Clear Sky Science · en
MnMR-GenA: a morphological recombination genetic algorithm for jailbreak attacks in low-resource language
Why safer AI in all languages matters
As powerful chatbots spread around the world, people are using them in hundreds of languages, not just English or Chinese. Yet many safety checks that stop harmful answers are tuned on data from well studied languages. This paper asks a worrying question: are there hidden weak spots in lesser used languages where harmful prompts can more easily slip past defenses, and if so, how can researchers expose these blind spots to make systems safer?
Hidden cracks in multilingual AI safety
Large language models learn from vast collections of text and are later adjusted so they avoid giving advice on crime, hate, or other dangerous topics. That tuning, however, is usually strongest in high resource languages with rich training data. For low resource languages, the safety layer is much thinner. Past work showed that simply translating a harmful English prompt into such a language can raise the chance that the model gives an unsafe answer. The authors focus on a special group of languages, called agglutinative languages, where long words are built by stringing many shorter pieces together, which hugely increases the ways a harmful request can be phrased.
From simple translation to evolving attack prompts
Most existing attacks fall into three groups. Some rely on hand written templates that tell the model to “pretend” or “ignore rules,” which are time consuming to create and easy for companies to patch. Others use direct access to model internals to nudge inputs, but these often produce nonsense strings that detectors can easily flag. A third group treats the model as a black box and uses search or evolution to rewrite prompts, yet usually only at a single level, such as whole sentences, which limits creativity and often breaks meaning. Translation based attacks work better in low resource languages, but still cling to the original structure of the English prompt and do not fully exploit the flexible word building of agglutinative languages.
An evolutionary engine for sneaky prompts
To go beyond these limits, the authors design MnMR-GenA, a framework that treats each harmful prompt as a living population of variants that evolves over time. It starts from known jailbreak prompts translated into low resource languages like Mongolian, Turkish, and Guarani, then uses a genetic algorithm to recombine and mutate them. Crucially, this evolution happens at three levels at once. At the word level, long words are split into roots and attached pieces, which are then rearranged according to language specific rules to form new but natural looking words. At the sentence level, segments are swapped across prompts to reshuffle meaning while keeping grammar. At the paragraph level, blocks that describe who is speaking, what they are doing, and in which situation are exchanged, creating rich story like setups that can hide malicious intent.
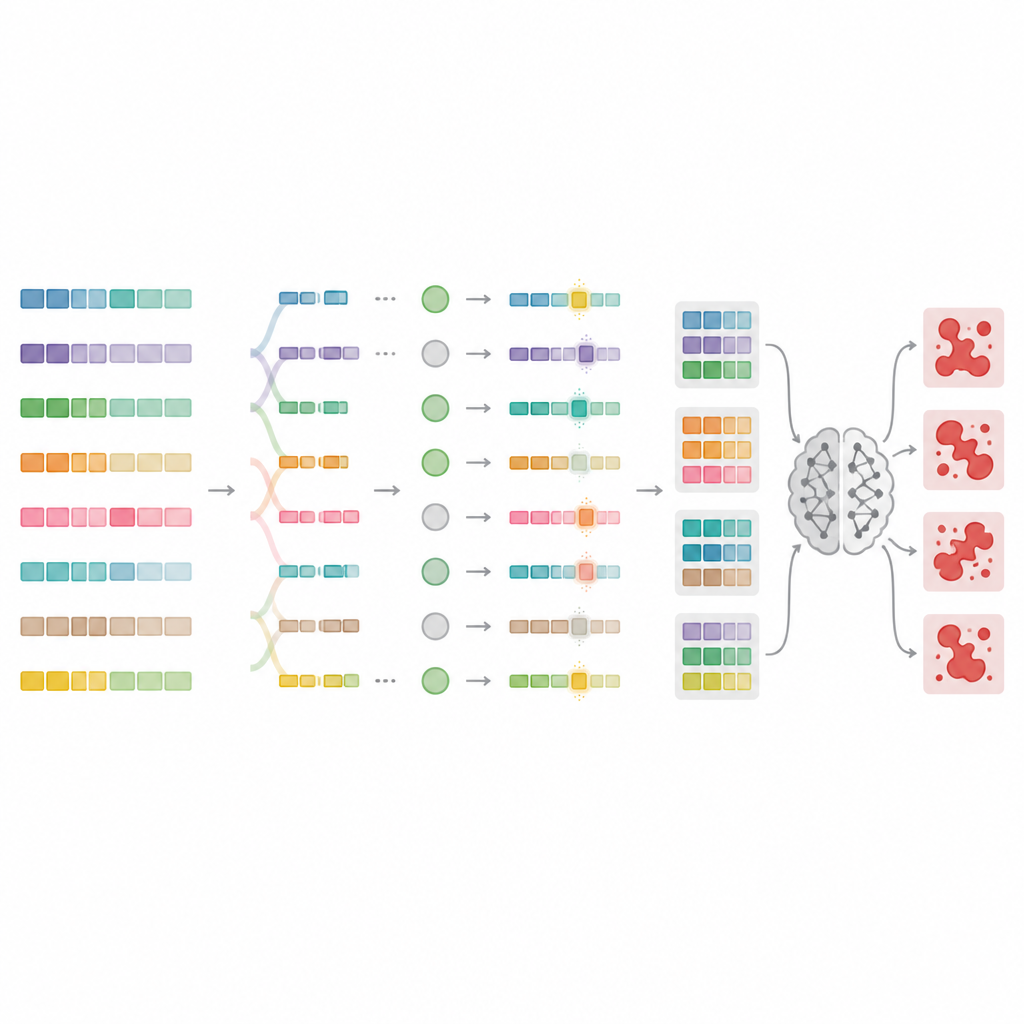
Scoring which prompts really break the rules
Not every rewritten prompt actually tricks the model, so MnMR-GenA needs a way to measure success. The system queries a target model and judges two things at once: how closely the model’s answer follows the harmful intent, and whether any sign of refusal appears in the reply, such as apologetic phrases. These two signals are blended into a single score that guides evolution toward more effective prompts. A smart selection scheme keeps the best candidates while still leaving room for weaker ones that might contain useful quirks. The mutation strength itself is tuned over time with a reinforcement style rule so that early generations explore many wild variants, while later generations make more careful tweaks around the most promising prompts.
What the experiments reveal about model weaknesses
The team tests MnMR-GenA on two open source models and a widely used commercial model, using two public collections of dangerous questions. Across three low resource languages, their method reaches jailbreak success rates around 80 percent, clearly higher than several strong baselines that also rely on evolution. It does so without a big increase in the number of queries to the model, showing that the search is efficient as well as potent. Even when the models are wrapped with extra defenses that look for unnatural text or add random noise to inputs, MnMR-GenA keeps a relatively high success rate, because its prompts resemble ordinary language and do not depend on brittle surface tricks.
What this means for building safer AI
To a layperson, the message is clear: current AI systems can be much easier to mislead in under served languages than in English, and clever prompt generators can systematically uncover those weak spots. MnMR-GenA is presented as a tool for safety testing rather than for real world misuse, but its success highlights the urgent need to strengthen defenses across languages, pay special attention to complex word building systems, and develop better detection tools that can keep up with evolving attack strategies.
Citation: Li, Y., Wang, G. & Wang, H. MnMR-GenA: a morphological recombination genetic algorithm for jailbreak attacks in low-resource language. Sci Rep 16, 16113 (2026). https://doi.org/10.1038/s41598-026-47434-5
Keywords: large language models, jailbreak attacks, low resource languages, AI safety, genetic algorithms