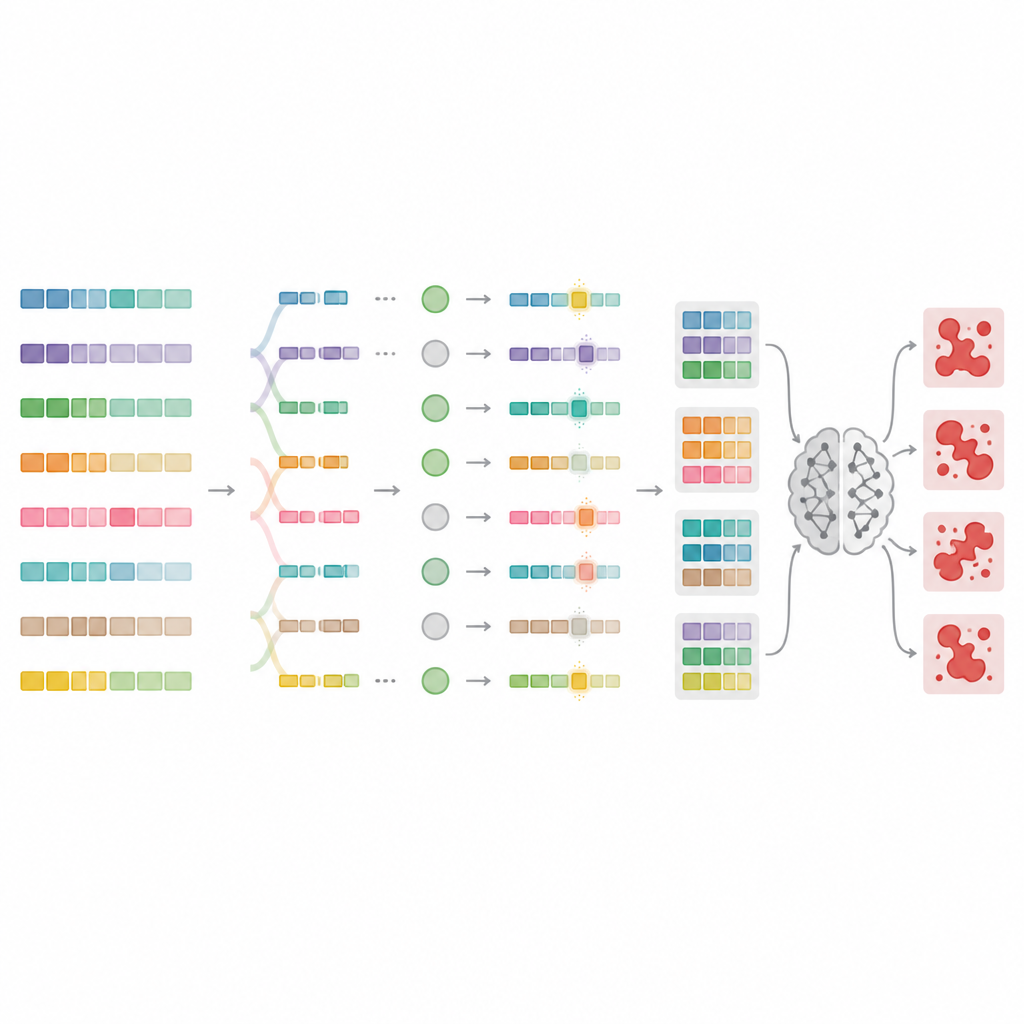
Évaluer quelles invites violent vraiment les règles
Toute invite réécrite ne trompe pas nécessairement le modèle, donc MnMR-GenA a besoin d’un moyen de mesurer le succès. Le système interroge un modèle cible et juge deux choses à la fois : dans quelle mesure la réponse du modèle suit l’intention nuisible, et si une quelconque marque de refus apparaît dans la réponse, comme des phrases d’excuse. Ces deux signaux sont combinés en un score unique qui guide l’évolution vers des invites plus efficaces. Un mécanisme de sélection intelligent conserve les meilleurs candidats tout en laissant de la place à des plus faibles qui pourraient contenir des bizarreries utiles. La force de mutation elle-même est ajustée au fil du temps via une règle de type renforcement, de sorte que les premières générations explorent de nombreuses variantes audacieuses, tandis que les générations ultérieures affinent davantage autour des invites les plus prometteuses.
Ce que les expériences révèlent sur les faiblesses des modèles
L’équipe teste MnMR-GenA sur deux modèles open source et un modèle commercial largement utilisé, en employant deux collections publiques de questions dangereuses. Sur trois langues peu dotées, leur méthode atteint des taux de réussite de jailbreak d’environ 80 %, nettement supérieurs à ceux de plusieurs références solides qui s’appuient elles aussi sur l’évolution. Elle y parvient sans augmenter fortement le nombre de requêtes au modèle, montrant que la recherche est à la fois efficace et puissante. Même lorsque les modèles sont entourés de défenses supplémentaires qui recherchent du texte non naturel ou ajoutent du bruit aléatoire aux entrées, MnMR-GenA maintient un taux de réussite relativement élevé, car ses invites ressemblent à du langage ordinaire et ne dépendent pas de tours de surface fragiles.
Ce que cela implique pour construire une IA plus sûre
Pour le grand public, le message est clair : les systèmes d’IA actuels sont souvent beaucoup plus faciles à tromper dans les langues sous-servies que dans l’anglais, et des générateurs d’invites ingénieux peuvent systématiquement mettre au jour ces points faibles. MnMR-GenA est présenté comme un outil de test de sécurité plutôt que pour un mauvais usage réel, mais son succès souligne l’urgence de renforcer les défenses dans toutes les langues, d’accorder une attention particulière aux systèmes complexes de formation des mots, et de développer de meilleurs outils de détection capables de suivre l’évolution des stratégies d’attaque.
Citation: Li, Y., Wang, G. & Wang, H. MnMR-GenA: a morphological recombination genetic algorithm for jailbreak attacks in low-resource language. Sci Rep 16, 16113 (2026). https://doi.org/10.1038/s41598-026-47434-5
Mots-clés: grands modèles de langue, attaques de jailbreak, langues peu dotées, sécurité de l’IA, algorithmes génétiques