Clear Sky Science · sv
Grafuppmärksamhet och textsemantik förbättrar personliga rekommendationer
Varför smartare förslag spelar roll
Varje gång du öppnar en butikssajt, en filmapp eller en nätbokhandel förlitar du dig på algoritmer som ska sålla bland ett hav av alternativ och lyfta fram några som faktiskt kan intressera dig. Dessa rekommendationssystem har dock ofta svårt när det finns lite data om en användare eller en vara, eller när människors smak förändras över tid. Denna studie introducerar ett nytt sätt att skapa rekommendationer som inte bara ser vem som klickat vad, utan också läser den omgivande texten — såsom recensioner och beskrivningar — och utforskar ett nätverk av relaterade begrepp för bättre gissningar om vad du kommer att gilla härnäst.
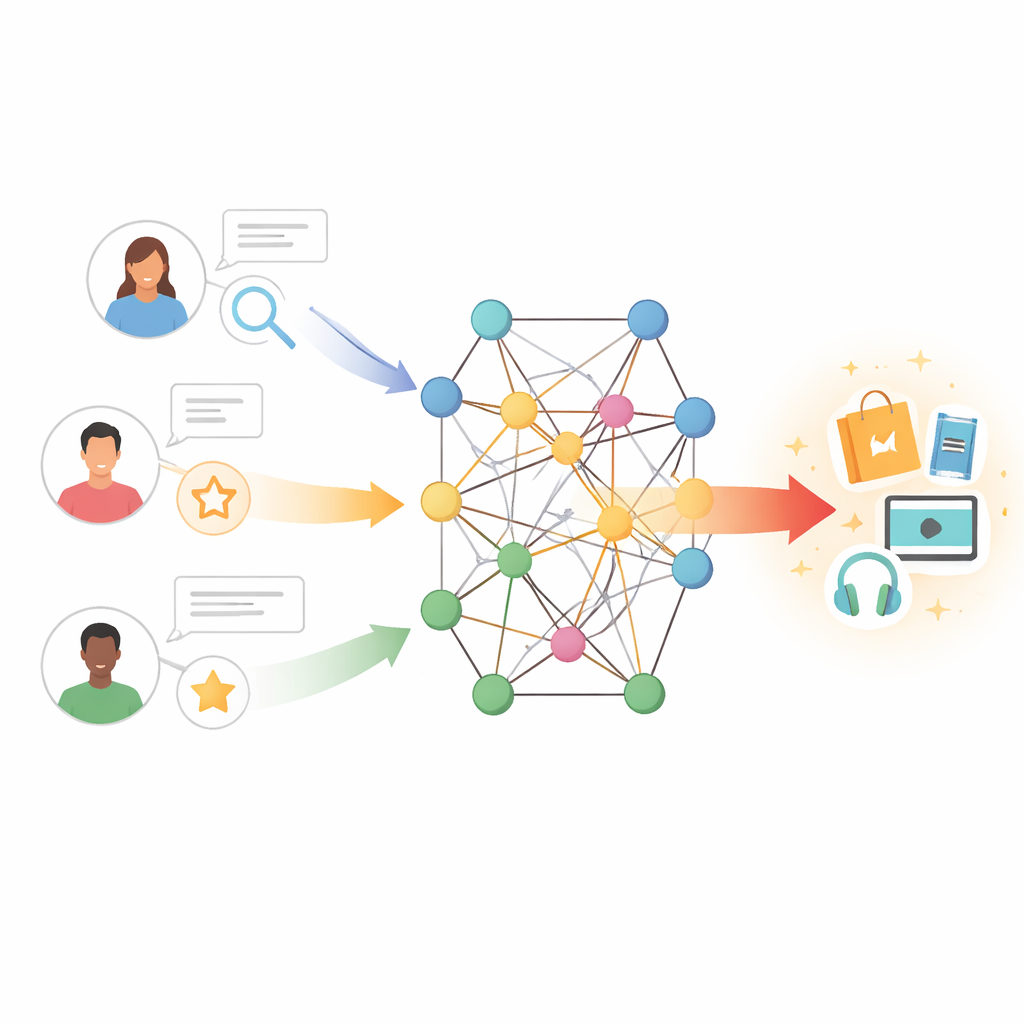
Från enkla matchningar till rika kopplingar
Traditionella rekommendationsverktyg fungerar något som att hitta personer med liknande köp- eller visningshistorik och kopiera deras val. Detta tillvägagångssätt, kallat kollaborativ filtrering, bygger på stora tabeller med användar–vara-interaktioner. När dessa tabeller är glesa — för att användare är nya, varor är obskyra eller återkopplingen är knapp — får systemet snabbt slut på ledtrådar. Tidigare försök att åtgärda detta lade till texterna som funktioner: till exempel att utvinna användarrecensioner för att fånga åsikter om handlingar, skrivstilar eller skådespelare. Dessa metoder hjälpte, men behandlade ofta alla recensioner som lika viktiga och misslyckades med att modellera det subtila samspelet mellan en användares smak och en varas egenskaper.
Bygga ett kunskapsnät
Författarna väljer en annan väg genom att placera användare och varor i en kunskapsgraf — ett nätverk där noder kan representera böcker, filmer, författare, genrer och andra entiteter, och kanter kodar deras relationer. I denna miljö kan indirekta vägar avslöja dolda preferenser; till exempel kan en användare som gillar flera filmer kopplade till samma regissör eller tema också uppskatta relaterade verk även om de aldrig betygsatt dem. Att naivt utforska många steg i en sådan graf kan dock introducera brus och hög beräkningskostnad. Utmaningen är att få modellen att lyssna till de mest informativa grannarna i nätverket samtidigt som vilseledande eller avlägsna kopplingar ignoreras.
Låta modellen uppmärksamma
Den föreslagna modellen, kallad TNRA, tar itu med detta genom att använda grafuppmärksamhetsnätverk på användarsidan och grafkonvolution på varusidan. För användare spårar modellen flerstegs ”vågor” genom kunskapsgrafen med start i de varor de interagerat med och tilldelar högre vikter åt mer relevanta kopplingar. Denna uppmärksamhetsmekanism innebär att inte alla närliggande noder påverkar användarprofilen lika mycket; systemet lär sig vilka vägar som är viktigast för att förutsäga nya intressen. På varusidan sampelar modellen ett begränsat antal närliggande noder — såsom relaterade produkter eller attribut — och blandar deras egenskaper för att bilda en förfinad porträttering av varje vara, återigen styrt av hur väl dessa grannar stämmer överens med en viss användares smak.
Lära systemet att läsa
En viktig nyans är att TNRA inte förlitar sig enbart på grafstrukturen. Det lär sig också av språket i användarrecensioner och varubeskrivningar. Efter att texten rensats och tokeniserats omvandlar systemet meningar till kompakta vektorer som fångar betydelse, till exempel entusiasm för en viss genre eller klagomål på tempo. Dessa textbaserade vektorer förenas med grafbaserade representationer av användare och varor och berikar varje nod med både strukturella kopplingar och semantisk nyans. När systemet senare jämför en användare och en vara jämför det i praktiken deras kombinerade ”berättelser” snarare än enbart råa klickhistoriker.
Sätta metoden på prov
Forskarna utvärderade TNRA på två välkända benchmarks: en storskalig samling med bokbetyg och MovieLens-1M-filmdatabasen, båda förbättrade med en kommersiell kunskapsgraf. De jämförde sin metod med flera starka baslinjer som använder djupinlärning och grafmetoder. Över flera mätvärden — inklusive hur väl modellen skiljer varor en användare engagerat sig i från sådana de ignorerat, och hur många relevanta varor som hamnar högt i rekommendationslistan — hamnade TNRA konsekvent före. Den uppnådde något men meningsfullt högre poäng, särskilt i situationer där data är glesa, och gjorde det med träningstider och minnesanvändning som är jämförbara med andra grafbaserade system.
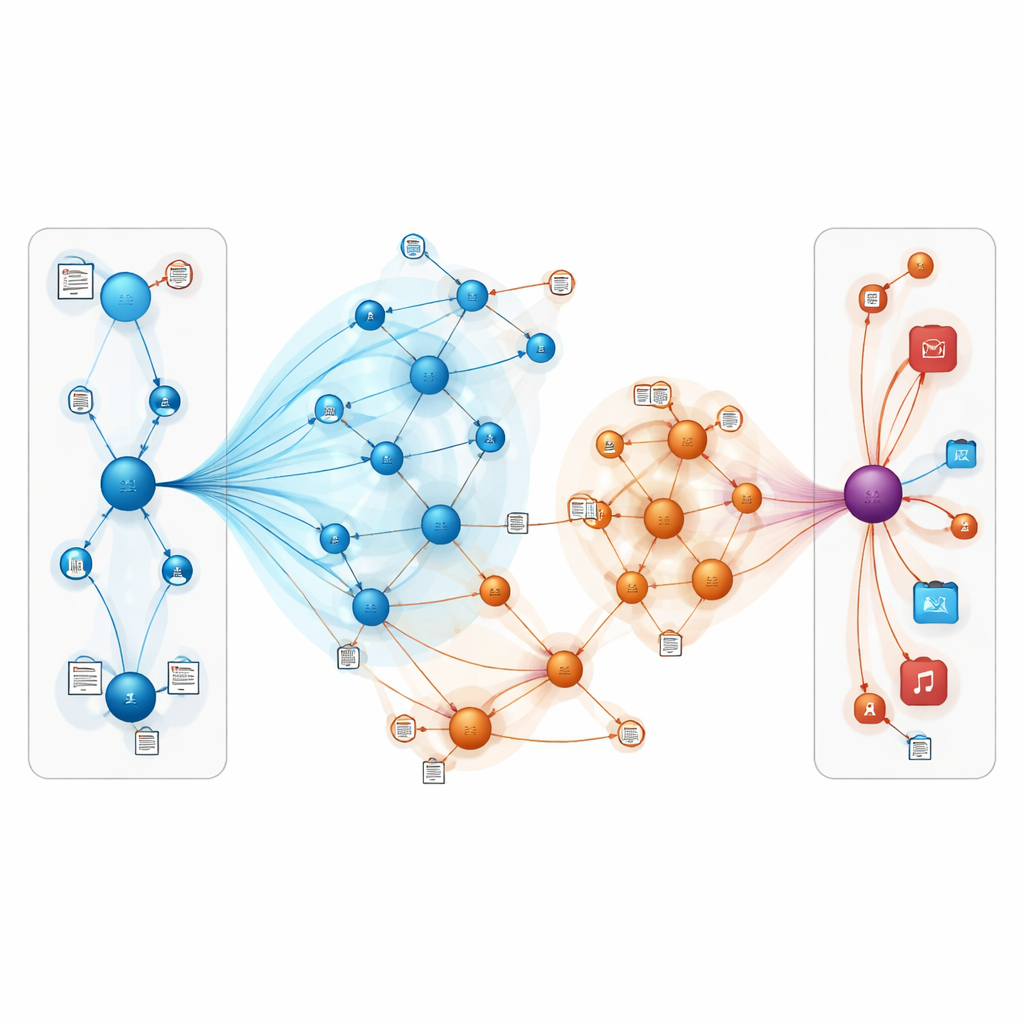
Vad det betyder för vardagsanvändare
Enkelt uttryckt visar detta arbete att rekommendationssystem kan bli mer precisa och motståndskraftiga genom att kombinera två idéer: att representera den digitala världen som ett sammankopplat nät av entiteter och att låta modellen ”läsa mellan raderna” i användarrecensioner och beskrivningar. Genom att noggrant fokusera uppmärksamheten på de mest relevanta kopplingarna och blanda in textuell mening kan TNRA bättre härleda vad människor sannolikt kommer att uppskatta, även när det finns få explicita signaler. För användare kan det innebära mer passande bok- och filmtips och färre irrelevanta listor, särskilt för nischade smaker och nya varor som traditionella metoder tenderar att förbise.
Citering: Dong, J., Shen, Z., Luo, H. et al. Graph attention and text semantics improve personalized recommendation. Sci Rep 16, 11672 (2026). https://doi.org/10.1038/s41598-026-46737-x
Nyckelord: personliga rekommendationer, kunskapsgraf, grafneuralt nätverk, textsemantik, rekommendationssystem