Clear Sky Science · zh
一种用于临床大语言模型的自适应差分隐私框架,具备上下文感知噪声校准、分层预算和实时审计
为何更安全的医学人工智能至关重要
医院正转向人工智能,帮助医生起草病历并总结冗长的医疗记录,但每一行文字都可能泄露关于患者的深度个人信息。本文介绍了 PrivLLM-Guard,一种在临床文本上运行大型语言模型的方法,使其在仍然为护理提供有用信息的同时,大幅降低模型生成响应时泄露私人细节的可能性。
为临床文本量身定制的更智能隐私保护
现代语言模型在阅读和撰写医疗记录方面表现出色,但它们也可能记住并重复训练数据的片段。在医疗领域,这种风险不可接受,因为隐私法规和伦理要求对个人身份、诊断和病史给予强有力的保护。许多现有的隐私工具只是对模型的每个部分统一添加相同强度的随机噪声,这常常破坏输出质量或使系统变慢,以至于无法在床旁使用。作者认为临床人工智能需要一种更有针对性的方法,按照不同类型的医疗信息给予不同级别的保护。
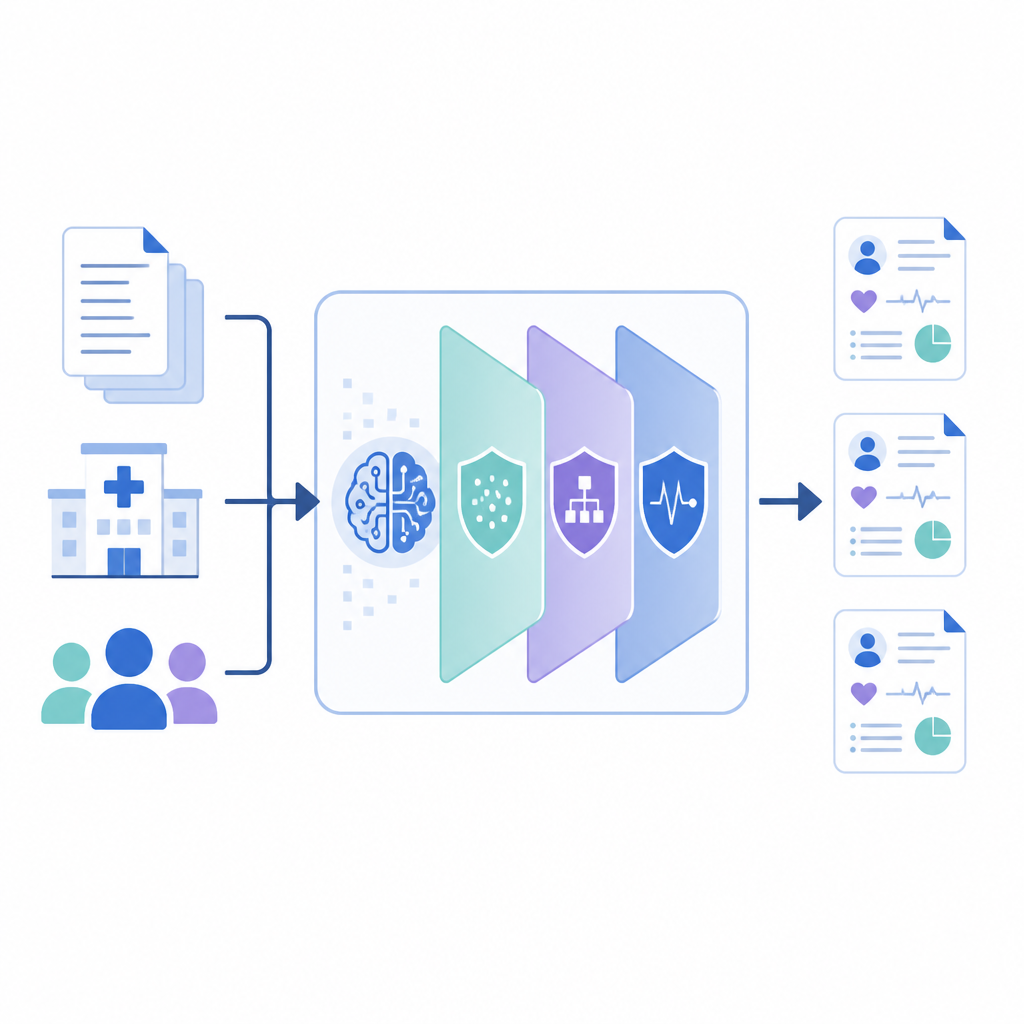
新框架的工作原理
PrivLLM-Guard 将一个强大的语言模型封装在若干协作的隐私层中。输入端,一个具备隐私感知的编码器对每个输入的内部表示进行轻微扰动,从而无法追溯到单个患者的措辞。输出端,一个专门设计的解码器控制新文本的生成,使用随机化的选择来限制其与任何单一记录的相似度。在这两端之间,系统跟踪已消耗的“隐私预算”,类似计量器,并将该预算分配到各个组件,使得诸如姓名或日期等最敏感的信息获得比常见药物名称等一般医学事实更强的保护。
实时根据风险自适应调整
一个关键创新是 PrivLLM-Guard 不把每次请求都视为相同。一个自适应噪声模块分析输入文本以判断其隐私敏感性:例如,它是常规摘要还是可能指向单一个人的罕见病况。基于该评估以及过去的行为,系统调整向模型内部信号添加的随机变异量。与此同时,实时隐私监测器监视模型生成的每个标记,估计其泄露敏感信息的概率。如果该风险超过预设阈值,系统会立即作出反应,通过增强保护甚至中止响应来应对,而不是事后等待人工审查。
在准确性与速度之间保持平衡
只有在生成的记录仍能帮助临床医生时,隐私保护才有意义。作者在来自重症监护、普通住院护理和挑战性数据集的数百万条去标识化记录上测试了 PrivLLM-Guard。在非常严格的隐私设置下,该框架生成的摘要和报告在与参考文本的接近度上优于若干竞争的隐私保护模型,同时保留了重要的医学术语和关系。审阅这些输出的肿瘤学、心脏病学、急诊医学和放射学等专业医生认为文本在临床上既准确又可读。系统在实时使用方面也保持了足够的速度,以亚秒级处理典型笔记长度,并具有适中的内存需求。
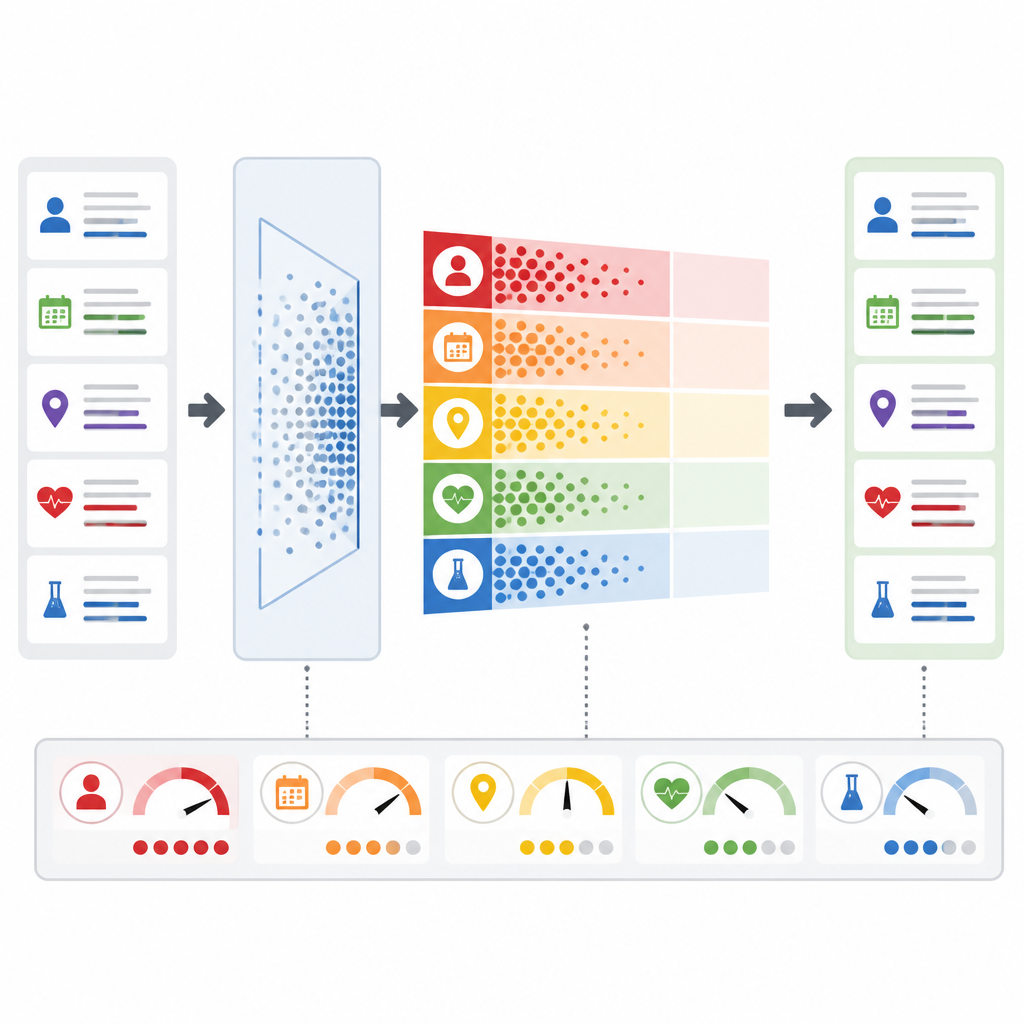
对患者和临床医生意味着什么
简单来说,PrivLLM-Guard 表明医院可以使用强大的语言模型来减少文书工作并澄清复杂记录,而不是被动地信任隐私会自发得到保障。通过持续衡量风险、根据信息类型定制保护并在数学上证明隐私保证,该框架为既尊重医疗质量又保护患者机密性的临床人工智能工具提供了一条可行路径。尽管在罕见疾病、其他语言以及图像等混合数据类型方面仍面临挑战,这项工作表明更安全、更透明的基于文本的医疗助手是可实现的。
引用: Alghamdi, A.D. An adaptive differential privacy framework for clinical llms with context-aware noise calibration, hierarchical budgeting, and real-time auditing. Sci Rep 16, 15781 (2026). https://doi.org/10.1038/s41598-026-45883-6
关键词: 临床语言模型, 医疗数据隐私, 差分隐私, 医疗文本摘要, 实时临床人工智能