Clear Sky Science · fr
L’attention sur le graphe et la sémantique textuelle améliorent la recommandation personnalisée
Pourquoi des suggestions plus intelligentes comptent
Chaque fois que vous ouvrez un site de commerce, une application de films ou une librairie en ligne, vous comptez sur des algorithmes pour trier une avalanche d’options et en mettre en avant quelques-unes susceptibles de vous intéresser. Pourtant, ces systèmes de recommandation peinent souvent quand les données sur un utilisateur ou un élément sont rares, ou quand les goûts des personnes évoluent. Cette étude présente une nouvelle manière de formuler des recommandations qui ne se contente pas de voir qui a cliqué quoi, mais qui lit aussi le texte environnant — comme les avis et les descriptions — et explore un réseau de concepts liés pour mieux deviner ce qui vous plaira ensuite.
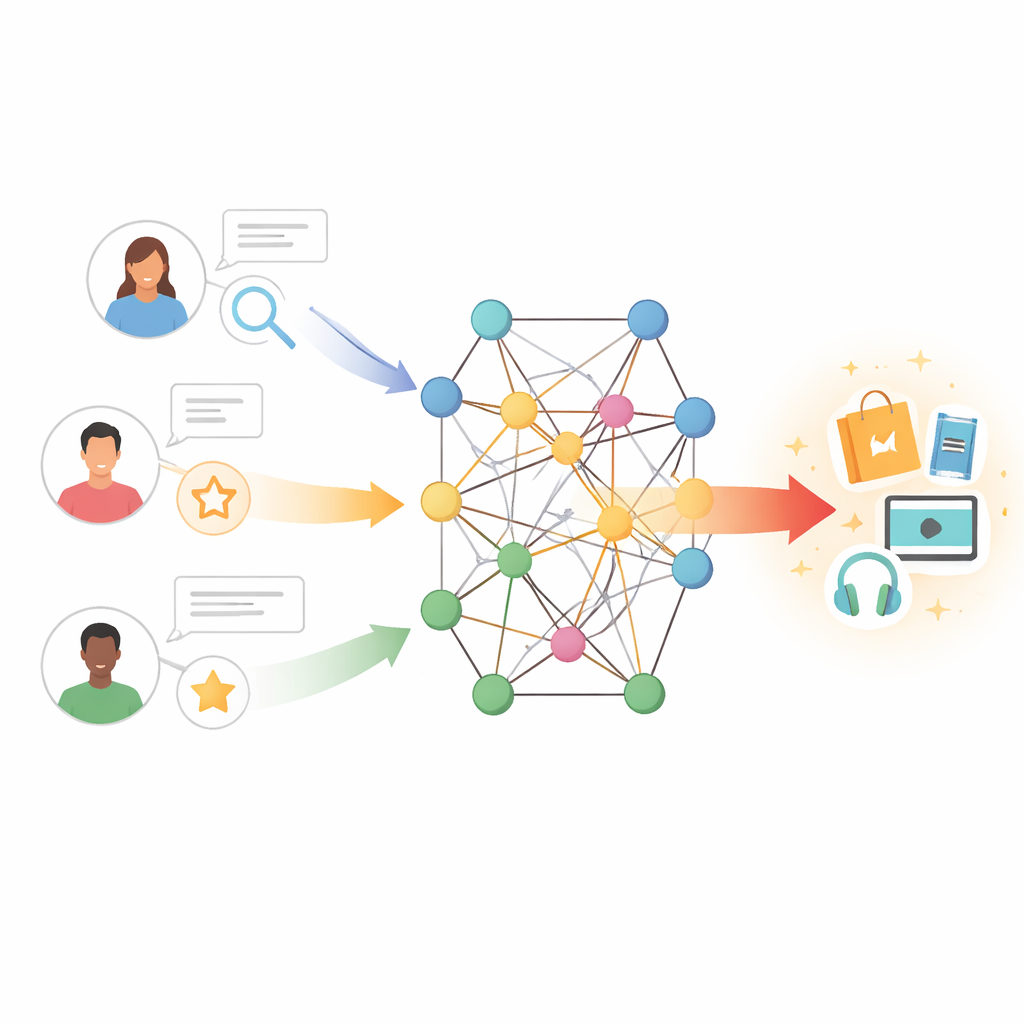
Des correspondances simples aux connexions riches
Les outils de recommandation traditionnels fonctionnent un peu comme retrouver des personnes ayant des historiques d’achat ou de consultation semblables et reproduire leurs choix. Cette approche, appelée filtrage collaboratif, repose sur de grandes tables d’interactions utilisateur–élément. Lorsque ces tables sont creuses — parce que les utilisateurs sont nouveaux, les éléments obscurs ou les retours rares — le système manque rapidement d’indices. Des tentatives antérieures pour corriger ce problème ont ajouté des caractéristiques textuelles : par exemple, exploiter les avis des utilisateurs pour saisir des opinions sur l’intrigue, le style d’écriture ou les acteurs. Ces méthodes ont aidé, mais elles traitaient souvent tous les avis comme également importants et n’ont pas su modéliser les subtils échanges entre les préférences d’un utilisateur et les caractéristiques d’un élément.
Construire un réseau de connaissances
Les auteurs adoptent une autre approche en plaçant utilisateurs et éléments au sein d’un graphe de connaissances — un réseau où les nœuds peuvent représenter des livres, des films, des auteurs, des genres et d’autres entités, et où les arêtes encodent leurs relations. Dans ce contexte, des chemins indirects peuvent révéler des préférences cachées ; par exemple, un utilisateur qui aime plusieurs films reliés au même réalisateur ou au même thème peut aussi apprécier des œuvres connexes même s’il ne les a jamais notées. Toutefois, explorer naïvement de nombreux pas dans un tel graphe peut introduire du bruit et un coût computationnel élevé. Le défi consiste à permettre au modèle d’écouter les voisins les plus informatifs de ce réseau tout en ignorant les connexions trompeuses ou trop éloignées.
Permettre au modèle de prêter attention
Le modèle proposé, appelé TNRA, relève ce défi en utilisant des réseaux d’attention sur graphe pour la partie utilisateur et des convolutions sur graphe pour la partie élément. Pour les utilisateurs, le modèle suit des « ondulations » multi‑étapes à travers le graphe de connaissances à partir des éléments avec lesquels ils ont interagi, en attribuant des poids plus élevés aux connexions les plus pertinentes. Ce mécanisme d’attention signifie que tous les nœuds voisins n’influencent pas le profil utilisateur de la même manière ; le système apprend quels chemins importent le plus pour prédire de nouveaux intérêts. Côté élément, le modèle échantillonne un ensemble limité de nœuds voisins — tels que des produits ou attributs liés — et combine leurs caractéristiques pour former un portrait affiné de chaque élément, là encore guidé par la proximité de ces voisins avec les goûts d’un utilisateur donné.
Apprendre au système à lire
Un élément clé est que TNRA ne se fonde pas uniquement sur la structure du graphe. Il apprend aussi à partir du langage utilisé dans les avis des utilisateurs et les descriptions d’articles. Après nettoyage et tokenisation des textes, le système transforme les phrases en vecteurs compacts capturant le sens, comme l’enthousiasme pour un genre particulier ou des reproches sur le rythme. Ces vecteurs dérivés du texte sont fusionnés aux représentations basées sur le graphe des utilisateurs et des éléments, enrichissant chaque nœud à la fois par des connexions structurelles et des nuances sémantiques. Lorsque le système compare ensuite un utilisateur et un élément, il compare en fait leurs « histoires » combinées plutôt que de simples historiques de clics bruts.
Mettre l’approche à l’épreuve
Les chercheurs ont évalué TNRA sur deux jeux de référence bien connus : une grande collection de notes de livres et le jeu de données MovieLens‑1M pour les films, tous deux enrichis par un graphe de connaissances commercial. Ils ont comparé leur approche à plusieurs références solides utilisant l’apprentissage profond et des méthodes sur graphe. Selon plusieurs mesures — notamment la capacité du modèle à distinguer les éléments avec lesquels un utilisateur a interagi de ceux qu’il a ignorés, et le nombre d’éléments pertinents apparaissant en haut de la liste de recommandations — TNRA est systématiquement arrivé en tête. Il a obtenu des scores légèrement mais significativement supérieurs, surtout dans les contextes où les données sont rares, tout en affichant des temps d’entraînement et une consommation mémoire comparables à ceux d’autres systèmes basés sur des graphes.
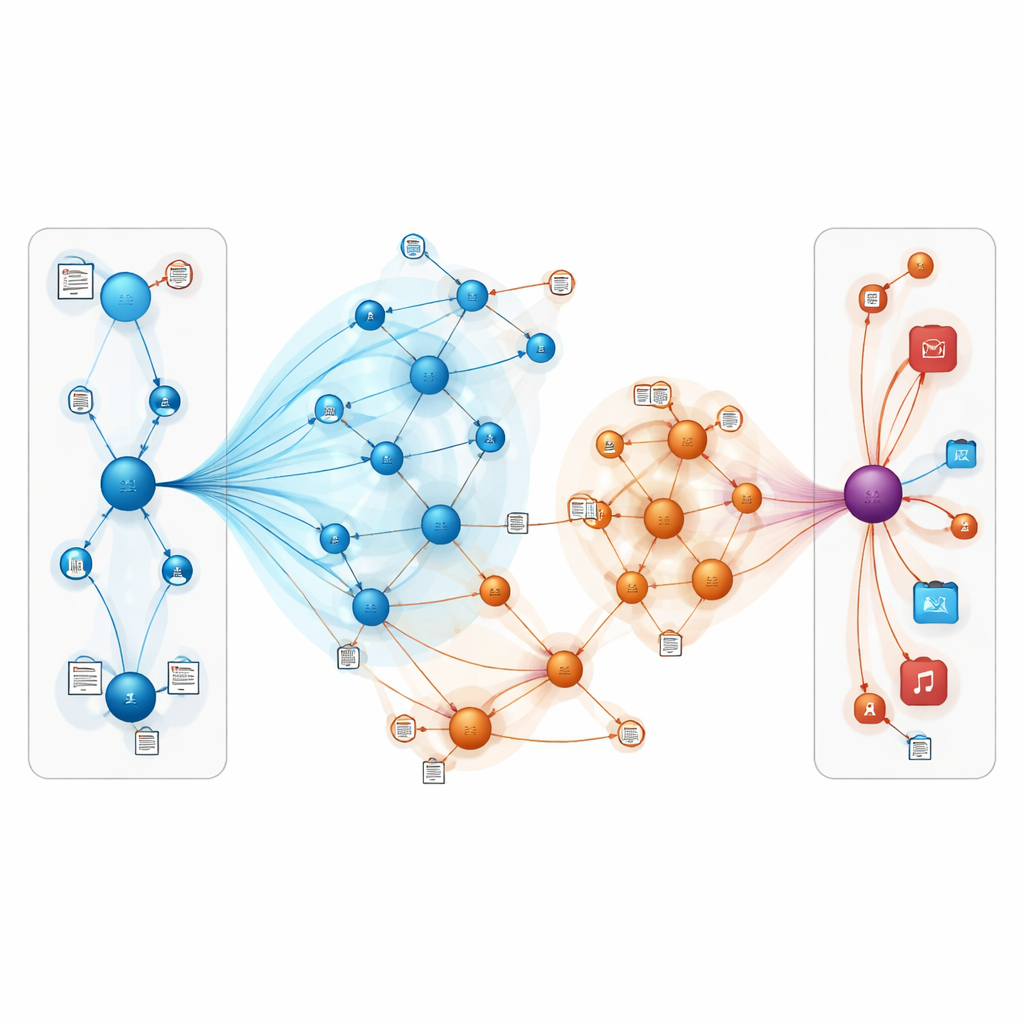
Ce que cela signifie pour les utilisateurs au quotidien
Concrètement, ce travail montre que les systèmes de recommandation peuvent devenir plus précis et plus robustes en combinant deux idées : représenter le monde en ligne comme une toile interconnectée d’entités et permettre au modèle de « lire entre les lignes » des avis et des descriptions. En concentrant soigneusement l’attention sur les connexions les plus pertinentes et en intégrant le sens textuel, TNRA peut mieux inférer ce que les gens sont susceptibles d’apprécier, même lorsqu’il existe peu de signaux explicites. Pour les utilisateurs, cela peut se traduire par des suggestions de livres et de films plus adaptées et moins de listes non pertinentes, en particulier pour les goûts de niche et les nouveaux éléments que les méthodes traditionnelles ont tendance à négliger.
Citation: Dong, J., Shen, Z., Luo, H. et al. Graph attention and text semantics improve personalized recommendation. Sci Rep 16, 11672 (2026). https://doi.org/10.1038/s41598-026-46737-x
Mots-clés: recommandation personnalisée, graphe de connaissances, réseau de neurones sur graphe, sémantique textuelle, systèmes de recommandation