Clear Sky Science · es
La atención en grafos y la semántica del texto mejoran la recomendación personalizada
Por qué importan las sugerencias más inteligentes
Cada vez que abres una tienda en línea, una app de películas o una librería digital, confías en algoritmos que filtran un aluvión de opciones y sacan a la superficie unas pocas que podrían interesarte. Sin embargo, estos sistemas de recomendación suelen fallar cuando hay pocos datos sobre un usuario o un ítem, o cuando los gustos de las personas cambian con el tiempo. Este estudio presenta una nueva forma de hacer recomendaciones que no solo mira quién hizo clic en qué, sino que también lee el texto circundante—como reseñas y descripciones—y explora una red de conceptos relacionados para adivinar mejor qué te gustará a continuación.
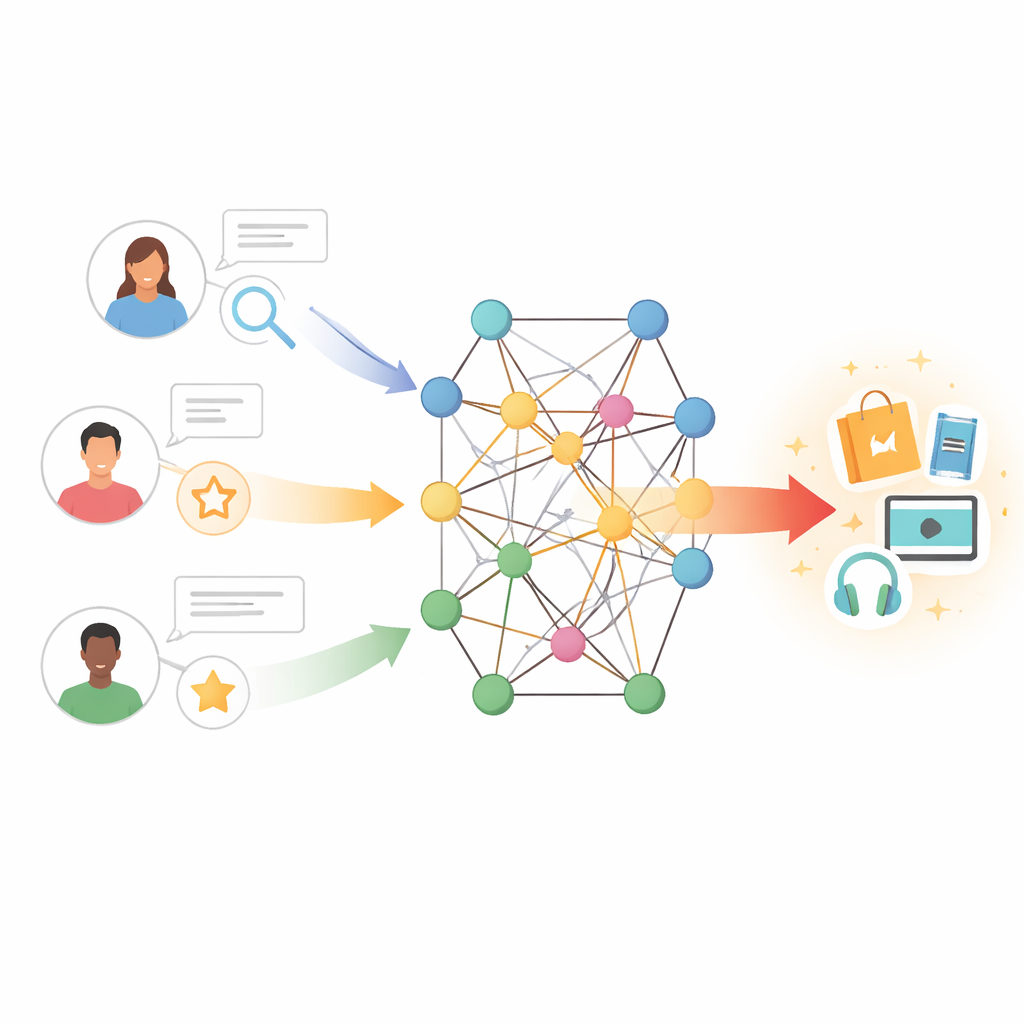
De coincidencias simples a conexiones ricas
Las herramientas de recomendación tradicionales funcionan un poco como encontrar personas con historiales de compra o visualización similares y copiar sus elecciones. Este enfoque, llamado filtrado colaborativo, se basa en grandes tablas de interacciones usuario–ítem. Cuando estas tablas son escasas—porque los usuarios son nuevos, los ítems son poco conocidos o la retroalimentación es limitada—el sistema se queda rápidamente sin pistas. Intentos anteriores para solucionar este problema incorporaron características de texto: por ejemplo, extraer información de las reseñas de usuarios para capturar opiniones sobre tramas, estilos de escritura o actores. Estos métodos ayudaron, pero a menudo trataban todas las reseñas como igualmente importantes y no lograban modelar el sutil vaivén entre los gustos de un usuario y las características de un ítem.
Construyendo una red de conocimiento
Los autores adoptan una estrategia distinta al situar usuarios e ítems dentro de un grafo de conocimiento—una red donde los nodos pueden representar libros, películas, autores, géneros y otras entidades, y las aristas codifican sus relaciones. En este contexto, rutas indirectas pueden revelar preferencias ocultas; por ejemplo, un usuario que disfruta de varias películas conectadas al mismo director o tema también puede apreciar obras relacionadas aunque nunca las haya valorado. Sin embargo, explorar ingenuamente muchos pasos en dicho grafo puede introducir ruido y un coste computacional elevado. El reto es permitir que el modelo atienda a los vecinos más informativos de esta red mientras ignora conexiones engañosas o lejanas.
Permitiendo que el modelo preste atención
El modelo propuesto, llamado TNRA, aborda esto usando redes de atención en grafos en el lado del usuario y convolución en grafos en el lado del ítem. Para los usuarios, el modelo traza “ondas” multietapa a través del grafo de conocimiento partiendo de los ítems con los que han interactuado, asignando pesos mayores a las conexiones más relevantes. Este mecanismo de atención significa que no todos los nodos vecinos influyen por igual en el perfil del usuario; el sistema aprende qué rutas son las más importantes para predecir nuevos intereses. En el lado del ítem, el modelo muestrea un conjunto limitado de nodos cercanos—como productos relacionados o atributos—y mezcla sus características para formar un retrato refinado de cada ítem, de nuevo guiado por lo bien que esos vecinos se alinean con los gustos de un usuario dado.
Enseñando al sistema a leer
Un giro clave es que TNRA no depende solo de la estructura del grafo. También aprende del lenguaje en las reseñas de usuarios y las descripciones de ítems. Tras limpiar y tokenizar el texto, el sistema convierte oraciones en vectores compactos que capturan significado, como entusiasmo por un género concreto o quejas sobre el ritmo. Estos vectores derivados del texto se fusionan con las representaciones basadas en el grafo de usuarios e ítems, enriqueciendo cada nodo con conexiones estructurales y matices semánticos. Cuando el sistema compara después un usuario y un ítem, en realidad está comparando sus “historias” combinadas en lugar de solo historiales de clics en bruto.
Poniendo a prueba el enfoque
Los investigadores evaluaron TNRA en dos benchmarks bien conocidos: una colección a gran escala de valoraciones de libros y el conjunto de datos MovieLens-1M, ambos ampliados con un grafo de conocimiento comercial. Compararon su enfoque con varias líneas base sólidas que usan aprendizaje profundo y métodos en grafos. En múltiples medidas—incluyendo qué tan bien el modelo distingue ítems con los que un usuario interactuó de aquellos que ignoró y cuántos ítems relevantes aparecen en la parte superior de la lista de recomendación—TNRA superó consistentemente a las alternativas. Logró puntuaciones algo pero significativamente superiores, sobre todo en escenarios con datos escasos, y lo hizo con tiempos de entrenamiento y uso de memoria comparables a otros sistemas basados en grafos.
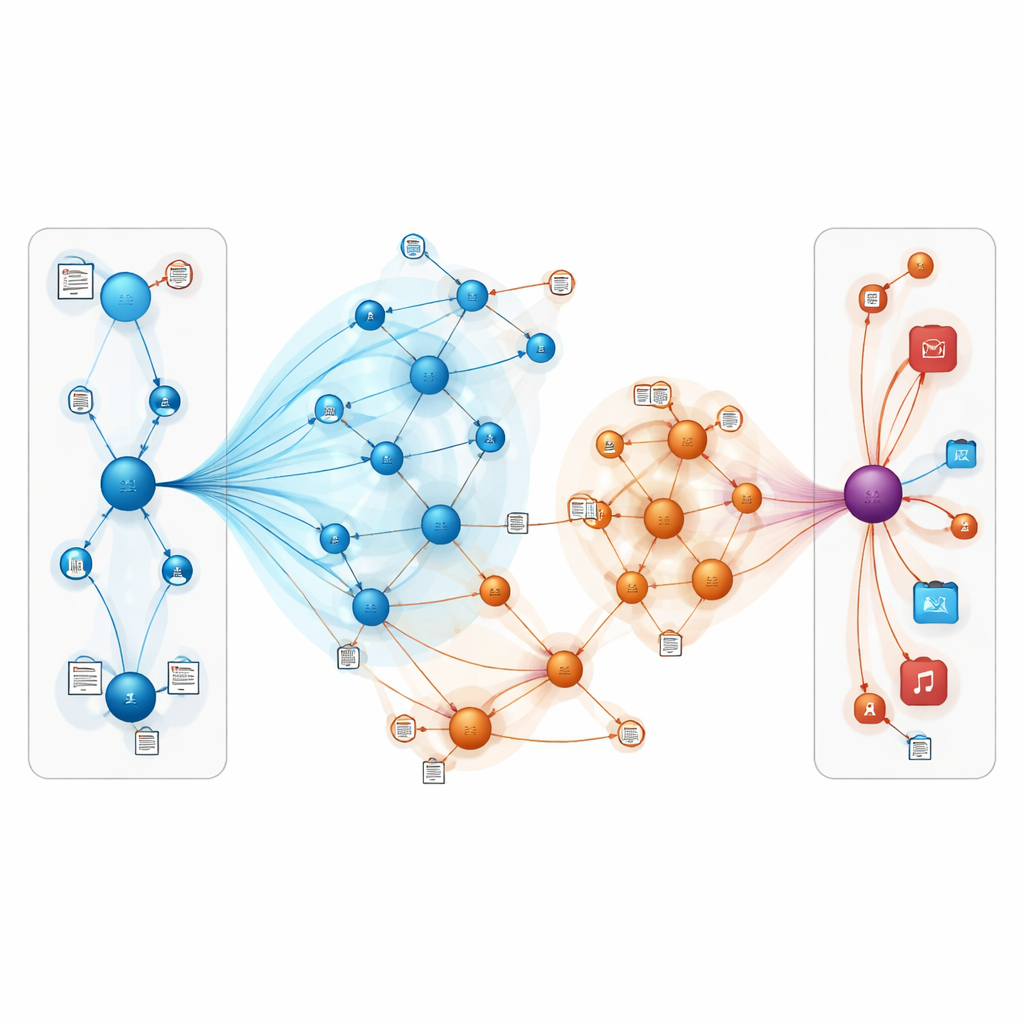
Qué significa esto para los usuarios cotidianos
En términos sencillos, este trabajo muestra que los sistemas de recomendación pueden volverse más precisos y resistentes combinando dos ideas: representar el mundo en línea como una red interconectada de entidades y permitir que el modelo “lea entre líneas” de las reseñas y descripciones. Al centrar cuidadosamente la atención en las conexiones más relevantes e incorporar el significado textual, TNRA puede inferir mejor lo que es probable que disfruten las personas, incluso cuando hay pocas señales explícitas. Para los usuarios, eso puede traducirse en sugerencias de libros y películas más adecuadas y en menos listas irrelevantes, especialmente para gustos nicho y nuevos ítems que los métodos tradicionales tienden a pasar por alto.
Cita: Dong, J., Shen, Z., Luo, H. et al. Graph attention and text semantics improve personalized recommendation. Sci Rep 16, 11672 (2026). https://doi.org/10.1038/s41598-026-46737-x
Palabras clave: recomendación personalizada, grafo de conocimiento, red neuronal de grafos, semántica del texto, sistemas de recomendación