Clear Sky Science · pt
Atenção em grafos e semântica de texto melhoram recomendações personalizadas
Por que sugestões mais inteligentes importam
Cada vez que você abre um site de compras, um aplicativo de filmes ou uma livraria online, depende de algoritmos para vasculhar um mar de opções e mostrar algumas que possam realmente interessar. Ainda assim, esses sistemas de recomendação frequentemente enfrentam dificuldades quando há poucos dados sobre um usuário ou um item, ou quando os gostos das pessoas mudam com o tempo. Este estudo apresenta uma nova forma de fazer recomendações que não só observa quem clicou no quê, mas também lê os textos ao redor — como avaliações e descrições — e explora uma teia de conceitos relacionados para adivinhar melhor o que você gostará em seguida.
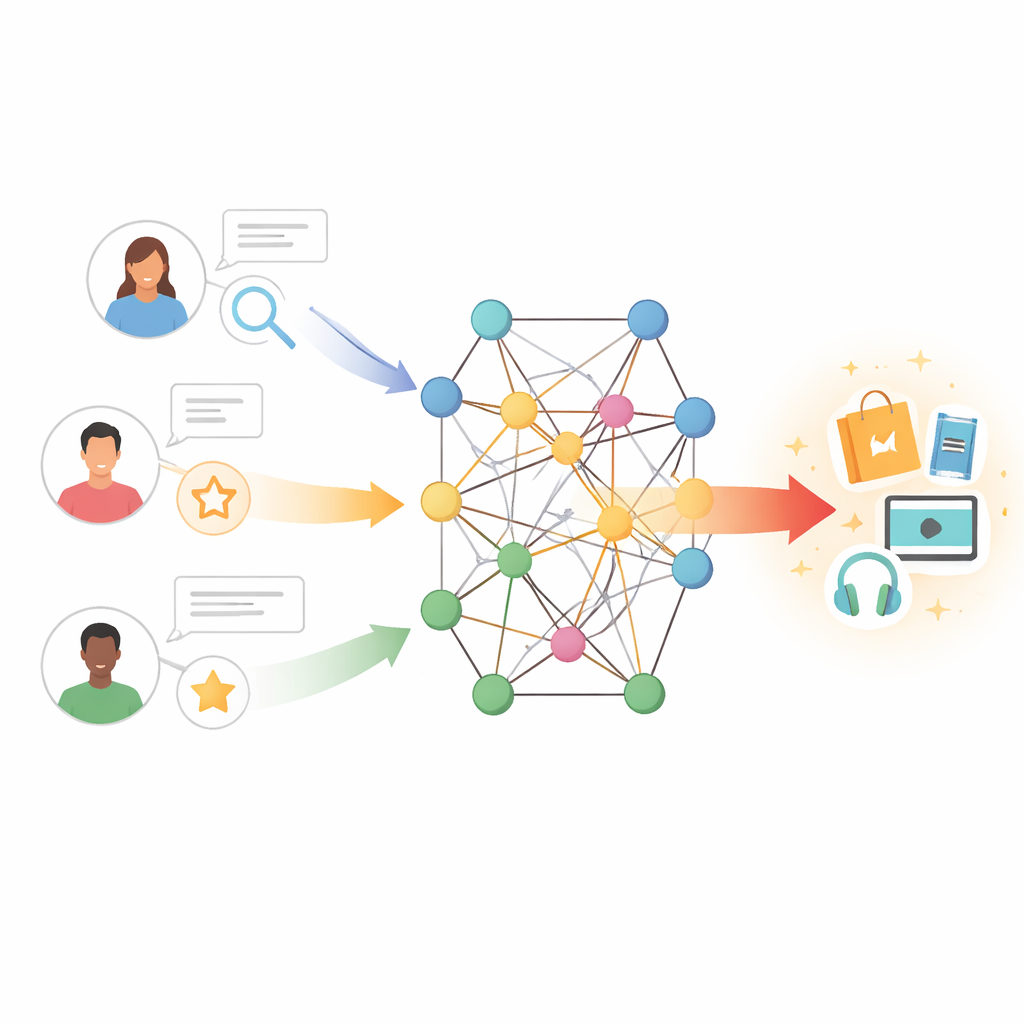
De correspondências simples a conexões ricas
As ferramentas tradicionais de recomendação funcionam um pouco como encontrar pessoas com históricos de compras ou visualização semelhantes e copiar suas escolhas. Essa abordagem, chamada filtragem colaborativa, depende de grandes tabelas de interações usuário–item. Quando essas tabelas são escassas — porque os usuários são novos, os itens são obscuros ou há pouco feedback — o sistema rapidamente fica sem pistas. Tentativas anteriores de resolver esse problema adicionaram recursos textuais: por exemplo, extrair opiniões de avaliações de usuários para captar impressões sobre enredos, estilos de escrita ou atores. Esses métodos ajudaram, mas muitas vezes trataram todas as avaliações como igualmente importantes e falharam em modelar o sutil vai-e-vem entre os gostos de um usuário e as características de um item.
Construindo uma teia de conhecimento
Os autores seguem outro caminho ao colocar usuários e itens dentro de um grafo de conhecimento — uma rede onde nós podem representar livros, filmes, autores, gêneros e outras entidades, e arestas codificam suas relações. Nesse cenário, caminhos indiretos podem revelar preferências ocultas; por exemplo, um usuário que gosta de vários filmes conectados ao mesmo diretor ou tema pode também apreciar obras relacionadas mesmo que nunca as tenha avaliado. Contudo, explorar ingênua e extensivamente muitos passos em tal grafo pode introduzir ruído e alto custo computacional. O desafio é permitir que o modelo atente para os vizinhos mais informativos nessa rede, ignorando conexões enganosas ou distantes.
Deixando o modelo prestar atenção
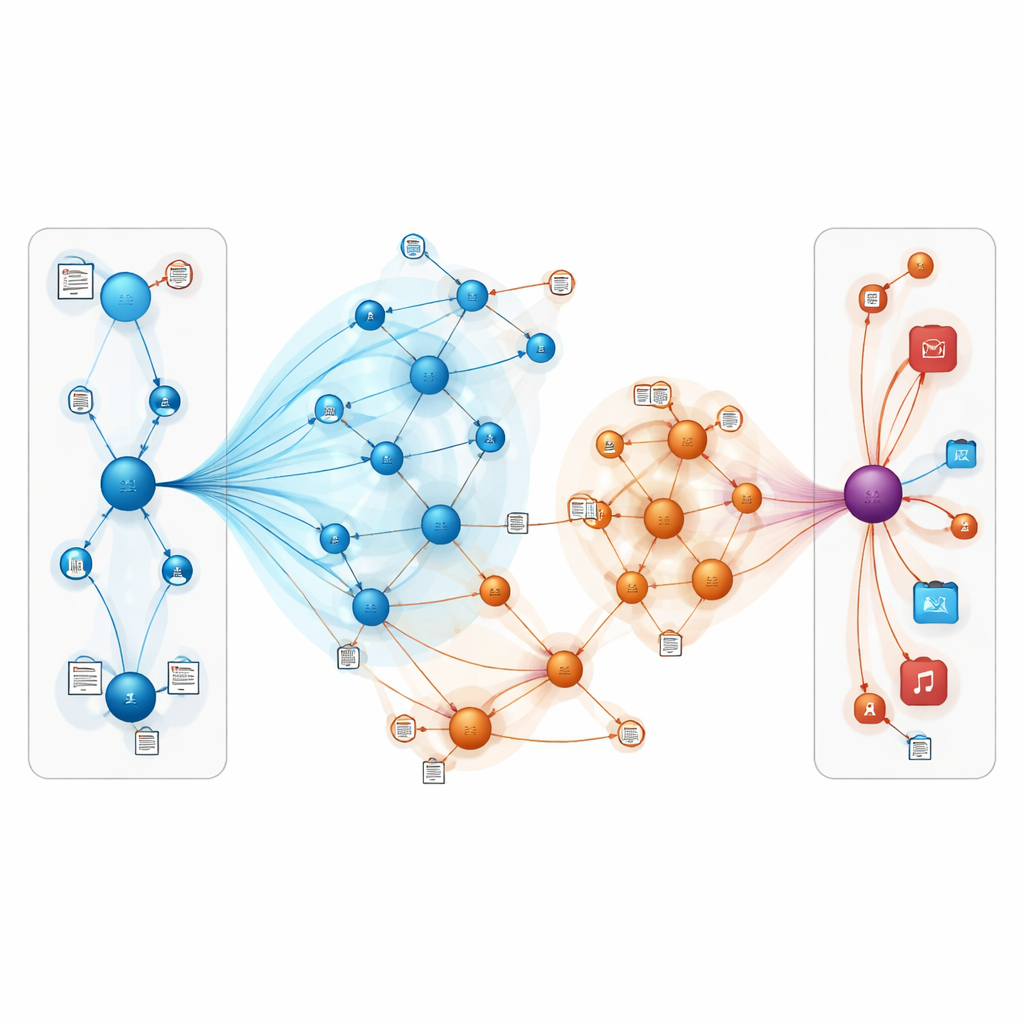
O modelo proposto, chamado TNRA, lida com isso usando redes de atenção em grafos no lado do usuário e convolução em grafos no lado do item. Para usuários, o modelo traça “ondulações” multi-etapas através do grafo de conhecimento a partir dos itens com os quais eles interagiram, atribuindo pesos maiores às conexões mais relevantes. Esse mecanismo de atenção significa que nem todos os nós vizinhos influenciam o perfil do usuário igualmente; o sistema aprende quais caminhos são mais importantes para prever novos interesses. No lado do item, o modelo amostra um conjunto limitado de nós próximos — como produtos relacionados ou atributos — e mistura suas características para formar um retrato refinado de cada item, novamente guiado por quão bem esses vizinhos se alinham aos gostos de um usuário específico.
Ensinando o sistema a ler
Um diferencial importante é que o TNRA não depende apenas da estrutura do grafo. Ele também aprende a partir da linguagem em avaliações de usuários e descrições de itens. Após limpar e tokenizar o texto, o sistema transforma sentenças em vetores compactos que capturam significado, como entusiasmo por um gênero específico ou reclamações sobre ritmo. Esses vetores derivados do texto são fundidos com as representações baseadas no grafo de usuários e itens, enriquecendo cada nó com conexões estruturais e nuances semânticas. Quando o sistema depois compara um usuário e um item, ele está efetivamente comparando suas “histórias” combinadas em vez de apenas históricos brutos de cliques.
Colocando a abordagem à prova
Os pesquisadores avaliaram o TNRA em dois benchmarks conhecidos: uma grande coleção de avaliações de livros e o conjunto de filmes MovieLens-1M, ambos enriquecidos com um grafo de conhecimento comercial. Eles compararam sua abordagem com várias linhas de base fortes que usam aprendizado profundo e métodos baseados em grafos. Em múltiplas medidas — incluindo quão bem o modelo distingue itens com os quais um usuário interagiu daqueles que ignorou, e quantos itens relevantes aparecem no topo da lista de recomendações — o TNRA saiu consistentemente na frente. Alcançou pontuações ligeiramente, mas de forma significativa, melhores, especialmente em cenários com dados esparsos, e fez isso com tempos de treinamento e uso de memória comparáveis a outros sistemas baseados em grafos.
O que isso significa para usuários do dia a dia
Em termos simples, este trabalho mostra que sistemas de recomendação podem se tornar mais precisos e resilientes ao combinar duas ideias: representar o mundo online como uma teia interconectada de entidades e permitir que o modelo “leia nas entrelinhas” de avaliações e descrições. Ao focar cuidadosamente a atenção nas conexões mais relevantes e incorporar o significado textual, o TNRA pode inferir melhor o que as pessoas provavelmente vão gostar, mesmo quando há poucos sinais explícitos. Para os usuários, isso pode se traduzir em sugestões de livros e filmes mais adequadas e listas menos irrelevantes, especialmente para gostos de nicho e itens novos que os métodos tradicionais tendem a negligenciar.
Citação: Dong, J., Shen, Z., Luo, H. et al. Graph attention and text semantics improve personalized recommendation. Sci Rep 16, 11672 (2026). https://doi.org/10.1038/s41598-026-46737-x
Palavras-chave: recomendação personalizada, grafo de conhecimento, rede neural em grafos, semântica de texto, sistemas de recomendação