Clear Sky Science · pl
Uwaga na grafie i semantyka tekstu poprawiają spersonalizowane rekomendacje
Dlaczego inteligentniejsze sugestie mają znaczenie
Za każdym razem, gdy otwierasz sklep internetowy, aplikację filmową lub księgarnię online, polegasz na algorytmach, które przesiewają morze opcji i wyłuskują kilka, które mogą cię zainteresować. Systemy rekomendacyjne często jednak mają trudności, gdy dostępnych jest niewiele danych o użytkowniku lub przedmiocie, albo gdy gusta ludzi zmieniają się w czasie. W tym badaniu wprowadzono nowe podejście do rekomendacji, które nie tylko analizuje, kto co kliknął, lecz także „czyta” otaczający tekst — na przykład recenzje i opisy — oraz eksploruje sieć powiązanych pojęć, by lepiej przewidzieć, co może ci się spodobać.
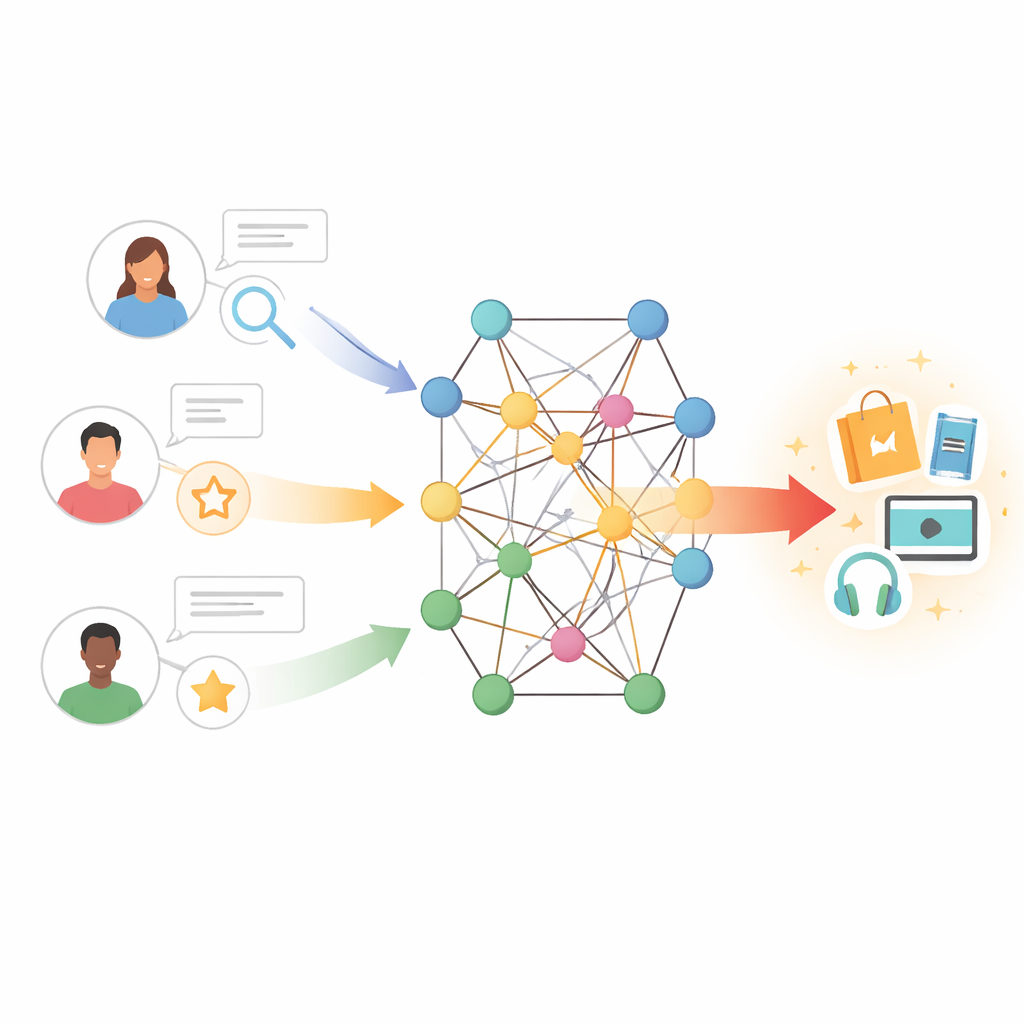
Od prostych dopasowań do bogatych powiązań
Tradycyjne narzędzia rekomendacyjne działają trochę jak znajdowanie osób o podobnych historiach zakupowych lub oglądania i kopiowanie ich wyborów. To podejście, zwane filtracją kolaboratywną, opiera się na dużych tabelach interakcji użytkownik–przedmiot. Gdy te tabele są skąpe — na przykład gdy użytkownicy są nowi, przedmioty mało znane lub informacji zwrotnej jest niewiele — system szybko traci wskazówki. Wcześniejsze próby naprawy tego problemu dodawały cechy tekstowe: na przykład wydobywanie opinii z recenzji, by uchwycić zdania o fabule, stylu pisania czy aktorach. Metody te pomogły, ale często traktowały wszystkie recenzje jako jednakowo istotne i nie modelowały subtelnej interakcji między gustami użytkownika a cechami przedmiotu.
Budowanie sieci wiedzy
Autorzy wybrali inne podejście, umieszczając użytkowników i przedmioty w grafie wiedzy — sieci, w której węzły mogą reprezentować książki, filmy, autorów, gatunki i inne byty, a krawędzie kodują ich relacje. W takim ustawieniu pośrednie ścieżki mogą ujawniać ukryte preferencje; na przykład użytkownik, który lubi kilka filmów powiązanych z tym samym reżyserem lub motywem, może też polubić powiązane dzieła, nawet jeśli nigdy ich nie ocenił. Jednak naiwne eksplorowanie wielu kroków w takim grafie może wprowadzać szum i wysokie koszty obliczeniowe. Wyzwanie polega na tym, by model słuchał najbardziej informacyjnych sąsiadów w tej sieci, ignorując wprowadzające w błąd lub odległe powiązania.
Pozwolenie modelowi na zwracanie uwagi
Proponowany model, nazwany TNRA, radzi sobie z tym, wykorzystując grafowe sieci uwagi po stronie użytkownika oraz konwolucję grafową po stronie przedmiotu. Dla użytkowników model śledzi wieloetapowe „fala” przez graf wiedzy zaczynając od przedmiotów, z którymi mieli interakcje, przypisując wyższe wagi bardziej istotnym powiązaniom. Mechanizm uwagi oznacza, że nie wszystkie sąsiednie węzły wpływają na profil użytkownika jednakowo; system uczy się, które ścieżki mają największe znaczenie przy przewidywaniu nowych zainteresowań. Po stronie przedmiotów model próbuje ograniczonego zestawu pobliskich węzłów — takich jak powiązane produkty lub atrybuty — i miesza ich cechy, by stworzyć dopracowany portret każdego przedmiotu, ponownie kierując się tym, jak blisko te sąsiedztwa odpowiadają gustom danego użytkownika.
Nauczanie systemu „czytania”
Kluczowy element polega na tym, że TNRA nie polega wyłącznie na strukturze grafu. Uczy się także z języka zawartego w recenzjach użytkowników i opisach przedmiotów. Po oczyszczeniu i tokenizacji tekstu system zamienia zdania w zwarte wektory, które uchwytują znaczenie, na przykład entuzjazm dla konkretnego gatunku lub narzekania na tempo akcji. Wektory pochodzące z tekstu są łączone z reprezentacjami opartymi na grafie użytkowników i przedmiotów, wzbogacając każdy węzeł zarówno o połączenia strukturalne, jak i niuanse semantyczne. Gdy system później porównuje użytkownika i przedmiot, w praktyce porównuje ich połączone „opowieści”, a nie tylko surowe historie kliknięć.
Weryfikacja podejścia
Naukowcy ocenili TNRA na dwóch dobrze znanych zbiorach: dużej kolekcji ocen książek oraz zbiorze MovieLens-1M z ocenami filmów, oba wzbogacone o komercyjny graf wiedzy. Porównali swoje podejście z kilkoma silnymi metodami bazowymi wykorzystującymi głębokie uczenie i metody grafowe. W wielu metrykach — w tym w zdolności modelu do rozróżniania przedmiotów, z którymi użytkownik wchodził w interakcję, od tych, które zignorował, oraz w liczbie istotnych przedmiotów pojawiających się na szczycie listy rekomendacji — TNRA konsekwentnie wypadało lepiej. Uzyskało nieznacznie, ale istotnie wyższe wyniki, szczególnie w ustawieniach o niewielkiej ilości danych, przy czasach trenowania i użyciu pamięci porównywalnych z innymi systemami opartymi na grafach.
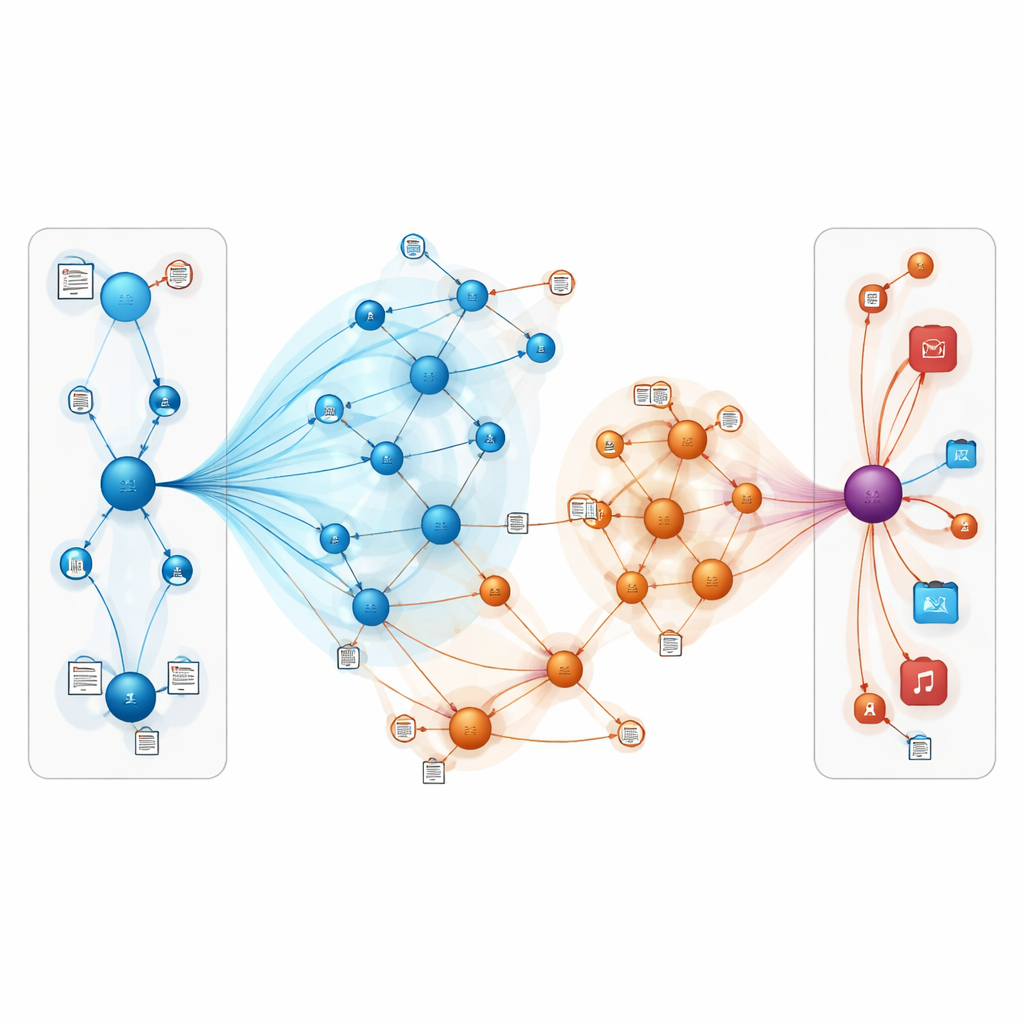
Co to oznacza dla codziennych użytkowników
Mówiąc prosto, praca ta pokazuje, że systemy rekomendacyjne mogą stać się dokładniejsze i bardziej odporne, łącząc dwie koncepcje: reprezentowanie świata online jako powiązanej sieci bytów oraz pozwolenie modelowi „czytać między wierszami” recenzji i opisów. Poprzez staranne skupienie uwagi na najbardziej relewantnych powiązaniach i włączenie znaczeń tekstowych, TNRA potrafi lepiej wywnioskować, co ludzie prawdopodobnie polubią, nawet gdy sygnałów jest niewiele. Dla użytkowników może to oznaczać trafniejsze propozycje książek i filmów oraz mniej nietrafionych list, zwłaszcza dla niszowych gustów i nowych przedmiotów, które tradycyjne metody mają tendencję pomijać.
Cytowanie: Dong, J., Shen, Z., Luo, H. et al. Graph attention and text semantics improve personalized recommendation. Sci Rep 16, 11672 (2026). https://doi.org/10.1038/s41598-026-46737-x
Słowa kluczowe: spersonalizowane rekomendacje, graf wiedzy, grafowa sieć neuronowa, semantyka tekstu, systemy rekomendacyjne