Clear Sky Science · de
Graph-Aufmerksamkeit und Textsemantik verbessern personalisierte Empfehlungen
Warum intelligentere Vorschläge wichtig sind
Jedes Mal, wenn Sie eine Shopping-Seite, eine Film‑App oder einen Online‑Buchladen öffnen, verlassen Sie sich auf Algorithmen, die aus einer Flut von Optionen einige wenige herausfiltern, die Sie interessieren könnten. Diese Empfehlungssysteme geraten jedoch oft an ihre Grenzen, wenn nur wenige Daten über einen Nutzer oder ein Produkt vorliegen oder sich die Vorlieben der Menschen im Laufe der Zeit ändern. Die vorliegende Studie stellt einen neuen Ansatz vor, der nicht nur betrachtet, wer worauf geklickt hat, sondern auch die umgebenden Texte – etwa Bewertungen und Beschreibungen – liest und ein Netz verwandter Konzepte erkundet, um besser vorherzusagen, was Ihnen als Nächstes gefallen könnte.
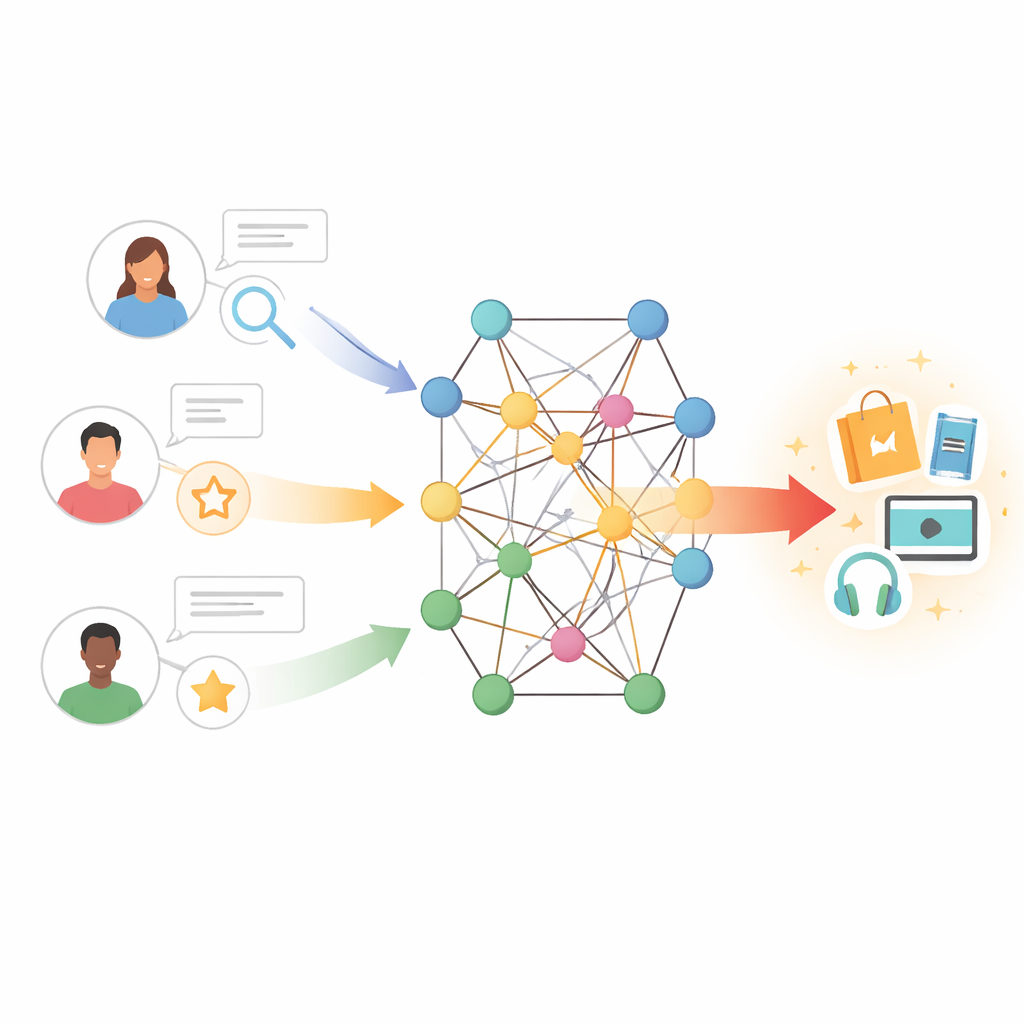
Von einfachen Übereinstimmungen zu reichen Verbindungen
Traditionelle Empfehlungstools funktionieren ein wenig so, als würde man Personen mit ähnlichen Einkaufs‑ oder Sehgewohnheiten finden und deren Entscheidungen kopieren. Dieser Ansatz, bekannt als Collaborative Filtering, stützt sich auf große Tabellen von Nutzer‑Item‑Interaktionen. Wenn diese Tabellen dünn sind – weil Nutzer neu sind, Artikel wenig bekannt oder Rückmeldungen spärlich sind – gehen dem System schnell die Anhaltspunkte aus. Frühere Versuche, dieses Problem zu beheben, ergänzten Textmerkmale: zum Beispiel durch Auswertung von Nutzerbewertungen, um Meinungen zu Handlungsverläufen, Schreibstilen oder Schauspielern zu erfassen. Diese Methoden halfen, aber sie behandelten oft alle Bewertungen als gleich wichtig und konnten das subtile Wechselspiel zwischen den Vorlieben eines Nutzers und den Eigenschaften eines Items nicht hinreichend modellieren.
Ein Netz des Wissens aufbauen
Die Autoren verfolgen einen anderen Weg, indem sie Nutzer und Items in einen Wissensgraphen einbetten – ein Netzwerk, in dem Knoten Bücher, Filme, Autoren, Genres und andere Entitäten repräsentieren können und Kanten ihre Beziehungen kodieren. In diesem Rahmen können indirekte Pfade verborgene Präferenzen offenbaren; zum Beispiel könnte ein Nutzer, der mehrere Filme mag, die mit demselben Regisseur oder Thema verbunden sind, auch verwandte Werke schätzen, selbst wenn er diese nie bewertet hat. Allerdings kann das naive Erkunden vieler Schritte in einem solchen Graphen Rauschen und hohe Rechenkosten einführen. Die Herausforderung besteht darin, das Modell die informativsten Nachbarn in diesem Netzwerk „zuhören“ zu lassen und irreführende oder weit entfernte Verbindungen zu ignorieren.
Das Modell aufmerksam machen
Das vorgeschlagene Modell, TNRA genannt, begegnet diesem Problem, indem es auf der Nutzerseite Graph‑Attention‑Netzwerke und auf der Itemseite Graph‑Convolution einsetzt. Für Nutzer verfolgt das Modell mehrstufige „Wellen“ durch den Wissensgraphen ausgehend von den Items, mit denen sie interagiert haben, und weist relevanteren Verbindungen höhere Gewichte zu. Dieser Aufmerksamkeitsmechanismus bedeutet, dass nicht alle benachbarten Knoten gleichermaßen das Nutzerprofil beeinflussen; das System lernt, welche Pfade für die Vorhersage neuer Interessen am wichtigsten sind. Auf der Itemseite sampelt das Modell eine begrenzte Menge naheliegender Knoten – etwa verwandte Produkte oder Attribute – und verschmilzt deren Merkmale zu einem verfeinerten Porträt jedes Items, wiederum gesteuert davon, wie gut diese Nachbarn mit den Vorlieben eines bestimmten Nutzers übereinstimmen.
Dem System das Lesen beibringen
Ein zentraler Dreh ist, dass TNRA sich nicht allein auf die Graphstruktur verlässt. Es lernt auch aus der Sprache in Nutzerbewertungen und Item‑Beschreibungen. Nach der Bereinigung und Tokenisierung des Textes wandelt das System Sätze in kompakte Vektoren um, die Bedeutung erfassen – etwa Begeisterung für ein bestimmtes Genre oder Kritik am Tempo. Diese aus Text gewonnenen Vektoren werden mit den graphbasierten Repräsentationen von Nutzern und Items verschmolzen und bereichern jeden Knoten sowohl mit strukturellen Verbindungen als auch mit semantischer Nuance. Wenn das System später einen Nutzer und ein Item vergleicht, vergleicht es effektiv deren kombinierte „Geschichten“ statt nur rohe Klick‑Historien.
Den Ansatz auf die Probe stellen
Die Forschenden evaluierten TNRA an zwei bekannten Benchmarks: einer großskaligen Sammlung von Buchbewertungen und dem MovieLens‑1M‑Film‑Datensatz, beide angereichert mit einem kommerziellen Wissensgraphen. Sie verglichen ihren Ansatz mit mehreren starken Baselines, die Deep‑Learning‑ und Graph‑Methoden verwenden. Über mehrere Messgrößen hinweg – darunter wie gut das Modell Items unterscheidet, mit denen ein Nutzer interagiert hat, von solchen, die er ignoriert hat, und wie viele relevante Items oben in der Empfehlungsliste erscheinen – lag TNRA durchgängig vorn. Es erzielte leicht, aber bedeutsam höhere Werte, besonders in Szenarien mit spärlichen Daten, und das bei Trainingszeiten und Speicherbedarf, die mit anderen graphbasierten Systemen vergleichbar sind.
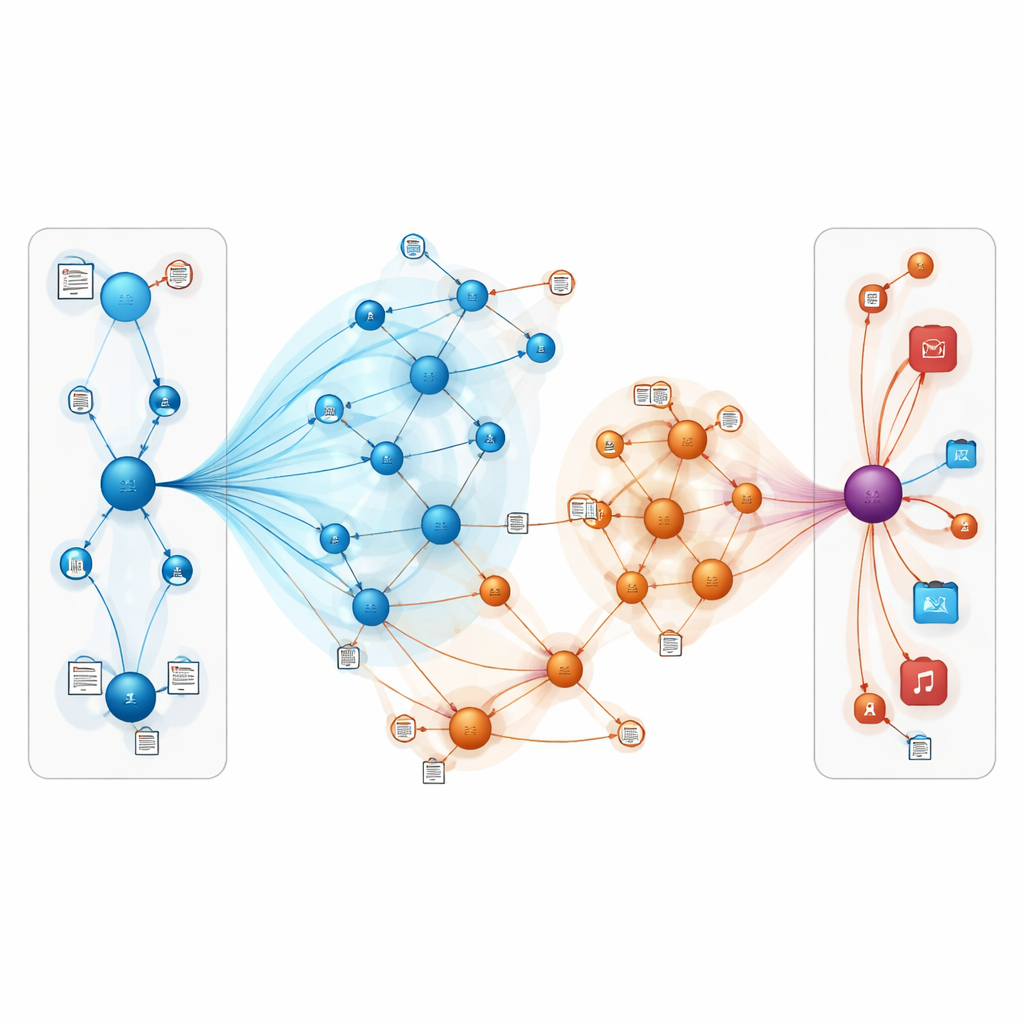
Was das für Alltagsnutzer bedeutet
Einfach gesagt zeigt diese Arbeit, dass Empfehlungssysteme genauer und robuster werden können, wenn man zwei Ideen kombiniert: die Online‑Welt als ein miteinander vernetztes Geflecht von Entitäten darzustellen und dem Modell zu erlauben, „zwischen den Zeilen“ von Nutzerbewertungen und Beschreibungen zu lesen. Indem die Aufmerksamkeit sorgfältig auf die relevantesten Verbindungen gelenkt und textliche Bedeutung einbezogen wird, kann TNRA besser erschließen, was Menschen wahrscheinlich gefallen wird, selbst wenn nur wenige explizite Signale vorliegen. Für Nutzer könnte das bedeuten: passenderere Buch‑ und Filmvorschläge und weniger irrelevante Listen, insbesondere bei Nischengeschmäckern und neuen Items, die traditionelle Methoden oft übersehen.
Zitation: Dong, J., Shen, Z., Luo, H. et al. Graph attention and text semantics improve personalized recommendation. Sci Rep 16, 11672 (2026). https://doi.org/10.1038/s41598-026-46737-x
Schlüsselwörter: personalisierte Empfehlung, Wissensgraph, Graph-Neuronales Netzwerk, Textsemantik, Empfehlungssysteme