Clear Sky Science · it
L'attenzione sui grafi e la semantica testuale migliorano la raccomandazione personalizzata
Perché suggerimenti più intelligenti contano
Ogni volta che apri un sito di e-commerce, un'app per film o una libreria online, ti affidi ad algoritmi che selezionano tra una marea di opzioni un piccolo insieme che potrebbe interessarti. Tuttavia, questi sistemi di raccomandazione faticano quando ci sono pochi dati su un utente o un elemento, o quando i gusti delle persone cambiano nel tempo. Questo studio introduce un nuovo approccio per fare raccomandazioni che non solo considera chi ha cliccato cosa, ma legge anche il testo circostante — come recensioni e descrizioni — ed esplora una rete di concetti correlati per indovinare meglio cosa ti piacerà dopo.
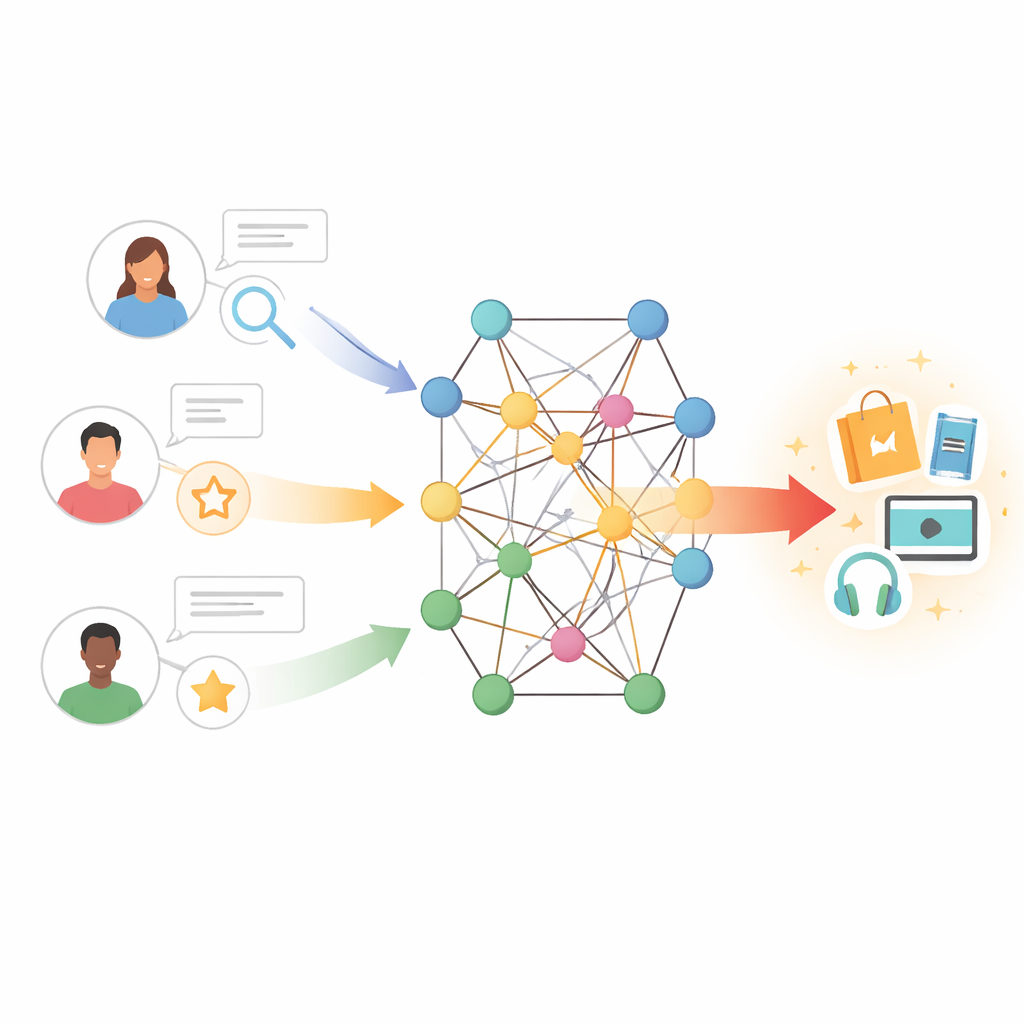
Da semplici corrispondenze a connessioni ricche
Gli strumenti di raccomandazione tradizionali funzionano un po' come trovare persone con storie di acquisto o visione simili e copiare le loro scelte. Questo approccio, detto collaborative filtering, si basa su grandi tabelle di interazioni utente–elemento. Quando queste tabelle sono scarse — perché gli utenti sono nuovi, gli oggetti sono oscuri o il feedback è limitato — il sistema perde presto indizi. Tentativi precedenti per risolvere il problema hanno introdotto caratteristiche testuali: per esempio, estrarre informazioni dalle recensioni degli utenti per catturare opinioni su trame, stili di scrittura o attori. Questi metodi hanno aiutato, ma spesso trattavano tutte le recensioni come ugualmente importanti e non riuscivano a modellare il sottile rapporto tra i gusti di un utente e le caratteristiche di un elemento.
Costruire una rete di conoscenza
Gli autori adottano un approccio diverso collocando utenti e oggetti all'interno di un knowledge graph — una rete in cui i nodi possono rappresentare libri, film, autori, generi e altre entità, e gli archi codificano le loro relazioni. In questo contesto, percorsi indiretti possono rivelare preferenze nascoste; per esempio, un utente che apprezza diversi film collegati allo stesso regista o tema potrebbe gradire opere correlate anche se non le ha mai valutate. Tuttavia, esplorare ingenuamente molti passi in un grafo può introdurre rumore e un alto costo computazionale. La sfida è permettere al modello di ascoltare i vicini più informativi in questa rete ignorando connessioni fuorvianti o lontane.
Lasciare che il modello presti attenzione
Il modello proposto, chiamato TNRA, affronta questo usando reti di attenzione sui grafi lato utente e convoluzioni sui grafi lato oggetto. Per gli utenti, il modello segue «increspature» multistep attraverso il knowledge graph partendo dagli elementi con cui hanno interagito, assegnando pesi più alti alle connessioni più rilevanti. Questo meccanismo di attenzione implica che non tutti i nodi vicini influenzano allo stesso modo il profilo dell'utente; il sistema impara quali percorsi sono più importanti per prevedere nuovi interessi. Sul lato degli oggetti, il modello campiona un insieme limitato di nodi vicini — come prodotti correlati o attributi — e fonde le loro caratteristiche per formare un ritratto raffinato di ciascun elemento, ancora guidato da quanto quei vicini si allineano con i gusti di un dato utente.
Insegnare al sistema a leggere
Una svolta chiave è che TNRA non si affida solo alla struttura del grafo. Impara anche dal linguaggio delle recensioni degli utenti e delle descrizioni degli oggetti. Dopo la pulizia e la tokenizzazione del testo, il sistema trasforma le frasi in vettori compatti che catturano il significato, come l'entusiasmo per un genere particolare o lamentele sul ritmo. Questi vettori derivati dal testo vengono fusi con le rappresentazioni basate sul grafo di utenti e oggetti, arricchendo ogni nodo sia con connessioni strutturali sia con sfumature semantiche. Quando il sistema poi confronta un utente e un elemento, confronta efficacemente le loro «storie» combinate anziché solo storici di click grezzi.
Mettere l'approccio alla prova
I ricercatori hanno valutato TNRA su due benchmark noti: una vasta raccolta di valutazioni di libri e il dataset MovieLens-1M, entrambi arricchiti con un knowledge graph commerciale. Hanno confrontato il loro approccio con diversi forti baseline che utilizzano deep learning e metodi su grafi. Su più misure — inclusa la capacità del modello di distinguere gli elementi con cui un utente ha interagito da quelli ignorati, e quante voci rilevanti compaiono in cima alla lista di raccomandazione — TNRA è risultato costantemente superiore. Ha ottenuto punteggi leggermente ma significativamente più alti, specialmente in scenari con dati scarsi, e lo ha fatto con tempi di addestramento e uso di memoria comparabili ad altri sistemi basati su grafi.
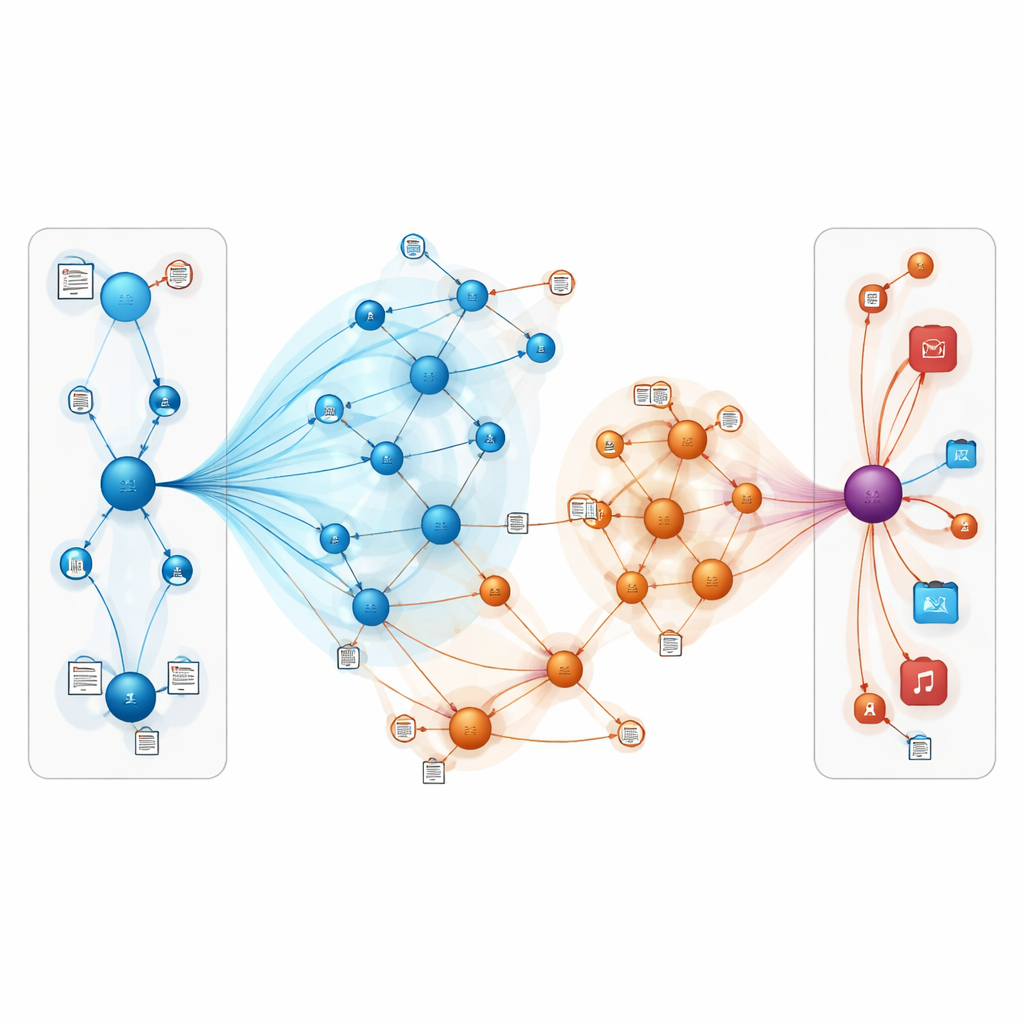
Cosa significa per gli utenti di tutti i giorni
In termini semplici, questo lavoro mostra che i sistemi di raccomandazione possono diventare più accurati e resistenti combinando due idee: rappresentare il mondo online come una rete interconnessa di entità e permettere al modello di «leggere tra le righe» delle recensioni e delle descrizioni. Focalizzandosi con cura sulle connessioni più rilevanti e integrando il significato testuale, TNRA può inferire meglio cosa è probabile che le persone apprezzino, anche quando ci sono pochi segnali espliciti. Per gli utenti, ciò potrebbe tradursi in suggerimenti di libri e film più pertinenti e in meno liste irrilevanti, in particolare per gusti di nicchia e nuovi elementi che i metodi tradizionali tendono a trascurare.
Citazione: Dong, J., Shen, Z., Luo, H. et al. Graph attention and text semantics improve personalized recommendation. Sci Rep 16, 11672 (2026). https://doi.org/10.1038/s41598-026-46737-x
Parole chiave: raccomandazione personalizzata, knowledge graph, graph neural network, semantica del testo, sistemi di raccomandazione