Clear Sky Science · en
Graph attention and text semantics improve personalized recommendation
Why smarter suggestions matter
Every time you open a shopping site, movie app, or online bookstore, you’re relying on algorithms to sift through a flood of options and surface a handful that might actually interest you. Yet these recommendation systems often struggle when there is little data about a user or an item, or when people’s tastes shift over time. This study introduces a new way to make recommendations that not only looks at who clicked what, but also reads the surrounding text—such as reviews and descriptions—and explores a web of related concepts to better guess what you will like next.
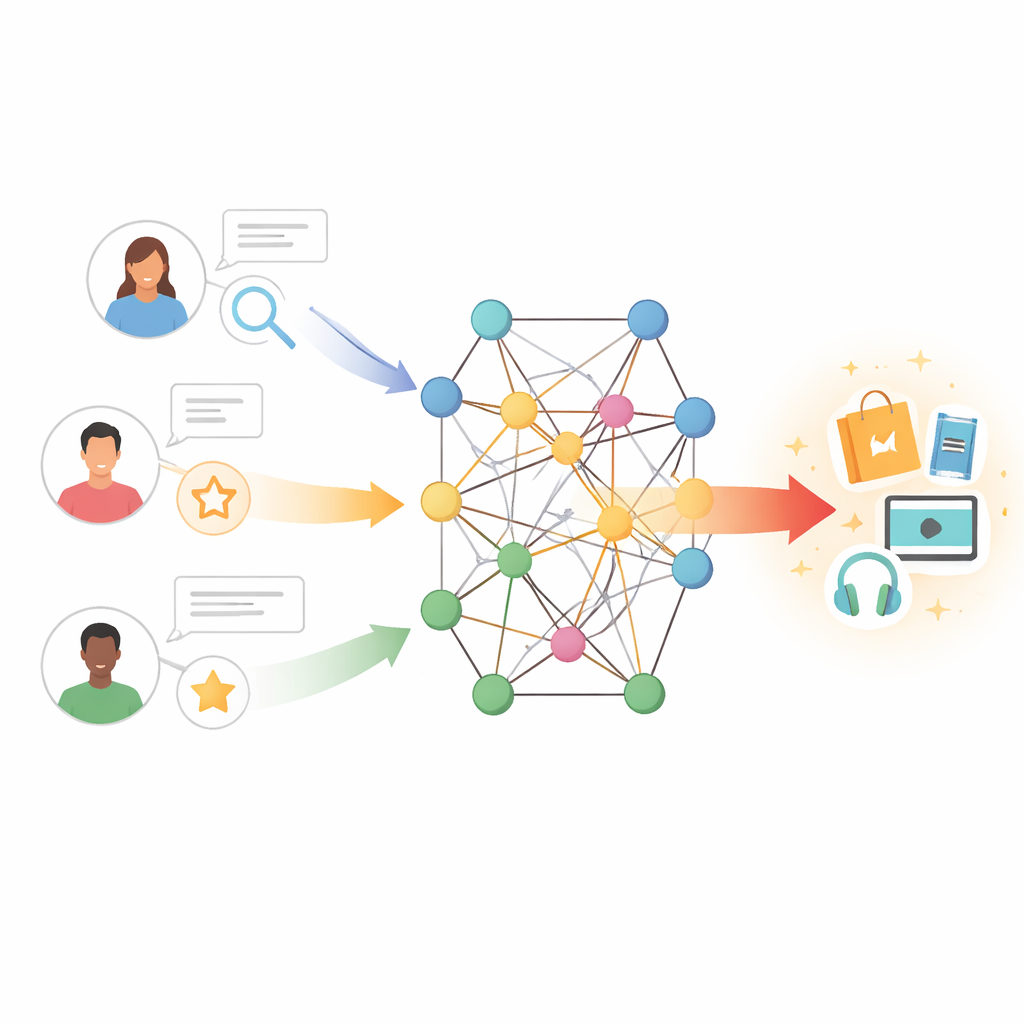
From simple matches to rich connections
Traditional recommendation tools work a bit like finding people with similar shopping or viewing histories and copying their choices. This approach, called collaborative filtering, relies on large tables of user–item interactions. When these tables are thin—because users are new, items are obscure, or feedback is scarce—the system quickly runs out of clues. Earlier attempts to fix this problem added text features: for instance, mining user reviews to capture opinions about storylines, writing styles, or actors. These methods helped, but they often treated all reviews as equally important and failed to model the subtle back-and-forth between a user’s tastes and an item’s characteristics.
Building a web of knowledge
The authors take a different tack by placing users and items inside a knowledge graph—a network where nodes can represent books, movies, authors, genres, and other entities, and edges encode their relationships. In this setting, indirect paths can reveal hidden preferences; for example, a user who likes several films connected to the same director or theme may also enjoy related works even if they have never rated them. However, naively exploring many steps in such a graph can introduce noise and high computational cost. The challenge is to let the model listen to the most informative neighbors in this network while ignoring misleading or distant connections.
Letting the model pay attention
The proposed model, called TNRA, tackles this by using graph attention networks on the user side and graph convolution on the item side. For users, the model traces multi-step “ripples” through the knowledge graph starting from the items they have interacted with, assigning higher weights to more relevant connections. This attention mechanism means that not all neighboring nodes influence the user profile equally; the system learns which paths matter most for predicting new interests. On the item side, the model samples a limited set of nearby nodes—such as related products or attributes—and blends their features to form a refined portrait of each item, again guided by how closely those neighbors align with a given user’s tastes.
Teaching the system to read
A key twist is that TNRA does not rely on graph structure alone. It also learns from the language in user reviews and item descriptions. After cleaning and tokenizing the text, the system turns sentences into compact vectors that capture meaning, such as enthusiasm for a particular genre or complaints about pacing. These text-derived vectors are fused with the graph-based representations of users and items, enriching each node with both structural connections and semantic nuance. When the system later compares a user and an item, it is effectively comparing their combined “stories” rather than just raw click histories.
Putting the approach to the test
The researchers evaluated TNRA on two well-known benchmarks: a large-scale book rating collection and the MovieLens-1M movie dataset, both enhanced with a commercial knowledge graph. They compared their approach to several strong baselines that use deep learning and graph methods. Across multiple measures—including how well the model distinguishes items a user engaged with from those they ignored, and how many relevant items appear in the top of the recommendation list—TNRA consistently came out ahead. It achieved slightly but meaningfully higher scores, especially in settings where data are sparse, and did so with training times and memory use comparable to other graph-based systems.
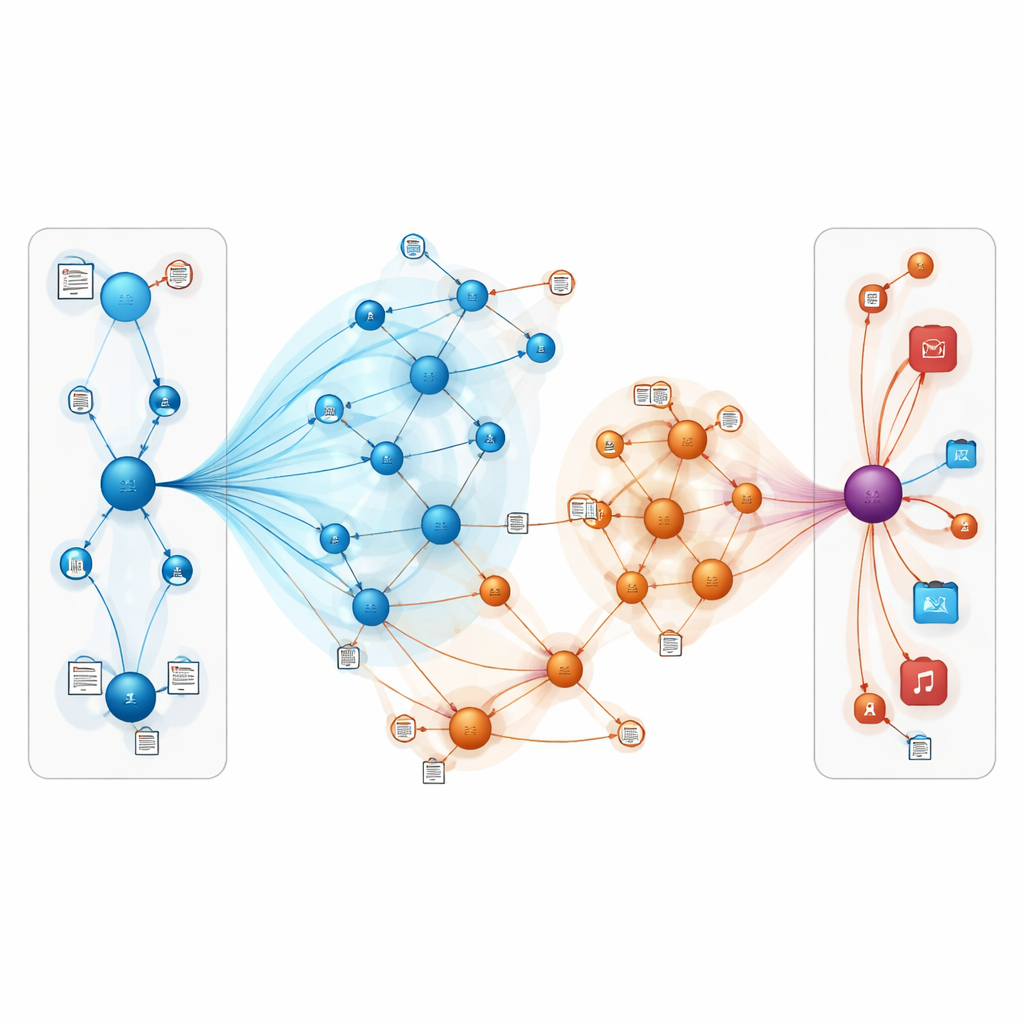
What this means for everyday users
In plain terms, this work shows that recommendation systems can become more accurate and resilient by combining two ideas: representing the online world as an interconnected web of entities, and letting the model “read between the lines” of user reviews and descriptions. By carefully focusing attention on the most relevant connections and blending in textual meaning, TNRA can better infer what people are likely to enjoy, even when there are few explicit signals. For users, that could translate into more fitting book and movie suggestions and fewer irrelevant lists, particularly for niche tastes and new items that traditional methods tend to overlook.
Citation: Dong, J., Shen, Z., Luo, H. et al. Graph attention and text semantics improve personalized recommendation. Sci Rep 16, 11672 (2026). https://doi.org/10.1038/s41598-026-46737-x
Keywords: personalized recommendation, knowledge graph, graph neural network, text semantics, recommender systems