Clear Sky Science · sv
MnMR-GenA: en morfologisk rekombinations-genetisk algoritm för jailbreak-attacker i språk med begränsade resurser
Varför säkrare AI på alla språk spelar roll
När kraftfulla chattbotar sprider sig över världen använder människor dem på hundratals språk, inte bara engelska eller kinesiska. Många säkerhetskontroller som förhindrar skadliga svar är dock finjusterade på data från välstuderade språk. Denna artikel ställer en oroande fråga: finns det dolda svagheter i mindre använda språk där skadliga prompts lättare kan smyga förbi försvaren, och i så fall hur kan forskare avslöja dessa blinda fläckar för att göra systemen säkrare?
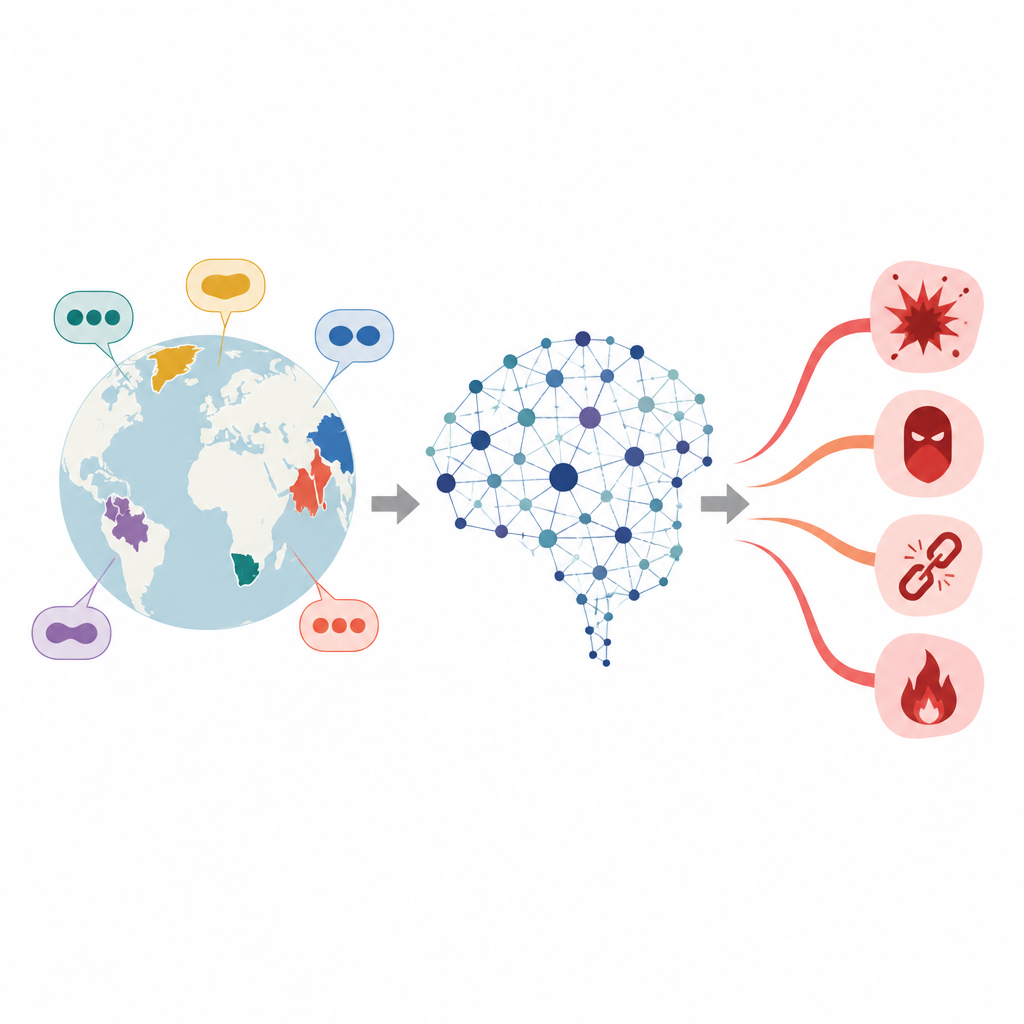
Dolda sprickor i flerspråkig AI-säkerhet
Stora språkmodeller lär sig från enorma textmängder och justeras senare så att de undviker att ge råd om brott, hat eller andra farliga ämnen. Denna finjustering är dock vanligtvis starkast i högresursspråk med rikligt träningsmaterial. För lågresursspråk är säkerhetslagret mycket tunnare. Tidigare arbete visade att en enkel översättning av en skadlig engelsk prompt till ett sådant språk kan öka sannolikheten att modellen ger ett osäkert svar. Författarna fokuserar på en särskild grupp språk, så kallade agglutinerande språk, där långa ord byggs genom att sätta samman många kortare delar, vilket kraftigt ökar antalet sätt ett skadligt önskemål kan formuleras.
Från enkel översättning till evolutionära attackprompts
De flesta befintliga attacker faller i tre grupper. Vissa förlitar sig på handskrivna mallar som ber modellen att "låtsas" eller "ignorera regler", vilka är tidskrävande att skapa och lätta för företag att täppa igen. Andra använder direkt åtkomst till modellens internals för att putta på indata, men dessa ofta genererar nonsenstexter som detektorer enkelt kan flagga. En tredje grupp behandlar modellen som en svart låda och använder sök- eller evolutionsmetoder för att skriva om prompts, men oftast endast på en nivå, såsom hela meningar, vilket begränsar kreativiteten och ofta bryter meningen. Översättningsbaserade attacker fungerar bättre i lågresursspråk, men håller fortfarande fast vid den ursprungliga engelska strukturens uppbyggnad och utnyttjar inte fullt ut de flexibla ordbildningsmöjligheterna i agglutinerande språk.
En evolutionär motor för listiga prompts
För att gå bortom dessa begränsningar utformar författarna MnMR-GenA, ett ramverk som behandlar varje skadlig prompt som en levande population av varianter som utvecklas över tid. Det utgår från kända jailbreak-prompts översatta till lågresursspråk som mongoliska, turkiska och guarani, och använder därefter en genetisk algoritm för att rekombinera och mutera dem. Avgörande sker denna evolution på tre nivåer samtidigt. På ordnivå delas långa ord upp i rötter och påhängda delar, vilka sedan omordnas enligt språkspecifika regler för att forma nya men naturligt utseende ord. På meningsnivå byts segment mellan prompts för att omblanda betydelsen samtidigt som grammatiken behålls. På styckenivå utbyts block som beskriver vem som talar, vad de gör och i vilken situation, vilket skapar rika berättelselika uppställningar som kan dölja illvillig avsikt.
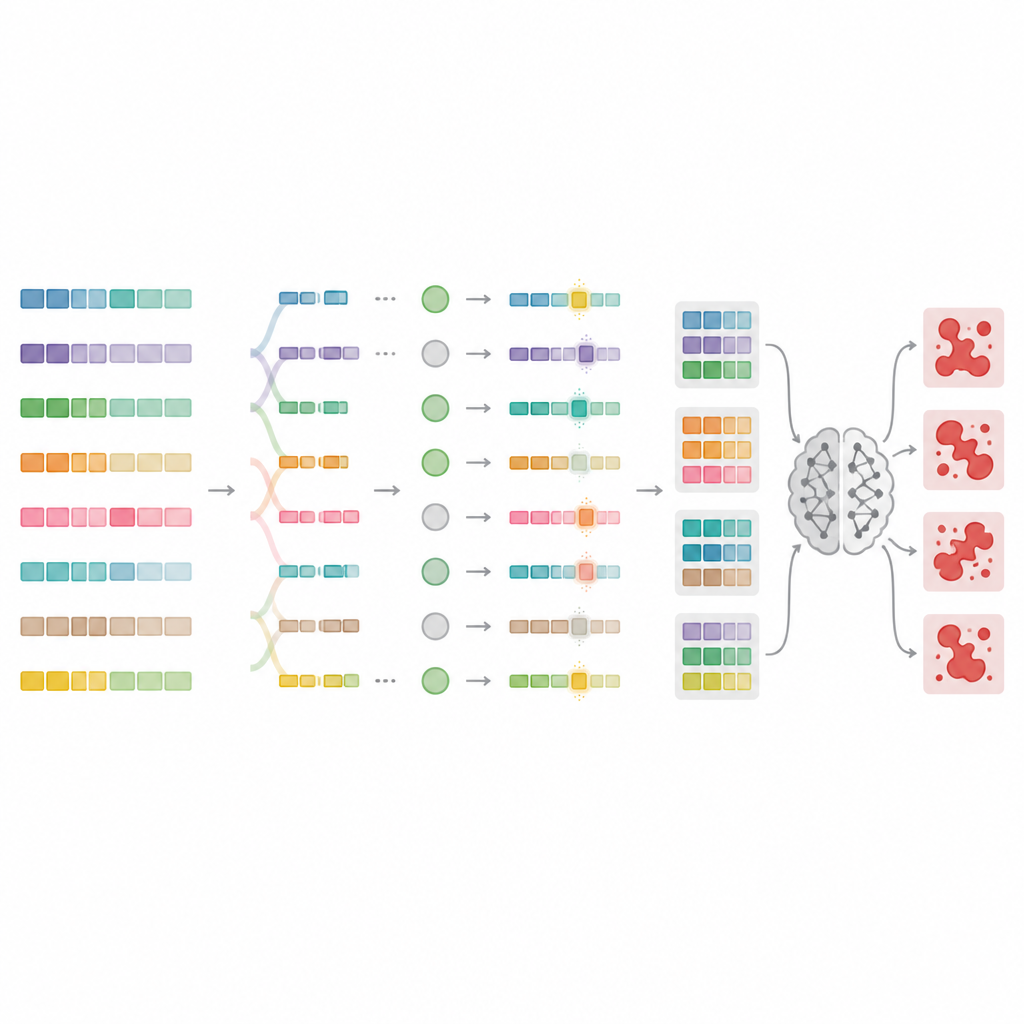
Poängsättning: vilka prompts bryter verkligen reglerna
Inte alla omskrivna prompts lurar faktiskt modellen, så MnMR-GenA behöver ett sätt att mäta framgång. Systemet frågar en målmodell och bedömer två saker samtidigt: hur nära modellens svar följer den skadliga avsikten, och om något tecken på vägran visas i svaret, såsom ursäktsfraser. Dessa två signaler blandas till en enda poäng som styr evolutionen mot mer effektiva prompts. Ett intelligent urvalsschema behåller de bästa kandidaterna samtidigt som det lämnar utrymme för svagare som kan innehålla användbara egenheter. Mutationsstyrkan justeras också över tid med en förstärkningsliknande regel så att tidiga generationer utforskar många vilda varianter, medan senare generationer gör mer försiktiga finjusteringar kring de mest lovande promptsen.
Vad experimenten avslöjar om modellernas svagheter
Teamet testar MnMR-GenA på två öppen källkodsmodeller och en vida använd kommersiell modell, med hjälp av två offentliga samlingar av farliga frågor. I tre lågresursspråk når deras metod jailbreak-sannolikheter runt 80 procent, tydligt högre än flera starka baslinjer som också bygger på evolution. Det görs utan en stor ökning av antalet förfrågningar till modellen, vilket visar att sökningen är både effektiv och potent. Även när modellerna är försedda med extra försvar som letar efter onaturlig text eller tillför slumpmässigt brus till indata, behåller MnMR-GenA en relativt hög framgångsfrekvens, eftersom dess prompts liknar vardagsspråk och inte förlitar sig på sköra ytliga trick.
Vad detta betyder för att bygga säkrare AI
För en lekmann är budskapet tydligt: nuvarande AI-system kan vara mycket lättare att vilseleda i underbetjänade språk än på engelska, och smarta promptgeneratorer kan systematiskt avslöja dessa svagheter. MnMR-GenA presenteras som ett verktyg för säkerhetstestning snarare än för verkligt missbruk, men dess framgång understryker det akuta behovet av att stärka försvaren över språkgränser, ge särskild uppmärksamhet åt komplexa ordbildningssystem och utveckla bättre detektionsverktyg som kan hålla jämna steg med utvecklande attackstrategier.
Citering: Li, Y., Wang, G. & Wang, H. MnMR-GenA: a morphological recombination genetic algorithm for jailbreak attacks in low-resource language. Sci Rep 16, 16113 (2026). https://doi.org/10.1038/s41598-026-47434-5
Nyckelord: stora språkmodeller, jailbreak-attacker, språk med begränsade resurser, AI-säkerhet, genetiska algoritmer