Clear Sky Science · tr
Graf dikkat mekanizmaları ve metin anlambilimi kişiselleştirilmiş önerileri iyileştiriyor
Daha akıllı öneriler neden önemli
Her alışveriş sitesini, film uygulamasını veya çevrimiçi kitapçıyı açtığınızda, ilgilenebileceğiniz birkaç seçeneği ortaya çıkarmak için algoritmaların bir seçenek selini elemesinden beklenti içindesiniz. Yine de bu öneri sistemleri, bir kullanıcı veya öğe hakkında az veri olduğunda ya da insanların zevkleri zaman içinde değiştiğinde sık sık zorlanır. Bu çalışma, yalnızca kim neyi tıkladığına bakmakla kalmayıp, incelemeler ve açıklamalar gibi çevresel metni de okuyan ve gelecekte neyi sevebileceğinizi daha iyi tahmin etmek için ilişkili kavramlar ağına bakan yeni bir öneri yolunu sunuyor.
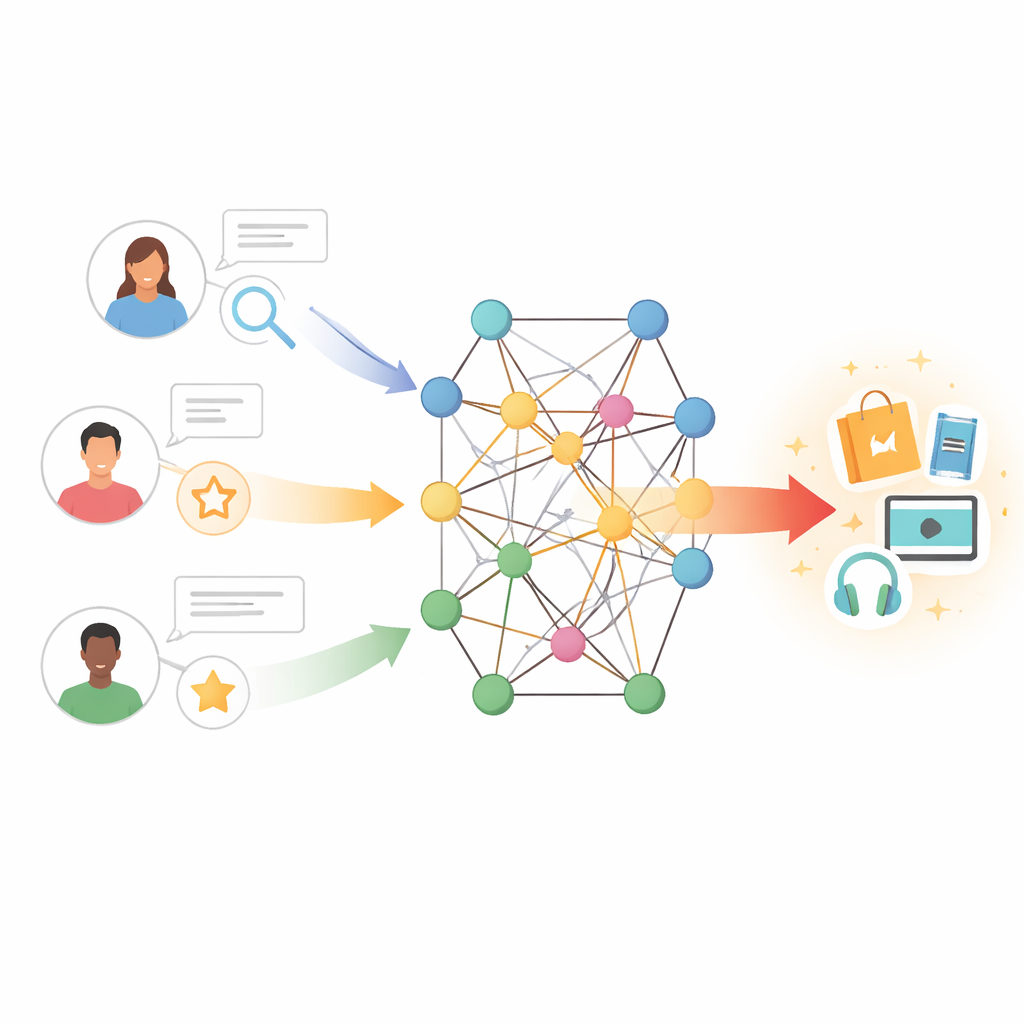
Basit eşleşmelerden zengin bağlantılara
Geleneksel öneri araçları, benzer alışveriş veya izleme geçmişine sahip insanları bulup onların tercihlerini kopyalamaya benzeyen bir şekilde çalışır. İşbirlikçi filtreleme olarak adlandırılan bu yaklaşım, kullanıcı–öğe etkileşimlerinin geniş tablolarına dayanır. Bu tablolar seyrek olduğunda—çünkü kullanıcılar yeniyse, öğeler bilinmiyorsa veya geri bildirim azsa—sistem çabucak ipuçlarını yitirebilir. Bu sorunu çözmek için yapılan önceki girişimler metin özellikleri ekledi: örneğin, hikâye, yazım stili veya oyuncular hakkındaki görüşleri yakalamak için kullanıcı yorumlarını madencilik yapmak. Bu yöntemler yardımcı oldu, ancak genellikle tüm yorumları eşit önemde saydı ve bir kullanıcının zevkleri ile bir öğenin özellikleri arasındaki ince etkileşimi modelleyemedi.
Bir bilgi ağı inşa etmek
Yazarlar, kullanıcıları ve öğeleri kitaplar, filmler, yazarlar, türler ve diğer varlıkları temsil edebilen düğümlerin bulunduğu ve kenarların ilişkileri kodladığı bir bilgi grafiği içine yerleştirerek farklı bir yol izliyor. Bu ortamda, dolaylı yollar gizli tercihleri açığa çıkarabilir; örneğin, aynı yönetmene veya temaya bağlı birkaç filmi seven bir kullanıcı, onları değerlendirmemiş olsa bile ilişkili eserlerden hoşlanabilir. Bununla birlikte, böyle bir grafikte naifçe birçok adımı keşfetmek gürültü ve yüksek hesaplama maliyeti getirebilir. Zorluk, modelin bu ağdaki en bilgilendirici komşulara kulak vermesini sağlarken yanıltıcı veya uzak bağlantıları görmezden gelmektir.
Modelin dikkat etmesine izin vermek
Önerilen model TNRA, bunu kullanıcı tarafında graf dikkat ağları (graph attention networks) ve öğe tarafında grafik konvolüsyonu kullanarak çözüyor. Kullanıcılar için model, etkileşimde bulundukları öğelerden başlayarak bilgi grafiği içinde çok adımlı "dalgalanmalar" (ripples) izliyor ve daha alakalı bağlantılara daha yüksek ağırlıklar atıyor. Bu dikkat mekanizması, tüm komşu düğümlerin kullanıcı profilini eşit şekilde etkilemediği anlamına geliyor; sistem yeni ilgi alanlarını tahmin etmek için hangi yolların en önemli olduğunu öğreniyor. Öğe tarafında model, ilişkili ürünler veya özellikler gibi sınırlı bir yakındaki düğüm kümesini örnekliyor ve her öğenin rafine bir portresini oluşturmak için bunların özelliklerini harmanlıyor; bunda da komşuların ilgili kullanıcı zevkleriyle ne kadar örtüştüğü yön gösteriyor.
Sistemi okumayı öğretmek
Önemli bir fark, TNRA’nın yalnızca grafik yapısına güvenmemesi. Aynı zamanda kullanıcı yorumlarındaki ve öğe açıklamalarındaki dilden öğreniyor. Metni temizleyip tokenlere ayırdıktan sonra sistem, belirli bir türe duyulan coşku veya tempoyla ilgili şikayetler gibi anlamı yakalayan kompakt vektörlere dönüştürüyor. Bu metinden türetilen vektörler, kullanıcı ve öğe için grafik tabanlı temsillerle birleştirilerek her düğüme hem yapısal bağlantılar hem de anlamsal nüans kazandırıyor. Sistem daha sonra bir kullanıcı ile bir öğeyi karşılaştırdığında, aslında yalnızca ham tıklama geçmişlerini değil, bunların bir arada oluşturduğu "hikâyeleri" karşılaştırıyor.
Yaklaşımı teste sokmak
Araştırmacılar TNRA’yı iki iyi bilinen ölçüt üzerinde değerlendirdi: ticari bir bilgi grafiğiyle zenginleştirilmiş büyük ölçekli bir kitap puanlama koleksiyonu ve MovieLens-1M film veri seti. Yöntemlerini derin öğrenme ve grafik yöntemleri kullanan güçlü birkaç temel yöntemle karşılaştırdılar. Bir kullanıcının etkileşime girdiği öğeleri dikkate almayıp görmezden geldiği öğelerden ayırt etme becerisi ve öneri listesinin üstünde ne kadar alakalı öğe yer aldığı da dahil olmak üzere birden çok ölçüde TNRA tutarlı şekilde öne çıktı. Özellikle verilerin seyrek olduğu ortamlarda puanlarında küçük ama anlamlı artışlar sağladı ve eğitim süresi ile bellek kullanımını diğer grafik tabanlı sistemlerle karşılaştırılabilir seviyede tuttu.
Günlük kullanıcılar için bunun anlamı
Basitçe söylemek gerekirse, bu çalışma öneri sistemlerinin iki fikri birleştirerek daha doğru ve dayanıklı hale gelebileceğini gösteriyor: çevrimiçi dünyayı birbirine bağlı varlıklar ağı olarak temsil etmek ve modelin kullanıcı yorumları ile açıklamalardaki "satır aralarını okumasına" izin vermek. En alakalı bağlantılara dikkatle odaklanıp metinsel anlamı harmanlayarak TNRA, açık sinyaller az olsa bile insanların muhtemelen neyi beğeneceğini daha iyi çıkarabilir. Kullanıcılar için bunun anlamı, özellikle niş zevkler ve geleneksel yöntemlerin göz ardı etme eğiliminde olduğu yeni öğeler söz konusu olduğunda, daha uygun kitap ve film önerileri ve daha az alakasız liste olabilir.
Atıf: Dong, J., Shen, Z., Luo, H. et al. Graph attention and text semantics improve personalized recommendation. Sci Rep 16, 11672 (2026). https://doi.org/10.1038/s41598-026-46737-x
Anahtar kelimeler: kişiselleştirilmiş öneri, bilgi grafiği, graf sinir ağı, metin anlambilimi, öneri sistemleri