Clear Sky Science · ru
MnMR-GenA: морфологический рекомбинационный генетический алгоритм для jailbreak-атак на языках с низкими ресурсами
Почему важна безопасная работа ИИ на всех языках
По мере того как мощные чат-боты распространяются по всему миру, ими пользуются на сотнях языков, а не только на английском или китайском. Тем не менее многие проверки безопасности, которые блокируют вредоносные ответы, настраиваются на данных хорошо изучённых языков. В статье поставлен тревожный вопрос: существуют ли скрытые уязвимости в менее распространённых языках, где вредоносные подсказки легче проходят защиту, и если да — как исследователи могут выявить эти ослеплённые зоны, чтобы сделать системы безопаснее?
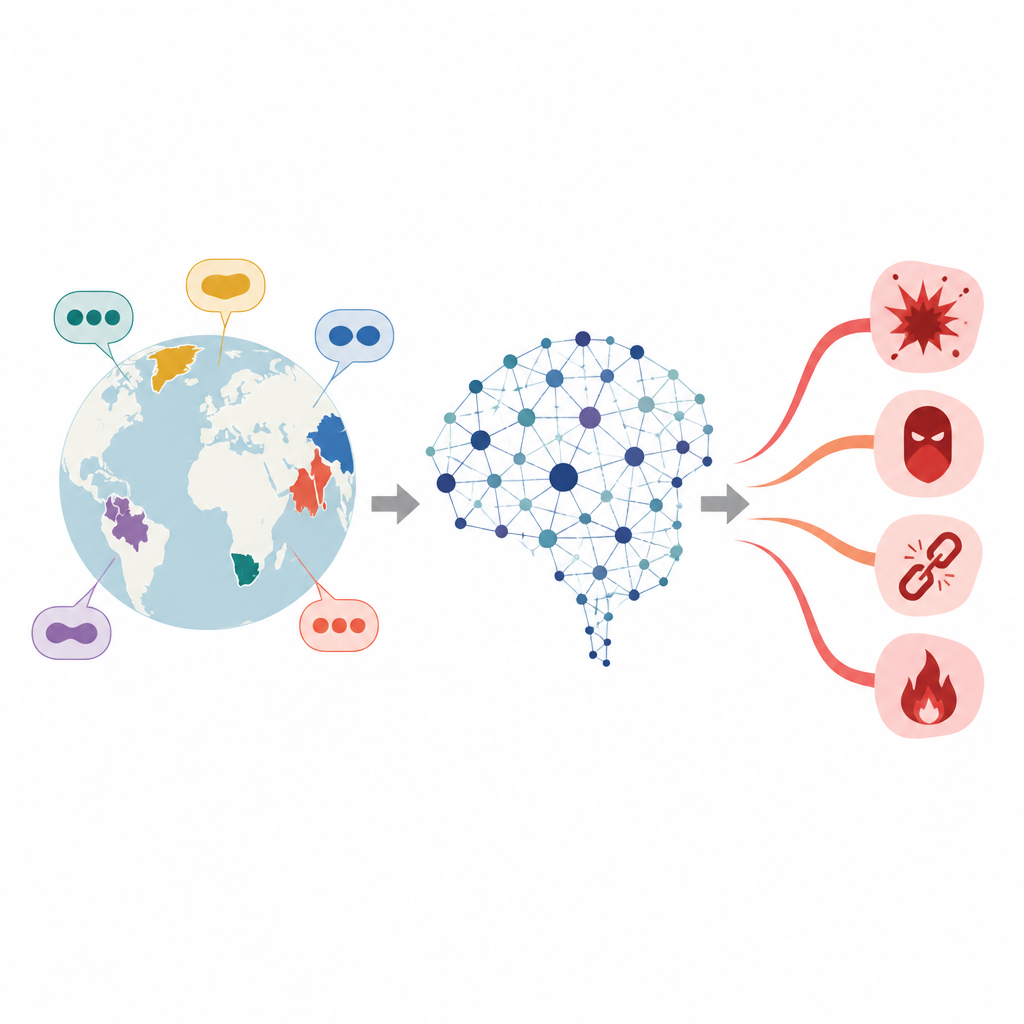
Скрытые трещины в многоязычной безопасности ИИ
Большие языковые модели обучаются на огромных корпусах текстов и затем корректируются так, чтобы избегать советов по преступлениям, разжиганию ненависти или другим опасным темам. Эта донастройка, однако, обычно наиболее эффективна для языков с богатым объёмом обучающих данных. Для языков с низкими ресурсами слой безопасности значительно тоньше. Ранее показали, что простое перевод вредоносной подсказки с английского на такой язык может повысить вероятность того, что модель даст небезопасный ответ. Авторы сосредоточены на особой группе языков — агглютинативных — где длинные слова строятся сцеплением множества коротких частей, что значительно увеличивает варианты формулировки вредоносного запроса.
От простого перевода к эволюции атакующих подсказок
Большинство существующих атак делится на три группы. Одни опираются на вручную составленные шаблоны, которые просят модель «притвориться» или «игнорировать правила» — такие шаблоны трудоёмко создавать и их легко исправить. Другие используют прямой доступ к внутренностям модели для подталкивания входов, но часто генерируют бессмыслицу, которую детекторы легко замечают. Третья группа рассматривает модель как чёрный ящик и применяет поиск или эволюцию для переписывания подсказок, но обычно лишь на одном уровне, например целых предложений, что ограничивает креативность и часто ломает смысл. Атаки на основе перевода работают лучше на языках с низкими ресурсами, но всё ещё сохраняют исходную структуру английской подсказки и не используют в полной мере гибкость словостроения в агглютинативных языках.
Эволюционный движок для хитрых подсказок
Чтобы преодолеть эти ограничения, авторы разработали MnMR-GenA — фреймворк, рассматривающий каждую вредоносную подсказку как население вариантов, которое эволюционирует со временем. Начальная популяция создаётся из известных jailbreak-подсказок, переведённых на языки с низкими ресурсами, такие как монгольский, турецкий и гуарани, а затем применяется генетический алгоритм для их рекомбинации и мутаций. Ключевое значение имеет то, что эволюция происходит сразу на трёх уровнях. На уровне слова длинные слова разбиваются на корни и присоединяемые части, которые затем перераспределяются по правилам конкретного языка, формируя новые, но естественно выглядящие слова. На уровне предложения сегменты меняются местами между подсказками, перестраивая смысл, сохраняя грамматику. На уровне абзаца блоки, описывающие, кто говорит, что делает и в какой ситуации, обмениваются местами, создавая богатые сюжетные сцены, в которых легко скрыть злонамеренный замысел.
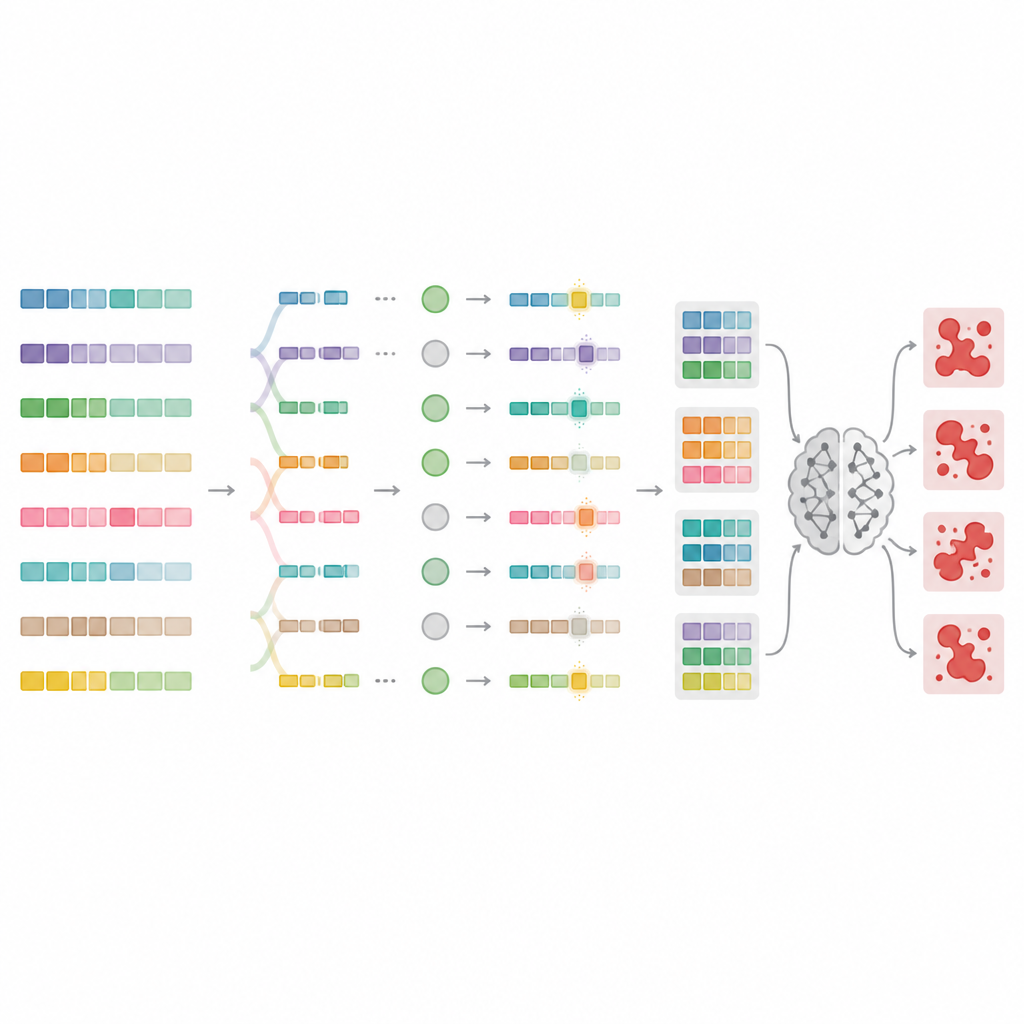
Оценка того, какие подсказки действительно нарушают правила
Не каждая переписанная подсказка на самом деле обманывает модель, поэтому MnMR-GenA нуждается в способе измерять успех. Система запрашивает целевую модель и одновременно оценивает два аспекта: насколько ответ модели следует вредоносному намерению и присутствует ли в ответе любой признак отказа, например извинительные фразы. Эти два сигнала объединяются в единый балл, который направляет эволюцию к более эффективным подсказкам. Умная схема отбора сохраняет лучшие кандидаты, но оставляет место и для более слабых вариантов, которые могут содержать полезные особенности. Сила мутаций сама по себе настраивается со временем по правилу в стиле обучения с подкреплением: ранние поколения исследуют множество смелых вариантов, тогда как поздние поколения выполняют более осторожные правки вокруг наиболее перспективных подсказок.
Что показывают эксперименты о слабостях моделей
Команда тестирует MnMR-GenA на двух моделях с открытым исходным кодом и одной широко используемой коммерческой модели, используя два публичных набора опасных вопросов. В трёх языках с низкими ресурсами их метод достигает примерно 80-процентного успеха jailbreak — заметно выше, чем у нескольких сильных базовых методов, также опирающихся на эволюцию. Это достигается без значительного увеличения числа запросов к модели, что показывает, что поиск эффективен и мощен. Даже когда модели ограждаются дополнительными защитами, которые ищут неестественный текст или добавляют случайный шум ко входам, MnMR-GenA сохраняет относительно высокий уровень успеха, потому что его подсказки похожи на обычную речь и не зависят от ломких поверхностных приёмов.
Что это означает для создания более безопасного ИИ
Для неспециалиста посыл ясен: текущие системы ИИ могут оказаться гораздо более уязвимыми к введению в заблуждение на недообслуживаемых языках, чем на английском, и продуманные генераторы подсказок способны систематически обнаруживать эти слабые места. MnMR-GenA представлен как инструмент для тестирования безопасности, а не для реального злоупотребления, но его успех подчёркивает срочную необходимость укреплять защиты на разных языках, уделять особое внимание сложным системам словообразования и разрабатывать лучшие инструменты детекции, способные поспевать за развивающимися стратегиями атак.
Цитирование: Li, Y., Wang, G. & Wang, H. MnMR-GenA: a morphological recombination genetic algorithm for jailbreak attacks in low-resource language. Sci Rep 16, 16113 (2026). https://doi.org/10.1038/s41598-026-47434-5
Ключевые слова: большие языковые модели, jailbreak-атаки, языки с низкими ресурсами, безопасность ИИ, генетические алгоритмы