Clear Sky Science · nl
Graf-attentie en tekstsemantiek verbeteren gepersonaliseerde aanbevelingen
Waarom slimmer voorstellen ertoe doen
Elke keer dat je een winkelwebsite, film-app of online boekwinkel opent, vertrouw je op algoritmen die een zee van opties doorspitten en een handvol naar boven halen dat je mogelijk interesseert. Toch hebben deze aanbevelingssystemen vaak moeite wanneer er weinig gegevens zijn over een gebruiker of een item, of wanneer iemands smaak in de loop van de tijd verandert. Deze studie introduceert een nieuwe manier om aanbevelingen te doen die niet alleen kijkt naar wie waarop heeft geklikt, maar ook de omliggende tekst leest—zoals beoordelingen en beschrijvingen—en een web van gerelateerde concepten doorzoekt om beter te raden wat je hierna leuk zult vinden.
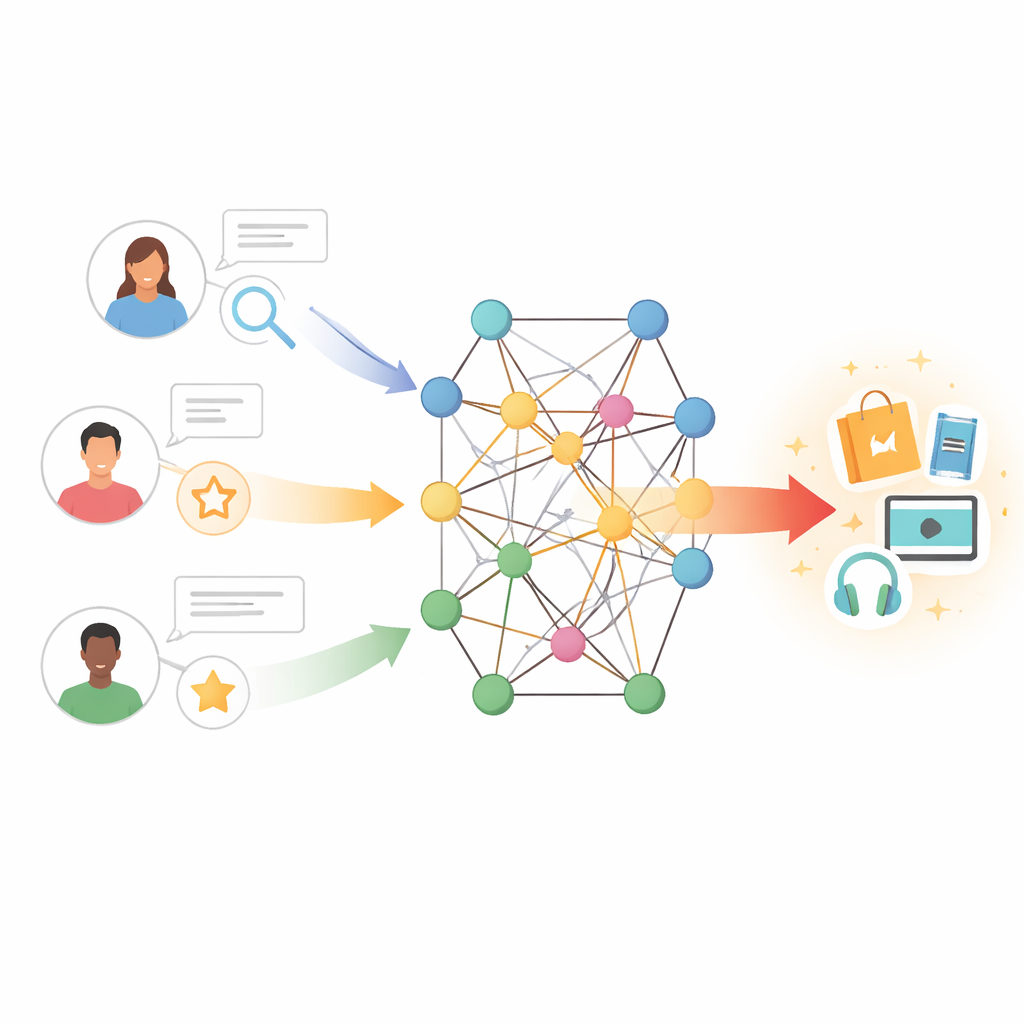
Van eenvoudige overeenkomsten naar rijke verbindingen
Traditionele aanbevelingsmethoden werken een beetje als het vinden van mensen met vergelijkbare koop- of kijkgeschiedenissen en het kopiëren van hun keuzes. Deze aanpak, collaborative filtering genoemd, steunt op grote tabellen met gebruiker–item-interacties. Wanneer die tabellen schaars zijn—omdat gebruikers nieuw zijn, items onbekend zijn of feedback beperkt is—raakt het systeem snel zonder aanwijzingen. Eerdere pogingen om dit probleem op te lossen voegden tekstkenmerken toe: bijvoorbeeld het winnen van informatie uit gebruikersrecensies om meningen over verhaallijnen, schrijfstijl of acteurs vast te leggen. Deze methoden hielpen, maar behandelden vaak alle recensies als even belangrijk en faalden erin de subtiele wisselwerking tussen de smaak van een gebruiker en de eigenschappen van een item te modelleren.
Het opbouwen van een kennissenweb
De auteurs kiezen een andere benadering door gebruikers en items binnen een kennisgrafiek te plaatsen—een netwerk waarbij knopen boeken, films, auteurs, genres en andere entiteiten kunnen vertegenwoordigen, en randen hun relaties coderen. In deze setting kunnen indirecte paden verborgen voorkeuren onthullen; bijvoorbeeld, een gebruiker die van meerdere films houdt die met dezelfde regisseur of thema verbonden zijn, kan ook verwante werken waarderen, zelfs als hij ze nooit heeft beoordeeld. Echter, het naïef verkennen van vele stappen in zo’n grafiek kan ruis en hoge rekenkosten introduceren. De uitdaging is het model te laten luisteren naar de meest informatieve buren in dit netwerk en misleidende of verre verbindingen te negeren.
Het model laten opletten
Het voorgestelde model, TNRA genoemd, pakt dit aan door graf-attentienetwerken aan de gebruikerszijde en grafconvolutie aan de itemzijde te gebruiken. Voor gebruikers volgt het model meerstaps "rimpels" door de kennisgrafiek, beginnend bij de items waarmee ze hebben geïnterageerd, en kent hogere gewichten toe aan meer relevante verbindingen. Deze aandachtmechanisme betekent dat niet alle nabije knopen evenveel invloed hebben op het gebruikersprofiel; het systeem leert welke paden het belangrijkst zijn om nieuwe interesses te voorspellen. Aan de itemzijde sampelt het model een beperkte set nabijgelegen knopen—zoals gerelateerde producten of attributen—en mengt hun kenmerken om een verfijnd beeld van elk item te vormen, opnieuw geleid door hoe goed die buren aansluiten bij de smaak van een bepaalde gebruiker.
Het systeem leren lezen
Een belangrijk element is dat TNRA niet alleen op grafstructuur vertrouwt. Het leert ook van de taal in gebruikersrecensies en itembeschrijvingen. Na het opschonen en tokenizen van de tekst zet het systeem zinnen om in compacte vectoren die betekenis vastleggen, zoals enthousiasme voor een bepaald genre of klachten over tempo. Deze tekstgebaseerde vectoren worden samengevoegd met de grafgebaseerde representaties van gebruikers en items, waardoor elke knoop zowel structurele verbindingen als semantische nuance krijgt. Wanneer het systeem later een gebruiker en een item vergelijkt, vergelijkt het in feite hun gecombineerde "verhalen" in plaats van alleen ruwe klikgeschiedenissen.
De aanpak op de proef gesteld
De onderzoekers evalueerden TNRA op twee bekende benchmarks: een grootschalige dataset met boekbeoordelingen en de MovieLens-1M filmdataset, beide verrijkt met een commerciële kennisgrafiek. Ze vergeleken hun aanpak met meerdere sterke baselines die deep learning en grafmethoden gebruiken. Over meerdere maten heen—waaronder hoe goed het model onderscheid maakt tussen items waarmee een gebruiker interactie had en items die ze negeerden, en hoeveel relevante items bovenaan de aanbevelingslijst verschijnen—kwam TNRA consequent als winnaar uit de bus. Het behaalde licht maar betekenisvol hogere scores, vooral in situaties waar gegevens schaars zijn, en deed dat met trainingstijden en geheugenverbruik vergelijkbaar met andere grafgebaseerde systemen.
Wat dit betekent voor dagelijkse gebruikers
Simpel gezegd toont dit werk aan dat aanbevelingssystemen accurater en veerkrachtiger kunnen worden door twee ideeën te combineren: het online domein voorstellen als een onderling verbonden web van entiteiten, en het model laten "tussen de regels door lezen" in gebruikersrecensies en beschrijvingen. Door zorgvuldig aandacht te richten op de meest relevante verbindingen en tekstuele betekenis mee te wegen, kan TNRA beter afleiden wat mensen waarschijnlijk prettig vinden, zelfs wanneer er weinig expliciete signalen zijn. Voor gebruikers kan dat vertalen naar beter passende boek- en filmaanbevelingen en minder irrelevante lijsten, met name voor nichezinnen en nieuwe items die traditionele methoden geneigd zijn over het hoofd te zien.
Bronvermelding: Dong, J., Shen, Z., Luo, H. et al. Graph attention and text semantics improve personalized recommendation. Sci Rep 16, 11672 (2026). https://doi.org/10.1038/s41598-026-46737-x
Trefwoorden: gepersonaliseerde aanbeveling, kennisgrafiek, graf-neuraal netwerk, tekstsemantiek, aanbevelingssystemen