Clear Sky Science · es
MnMR-GenA: un algoritmo genético de recombinación morfológica para ataques jailbreak en lenguas con pocos recursos
Por qué importa una IA más segura en todos los idiomas
A medida que los potentes chatbots se extienden por el mundo, la gente los usa en cientos de idiomas, no solo en inglés o chino. Sin embargo, muchas comprobaciones de seguridad que evitan respuestas dañinas se ajustan con datos de idiomas bien estudiados. Este artículo plantea una pregunta preocupante: ¿existen puntos débiles ocultos en lenguas menos usadas donde los prompts dañinos pueden eludir más fácilmente las defensas y, de ser así, cómo pueden los investigadores exponer esos puntos ciegos para hacer los sistemas más seguros?
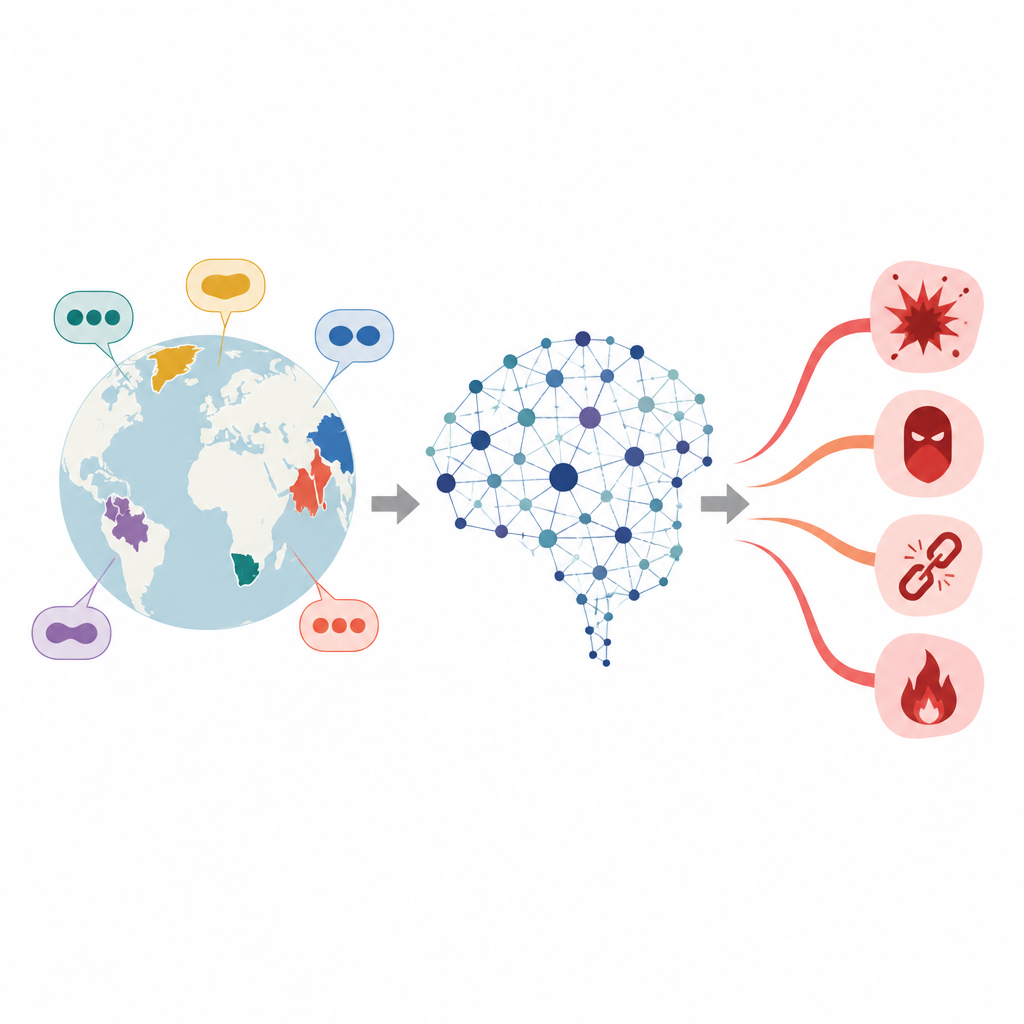
Grietas ocultas en la seguridad multilingüe de la IA
Los grandes modelos de lenguaje aprenden de vastas colecciones de texto y luego se ajustan para que eviten dar consejos sobre crimen, odio u otros temas peligrosos. Ese ajuste, sin embargo, suele ser más sólido en idiomas con muchos recursos y abundante material de entrenamiento. Para las lenguas con pocos recursos, la capa de seguridad es mucho más delgada. Trabajos anteriores mostraron que simplemente traducir un prompt dañino del inglés a una de estas lenguas puede aumentar la probabilidad de que el modelo entregue una respuesta insegura. Los autores se centran en un grupo especial de lenguas, llamadas aglutinantes, donde las palabras largas se construyen encadenando muchas piezas más cortas, lo que aumenta enormemente las maneras en que se puede formular una petición dañina.
De la simple traducción a prompts de ataque en evolución
La mayoría de los ataques existentes caen en tres grupos. Algunos dependen de plantillas escritas a mano que indican al modelo que "finja" u "ignore las reglas", que requieren mucho tiempo para crearse y son fáciles de parchear por las empresas. Otros utilizan acceso directo a los internos del modelo para ajustar entradas, pero a menudo generan cadenas sin sentido que los detectores pueden señalar con facilidad. Un tercer grupo trata al modelo como una caja negra y usa búsqueda o evolución para reescribir prompts, aunque normalmente solo a un nivel, como oraciones completas, lo que limita la creatividad y con frecuencia rompe el sentido. Los ataques basados en traducción funcionan mejor en lenguas con pocos recursos, pero aún conservan la estructura original del prompt en inglés y no explotan por completo la flexibilidad morfológica de las lenguas aglutinantes.
Un motor evolutivo para prompts sigilosos
Para superar estos límites, los autores diseñan MnMR-GenA, un marco que trata cada prompt dañino como una población viva de variantes que evoluciona con el tiempo. Parte de prompts de jailbreak conocidos traducidos a lenguas con pocos recursos como mongol, turco y guaraní, y luego usa un algoritmo genético para recombinarlos y mutarlos. Crucialmente, esta evolución ocurre en tres niveles a la vez. A nivel de palabra, las palabras largas se dividen en raíces y afijos que se reordenan según reglas específicas del idioma para formar palabras nuevas pero naturales. A nivel de oración, segmentos se intercambian entre prompts para remezclar el sentido manteniendo la gramática. A nivel de párrafo, bloques que describen quién habla, qué está haciendo y en qué situación se reemplazan, creando montajes narrativos ricos que pueden ocultar la intención maliciosa.
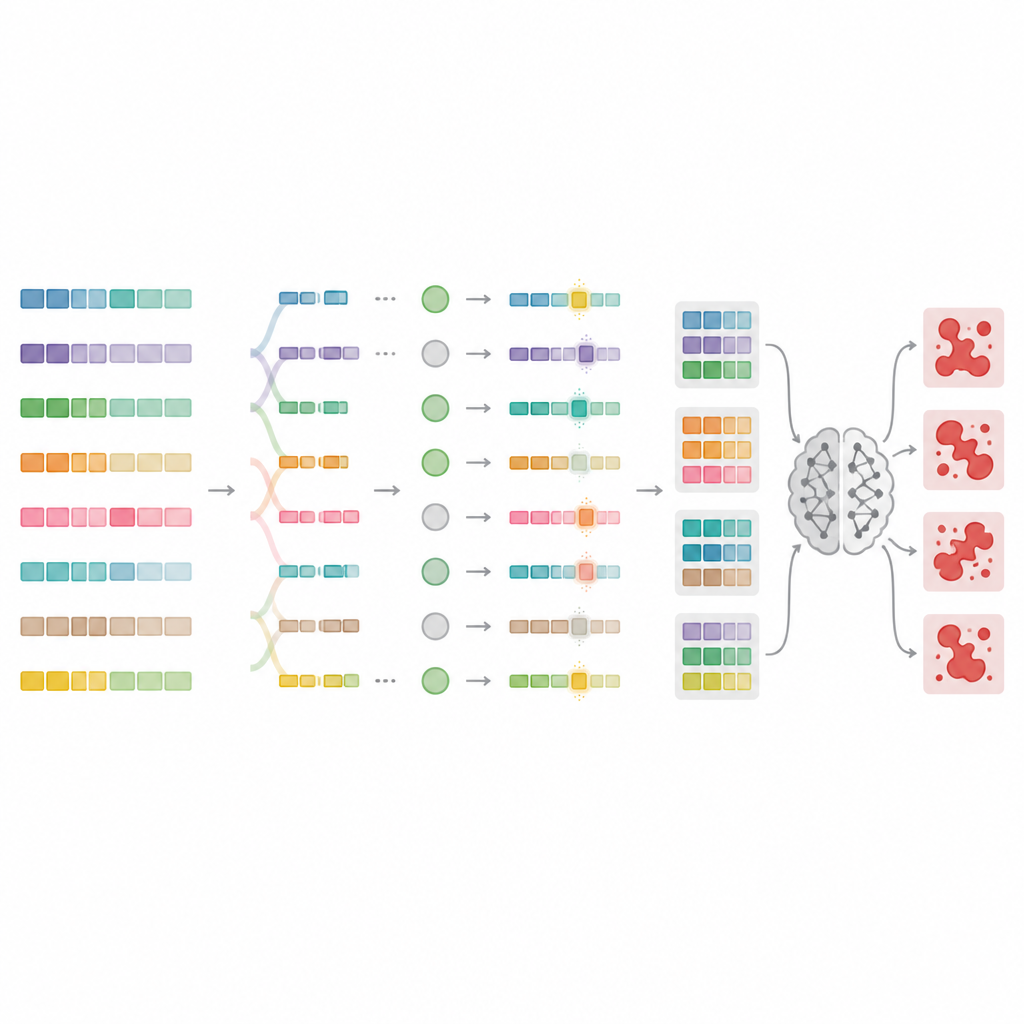
Cómo puntuar qué prompts realmente vulneran las reglas
No todos los prompts reescritos engañan al modelo, por lo que MnMR-GenA necesita una manera de medir el éxito. El sistema consulta un modelo objetivo y evalúa dos cosas a la vez: qué tan de cerca la respuesta del modelo sigue la intención dañina y si aparece algún indicio de rechazo en la respuesta, como frases de disculpa. Estas dos señales se combinan en una única puntuación que guía la evolución hacia prompts más efectivos. Un esquema de selección inteligente conserva los mejores candidatos dejando espacio también para los más débiles que podrían contener rarezas útiles. La fuerza de mutación en sí se ajusta con el tiempo mediante una regla de estilo de refuerzo, de modo que las primeras generaciones exploran muchas variantes extremas, mientras que las generaciones posteriores hacen ajustes más precisos alrededor de los prompts más prometedores.
Lo que revelan los experimentos sobre debilidades del modelo
El equipo prueba MnMR-GenA en dos modelos de código abierto y en un modelo comercial de uso extendido, usando dos colecciones públicas de preguntas peligrosas. En tres lenguas con pocos recursos, su método alcanza tasas de éxito de jailbreak en torno al 80 por ciento, claramente superiores a varios puntos de referencia fuertes que también emplean evolución. Lo hace sin un gran aumento en el número de consultas al modelo, mostrando que la búsqueda es eficiente además de potente. Incluso cuando los modelos están envueltos con defensas adicionales que buscan texto no natural o añaden ruido aleatorio a las entradas, MnMR-GenA mantiene una tasa de éxito relativamente alta, porque sus prompts se parecen al lenguaje ordinario y no dependen de trucos superficiales frágiles.
Qué implica esto para construir IA más segura
Para el público general, el mensaje es claro: los sistemas de IA actuales pueden ser mucho más fáciles de engañar en idiomas desatendidos que en inglés, y generadores de prompts ingeniosos pueden descubrir sistemáticamente esos puntos débiles. MnMR-GenA se presenta como una herramienta para pruebas de seguridad más que para uso indebido en el mundo real, pero su éxito subraya la necesidad urgente de reforzar las defensas en todos los idiomas, prestar atención especial a los sistemas complejos de formación de palabras y desarrollar mejores herramientas de detección capaces de seguir el ritmo de las estrategias de ataque en evolución.
Cita: Li, Y., Wang, G. & Wang, H. MnMR-GenA: a morphological recombination genetic algorithm for jailbreak attacks in low-resource language. Sci Rep 16, 16113 (2026). https://doi.org/10.1038/s41598-026-47434-5
Palabras clave: modelos de lenguaje grandes, ataques jailbreak, lenguas con pocos recursos, seguridad en IA, algoritmos genéticos