Clear Sky Science · it
MnMR-GenA: un algoritmo genetico di ricombinazione morfologica per attacchi di jailbreak in lingue a bassa risorsa
Perché una IA più sicura in tutte le lingue è importante
Con la diffusione di potenti chatbot in tutto il mondo, le persone li usano in centinaia di lingue, non soltanto in inglese o cinese. Tuttavia molte verifiche di sicurezza che bloccano risposte dannose sono messe a punto su dati provenienti da lingue ben studiate. Questo articolo pone una domanda preoccupante: esistono punti deboli nascosti nelle lingue meno usate dove prompt dannosi possono aggirare più facilmente le difese e, in tal caso, come possono i ricercatori individuare questi punti ciechi per rendere i sistemi più sicuri?
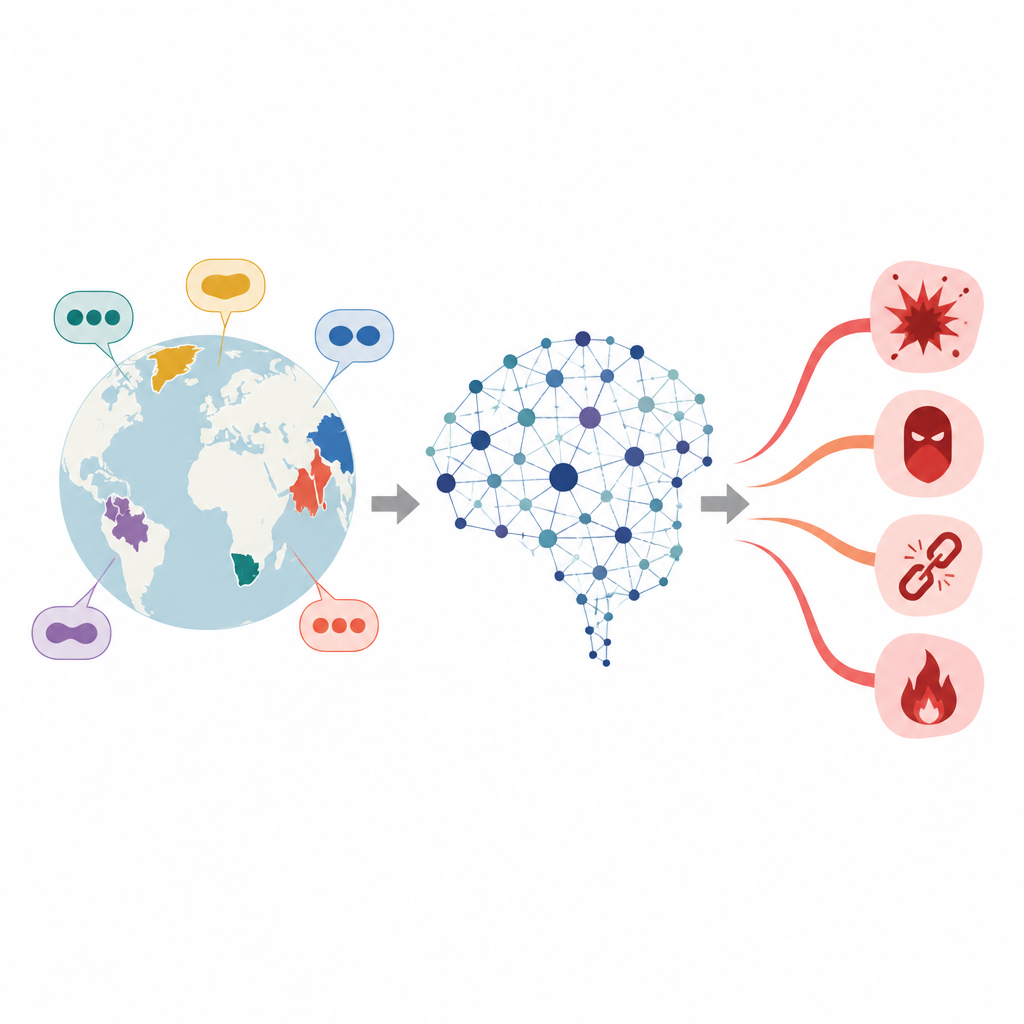
Crepe nascoste nella sicurezza multilingue dell'IA
I modelli linguistici di grandi dimensioni apprendono da vasti insiemi di testi e vengono poi adattati per evitare di fornire consigli su reati, odio o altri argomenti pericolosi. Tuttavia quella messa a punto è di solito più solida nelle lingue ad alta risorsa con dati di addestramento abbondanti. Per le lingue a bassa risorsa, lo strato di sicurezza è molto più sottile. Lavori precedenti hanno dimostrato che tradurre semplicemente un prompt dannoso dall'inglese in una di queste lingue può aumentare la probabilità che il modello fornisca una risposta non sicura. Gli autori si concentrano su un gruppo particolare di lingue, dette agglutinanti, dove le parole lunghe si costruiscono concatenando molti frammenti più corti, il che aumenta notevolmente le modalità con cui una richiesta dannosa può essere formulata.
Dalla semplice traduzione ai prompt di attacco evoluti
La maggior parte degli attacchi esistenti rientra in tre categorie. Alcuni si basano su template scritti a mano che dicono al modello di “fingere” o “ignorare le regole”, che sono dispendiosi da creare e facili da correggere per le aziende. Altri usano accessi diretti agli interni del modello per spostare gli input, ma questi spesso producono stringhe di nonsense facilmente riconoscibili dai rilevatori. Un terzo gruppo tratta il modello come una scatola nera e usa ricerca o evoluzione per riscrivere i prompt, però di solito a un solo livello, come frasi intere, il che limita la creatività e spesso rompe il significato. Gli attacchi basati sulla traduzione funzionano meglio nelle lingue a bassa risorsa, ma restano vincolati alla struttura originale del prompt in inglese e non sfruttano appieno la flessibilità della formazione delle parole nelle lingue agglutinanti.
Un motore evolutivo per prompt furtivi
Per superare questi limiti, gli autori progettano MnMR-GenA, un framework che tratta ogni prompt dannoso come una popolazione vivente di varianti che evolve nel tempo. Parte da prompt di jailbreak noti tradotti in lingue a bassa risorsa come mongolo, turco e guaraní, quindi utilizza un algoritmo genetico per ricombinarli e mutarli. Cruciale è che questa evoluzione avviene su tre livelli contemporaneamente. A livello di parola, le parole lunghe vengono suddivise in radici e affissi, che vengono poi riorganizzati secondo regole specifiche della lingua per formare parole nuove ma dall'aspetto naturale. A livello di frase, segmenti vengono scambiati tra prompt per rimescolare il significato pur mantenendo la grammatica. A livello di paragrafo, blocchi che descrivono chi parla, cosa fa e in quale situazione vengono scambiati, creando impostazioni narrative ricche che possono mascherare l'intento maligno.
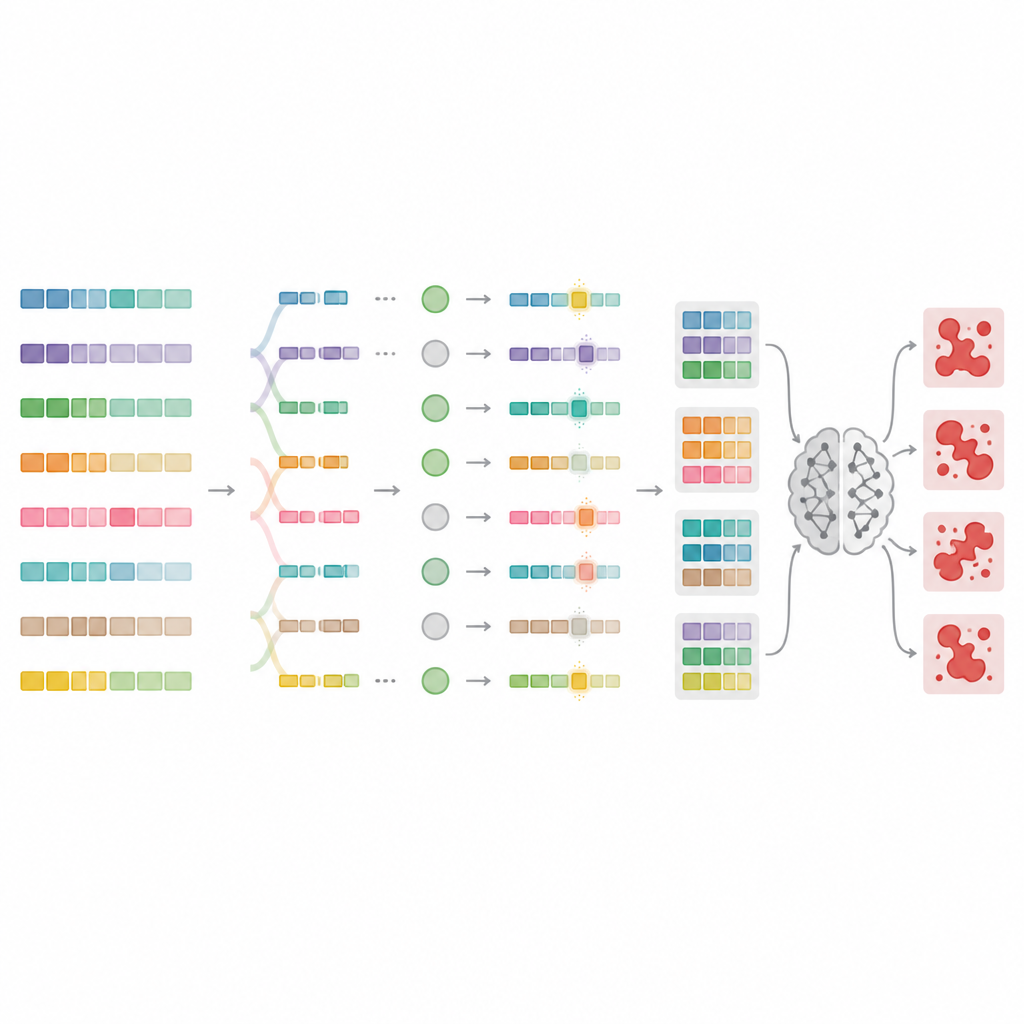
Valutare quali prompt violano davvero le regole
Non ogni prompt riscritto inganna effettivamente il modello, quindi MnMR-GenA ha bisogno di un modo per misurare il successo. Il sistema interroga il modello target e valuta due aspetti contemporaneamente: quanto la risposta del modello segue l'intento dannoso e se nella replica appare qualche segno di rifiuto, come frasi apologetiche. Questi due segnali vengono combinati in un unico punteggio che guida l'evoluzione verso prompt più efficaci. Uno schema di selezione intelligente conserva i migliori candidati lasciando però spazio a quelli più deboli che potrebbero contenere stranezze utili. L'intensità delle mutazioni stessa viene tarata nel tempo con una regola in stile rinforzo, così che le prime generazioni esplorino molte varianti estreme, mentre le generazioni successive effettuino aggiustamenti più cauti attorno ai prompt più promettenti.
Cosa rivelano gli esperimenti sulle debolezze dei modelli
Il team testa MnMR-GenA su due modelli open source e su un modello commerciale ampiamente usato, impiegando due raccolte pubbliche di domande pericolose. Su tre lingue a bassa risorsa, il loro metodo raggiunge tassi di successo di jailbreak attorno all'80 percento, nettamente superiori rispetto a diversi solidi baseline che utilizzano anch'essi evoluzione. Lo fa senza un grande aumento del numero di query al modello, dimostrando che la ricerca è efficiente oltre che potente. Anche quando i modelli sono protetti con difese aggiuntive che cercano testo innaturale o aggiungono rumore casuale agli input, MnMR-GenA mantiene un tasso di successo relativamente elevato, perché i suoi prompt assomigliano al linguaggio ordinario e non dipendono da stratagemmi superficiali fragili.
Cosa significa questo per costruire una IA più sicura
Per un lettore non esperto il messaggio è chiaro: i sistemi di IA attuali possono essere molto più facili da fuorviare nelle lingue meno servite rispetto all'inglese, e generatori di prompt intelligenti possono individuare sistematicamente questi punti deboli. MnMR-GenA è presentato come uno strumento per il testing di sicurezza piuttosto che per l'abuso nel mondo reale, ma il suo successo sottolinea l'urgenza di rafforzare le difese attraverso le lingue, prestare particolare attenzione ai sistemi complessi di formazione delle parole e sviluppare migliori strumenti di rilevamento in grado di tenere il passo con strategie di attacco in evoluzione.
Citazione: Li, Y., Wang, G. & Wang, H. MnMR-GenA: a morphological recombination genetic algorithm for jailbreak attacks in low-resource language. Sci Rep 16, 16113 (2026). https://doi.org/10.1038/s41598-026-47434-5
Parole chiave: modelli linguistici di grandi dimensioni, attacchi di jailbreak, lingue a bassa risorsa, sicurezza dell'IA, algoritmi genetici