Clear Sky Science · sv
En adaptiv differentialprivacy‑ramverk för kliniska LLM med kontextmedveten bruskalibrering, hierarkisk budgetering och realtidsrevision
Varför säkrare medicinsk AI är viktig
Sjukhus vänder sig till artificiell intelligens för att hjälpa läkare skriva anteckningar och sammanfatta långa journaler, men varje textlinje kan avslöja något djupt personligt om en patient. Denna artikel introducerar PrivLLM‑Guard, en metod för att köra stora språkmodeller på klinisk text så att de förblir användbara för vården samtidigt som sannolikheten att privata detaljer läcker ut genom modellens svar minskas kraftigt.
Smartare integritet för klinisk text
Moderna språkmodeller är mycket duktiga på att läsa och skriva medicinska anteckningar, men de kan också memorera och upprepa fragment från sin träningsdata. Inom vården är den risken oacceptabel eftersom lagar och etik kräver starkt skydd för personers identiteter, diagnoser och historik. Många befintliga integritetsverktyg tillsätter helt enkelt samma nivå av slumpmässigt brus överallt i en modell, vilket ofta förstör resultatkvaliteten eller saktar ner systemet så mycket att det inte kan användas vid patientens sida. Författarna menar att klinisk AI behöver en mer skräddarsydd strategi som behandlar olika slags medicinsk information med olika grad av omsorg.
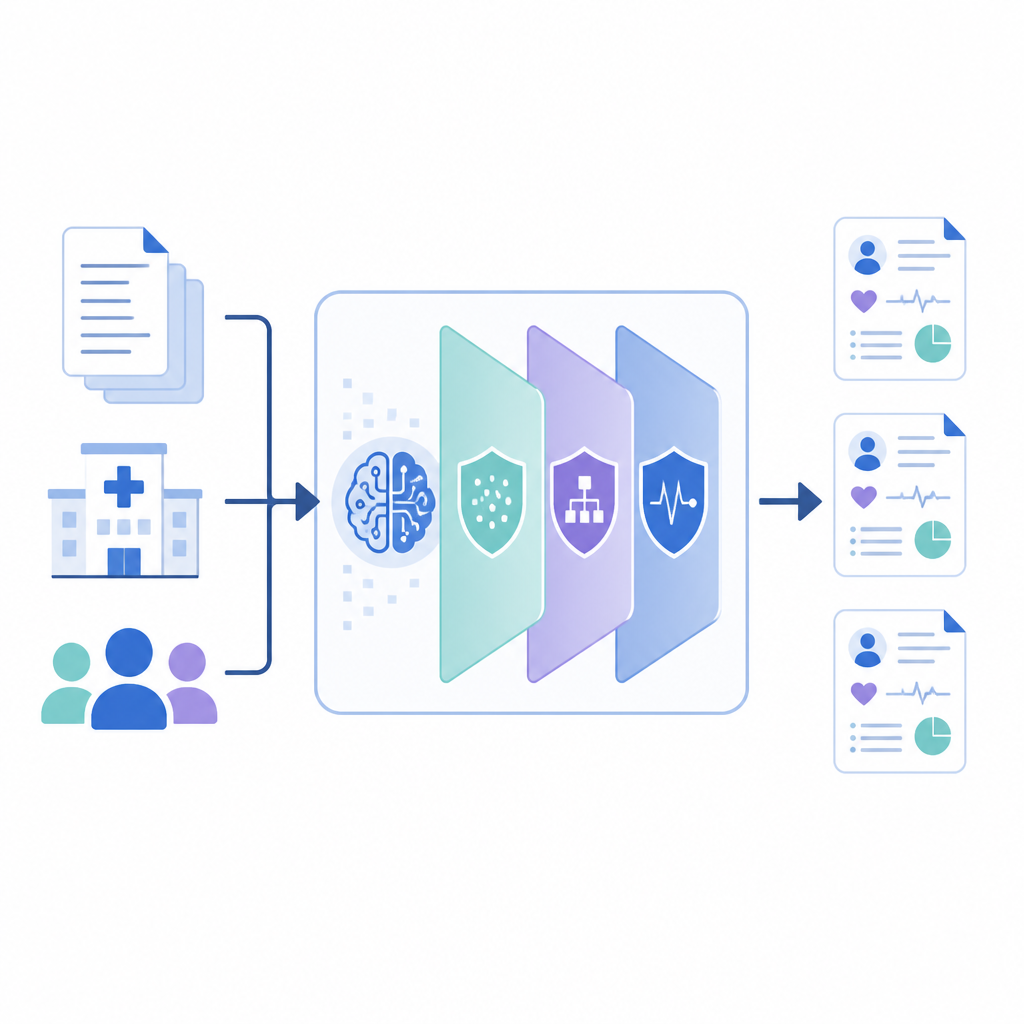
Hur det nya ramverket fungerar
PrivLLM‑Guard omsluter en kraftfull språkmodell i flera samverkande integritetslager. På vägen in stör en integritetsmedveten kodare svagt den interna representationen av varje indata, så att ingen enskild patients formulering kan spåras. På vägen ut kontrollerar en särskilt utformad avkodare hur ny text genereras, med randomiserade val som begränsar hur nära den kan återge någon enskild journal. Mellan dessa ändar håller systemet reda på hur mycket ”integritetsbudget” som har förbrukats, ungefär som en mätare, och fördelar den budgeten över komponenterna så att de mest känsliga uppgifterna, såsom namn eller datum, får starkare skydd än allmänna medicinska fakta som vanliga läkemedelsnamn.
Anpassning till risk i realtid
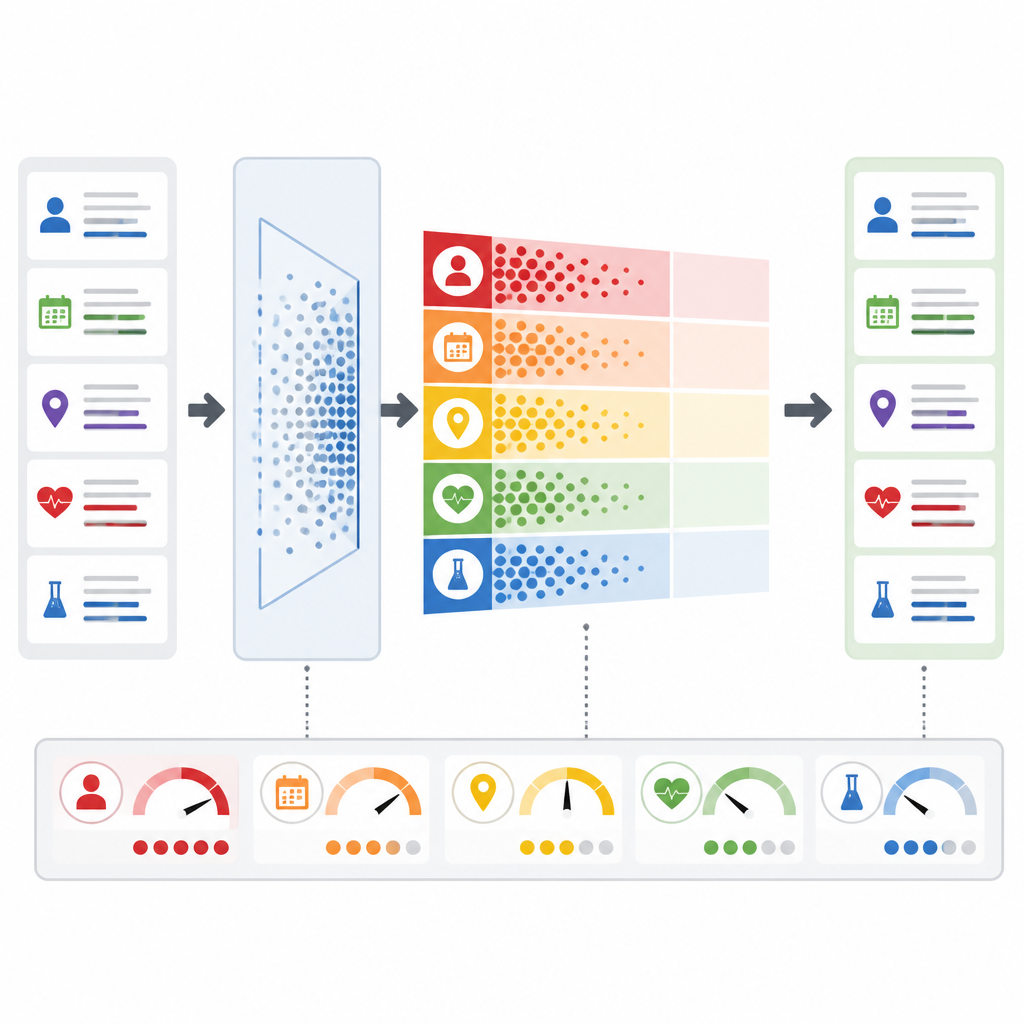
En viktig innovation är att PrivLLM‑Guard inte behandlar varje förfrågan likadant. En adaptiv brusmodul analyserar inkommande text för att bedöma hur privat den är: till exempel om det rör sig om en rutinmässig sammanfattning eller ett sällsynt tillstånd som kan identifiera en enskild person. Baserat på den bedömningen och på tidigare beteende justerar systemet hur mycket slumpmässig variation det lägger till modellens interna signaler. Samtidigt övervakar en realtidsintegritetsmonitor varje token som modellen producerar och uppskattar chansen att den avslöjar något känsligt. Om risken överstiger en förinställd gräns reagerar systemet omedelbart genom att öka skyddet eller till och med avbryta svaret, i stället för att vänta på mänsklig granskning i efterhand.
Att hålla noggrannhet och hastighet i balans
Att skydda integriteten är bara användbart om de resulterande anteckningarna fortfarande hjälper kliniker. Författarna testade PrivLLM‑Guard på miljontals avidentifierade journaler från intensivvård, allmän sjukhusvård och utmaningsdatamängder. Under mycket strikta integritetsinställningar producerade ramverket sammanfattningar och genererade rapporter som låg närmare referenstexter än flera konkurrerande integritetsbevarande modeller, samtidigt som viktiga medicinska termer och samband behölls. Läkare som granskade utdata inom specialiteter som onkologi, kardiologi, akutsjukvård och radiologi bedömde texterna som både kliniskt korrekta och läsbara. Systemet förblev också tillräckligt snabbt för realtidsbruk och hanterade typiska anteckningslängder på en bråkdel av en sekund med måttliga minnesbehov.
Vad detta betyder för patienter och kliniker
Enkelt uttryckt visar PrivLLM‑Guard att sjukhus kan använda kraftfulla språkmodeller för att minska administrationen och förtydliga komplexa journaler utan att förlita sig på att integriteten sköter sig själv. Genom att kontinuerligt mäta risk, anpassa skyddet efter informationstyp och bevisa integritetsgarantier matematiskt erbjuder ramverket en väg mot kliniska AI‑verktyg som respekterar både medicinsk kvalitet och patientsekretess. Samtidigt kvarstår utmaningar för sällsynta sjukdomar, andra språk och blandade datatyper som bilder, men arbetet antyder att säkrare, mer transparenta textbaserade assistenter i vården är inom räckhåll.
Citering: Alghamdi, A.D. An adaptive differential privacy framework for clinical llms with context-aware noise calibration, hierarchical budgeting, and real-time auditing. Sci Rep 16, 15781 (2026). https://doi.org/10.1038/s41598-026-45883-6
Nyckelord: kliniska språkmodeller, medicinsk dataintegritet, differential privacy, sammanfattning av vårdtexter, realtids klinisk AI