Clear Sky Science · zh
图注意力与文本语义提升个性化推荐
为何更智能的推荐很重要
每次你打开购物网站、电影应用或在线书店时,都依赖算法从海量选项中筛出几项可能感兴趣的内容。然而,当关于用户或物品的数据稀少,或人们的口味随时间变化时,这些推荐系统常常表现欠佳。本研究提出了一种新的推荐方式,它不仅考察谁点击了什么,还“阅读”周边文本——例如评论和描述——并在相关概念网络中探索,以更好地猜测你下一步可能喜欢的内容。
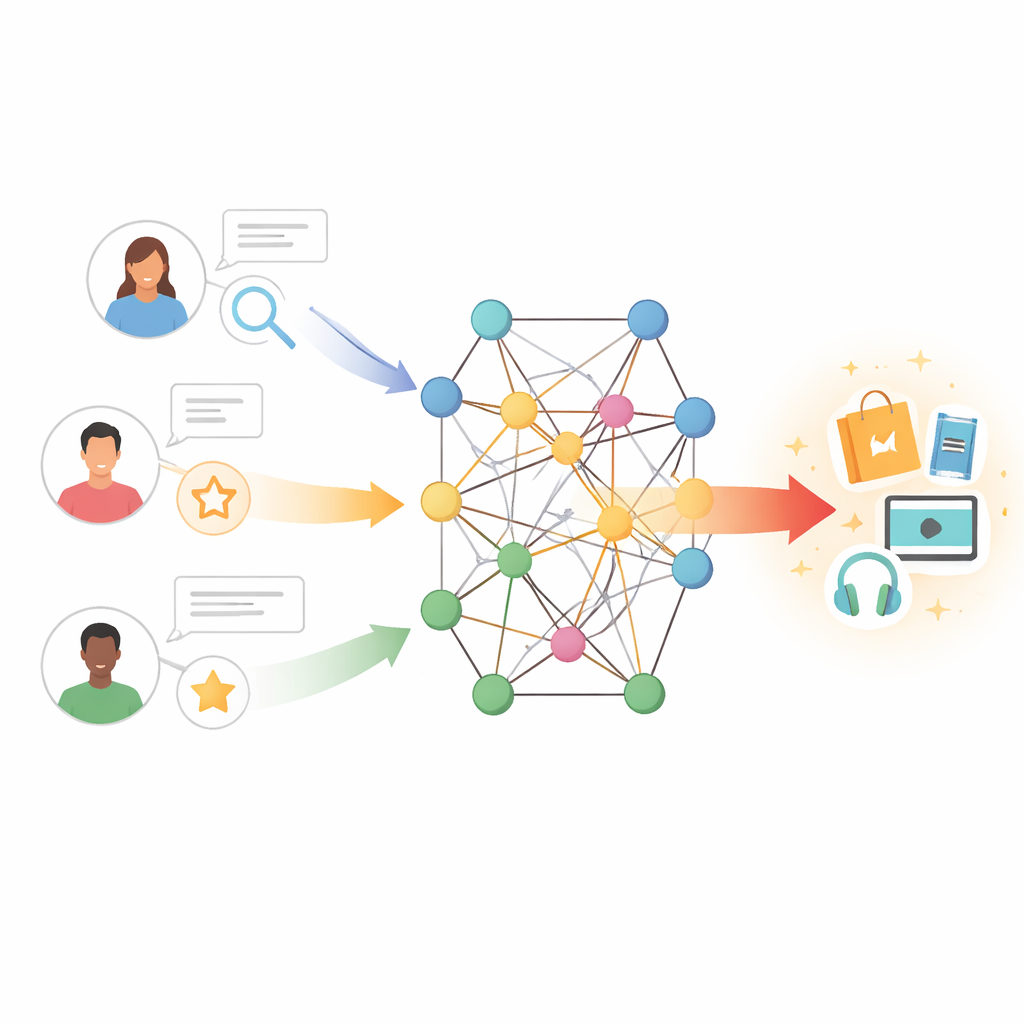
从简单匹配到丰富关联
传统推荐工具有点像找到具有相似购物或观看历史的人并复制他们的选择。这种方法称为协同过滤,依赖于大量的用户-物品交互表。 当这些表稀疏——因为用户是新手、物品鲜为人知或反馈不足——系统很快就会缺乏线索。早期为解决这一问题的尝试加入了文本特征:例如挖掘用户评论以捕捉对剧情、写作风格或演员的评价。这些方法有帮助,但它们常常把所有评论视为同等重要,未能建模用户喜好与物品特征之间的细腻互动。
构建知识网络
作者采取不同策略,将用户和物品置于知识图谱中——一个节点可以表示书籍、电影、作者、类型及其他实体,边则编码它们之间的关系。在这种设置下,间接路径可以揭示隐藏的偏好;例如,喜欢多部与同一导演或主题相关电影的用户,可能也会喜欢相关作品,即便他们从未评分过这些作品。然而,单纯在图中无差别地探索多步路径会引入噪声并带来高昂的计算成本。挑战在于让模型从网络中倾听最有信息量的邻居,同时忽略误导性或过于远的连接。
让模型学会“注意”
所提出的模型称为TNRA,通过在用户侧使用图注意力网络、在物品侧使用图卷积来应对这一问题。对于用户,模型从他们交互过的物品出发,在知识图谱中追踪多步的“涟漪”,并为更相关的连接分配更高权重。这种注意力机制意味着并非所有邻居节点都会同等影响用户画像;系统学习哪些路径对预测新兴趣最重要。在物品侧,模型采样有限的一组近邻节点——例如相关产品或属性——并融合它们的特征以形成每个物品的精炼表征,同样由这些邻居与特定用户口味的匹配程度来指导。
教系统学会“阅读”
一个关键之处在于TNRA并不只依赖图结构。它还从用户评论和物品描述中的语言中学习。经过清洗和分词后,系统将句子转换为紧凑的向量以捕捉含义,例如对特定类型的热情或对节奏的抱怨。这些来自文本的向量与基于图的用户和物品表征融合,为每个节点增添了结构连接与语义细节。当系统随后比较用户与物品时,实际上是在比较它们的组合“故事”,而不仅是原始的点击历史。
将方法付诸测试
研究人员在两个知名基准数据集上评估了TNRA:一个大规模的图书评分集和MovieLens-1M电影数据集,两者都结合了商业知识图谱。他们将该方法与若干使用深度学习和图方法的强基线进行了比较。在多项指标上——包括模型区分用户互动过的物品与被忽略物品的能力,以及相关物品出现在推荐列表前列的多少——TNRA始终领先。它在分数上略有但有意义的提升,特别是在数据稀疏的场景中,并且训练时间和内存使用与其他基于图的系统相当。
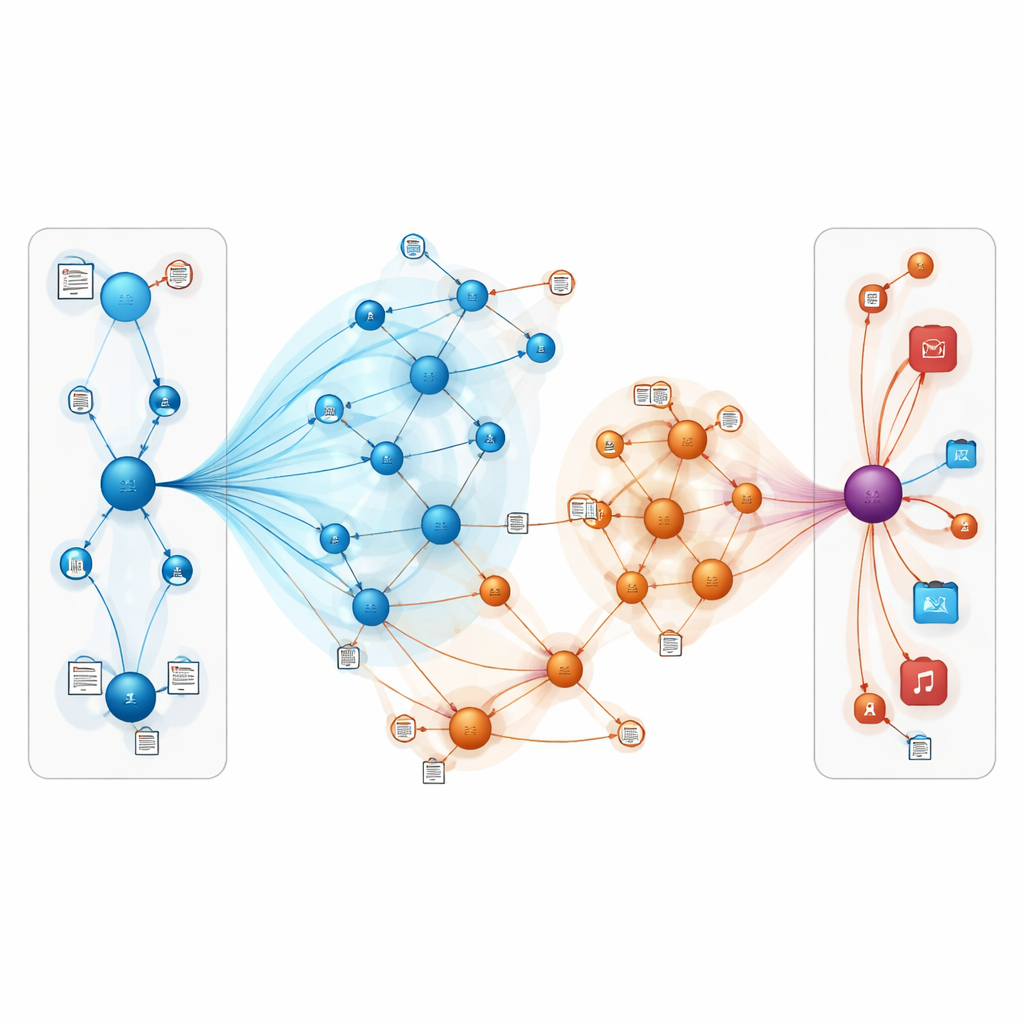
对日常用户意味着什么
简单来说,这项工作表明,通过结合两种思路——把在线世界表示为相互关联的实体网络,并让模型“读懂”用户评论和描述之间的含义——推荐系统可以变得更准确、更具鲁棒性。通过有针对性地关注最相关的连接并融合文本意义,TNRA能更好地推断人们可能喜欢的内容,即便显式信号很少。对用户而言,这可能意味着更契合的图书和电影推荐、更少无关的列表,尤其是对小众口味和传统方法容易忽视的新物品。
引用: Dong, J., Shen, Z., Luo, H. et al. Graph attention and text semantics improve personalized recommendation. Sci Rep 16, 11672 (2026). https://doi.org/10.1038/s41598-026-46737-x
关键词: 个性化推荐, 知识图谱, 图神经网络, 文本语义, 推荐系统